[[{“value”:”

Multimodal large language models (MLLMs) rapidly evolve in artificial intelligence, integrating vision and language processing to enhance comprehension and interaction across diverse data types. These models excel in tasks like image recognition and natural language understanding by combining visual and textual data processing into one coherent framework. This integrated approach allows MLLMs to perform highly on tasks requiring multimodal inputs, proving valuable in fields such as autonomous navigation, medical imaging, and remote sensing, where simultaneous visual and textual data analysis is essential.
Despite their advantages, MLLMs face substantial limitations due to their computational intensity and extensive parameter requirements, limiting their adaptability on devices with constrained resources. Many MLLMs rely on general-purpose training data, often derived from internet sources, which impacts their performance when applied to specialized domains. This reliance on vast datasets and large-scale computing power creates significant barriers to deploying these models for tasks requiring nuanced, domain-specific understanding. These challenges are amplified in fields like remote sensing or autonomous driving, where domain adaptation is crucial but complex and costly.
Existing MLLMs typically incorporate vision encoders like CLIP, designed to align vision data with language models for a cohesive multimodal framework. However, these models often encounter limitations in specialized domains due to a lack of comprehensive visual knowledge across these fields. Most current MLLMs use pre-trained vision encoders aligned with large language models, which require substantial adjustments to their architecture and training schedules when applied to different domains. This process, though effective, can be inefficient and makes deploying these models on smaller devices challenging, as their reliance on internet-domain data limits their ability to adapt seamlessly to domain-specific tasks without extensive reconfiguration.
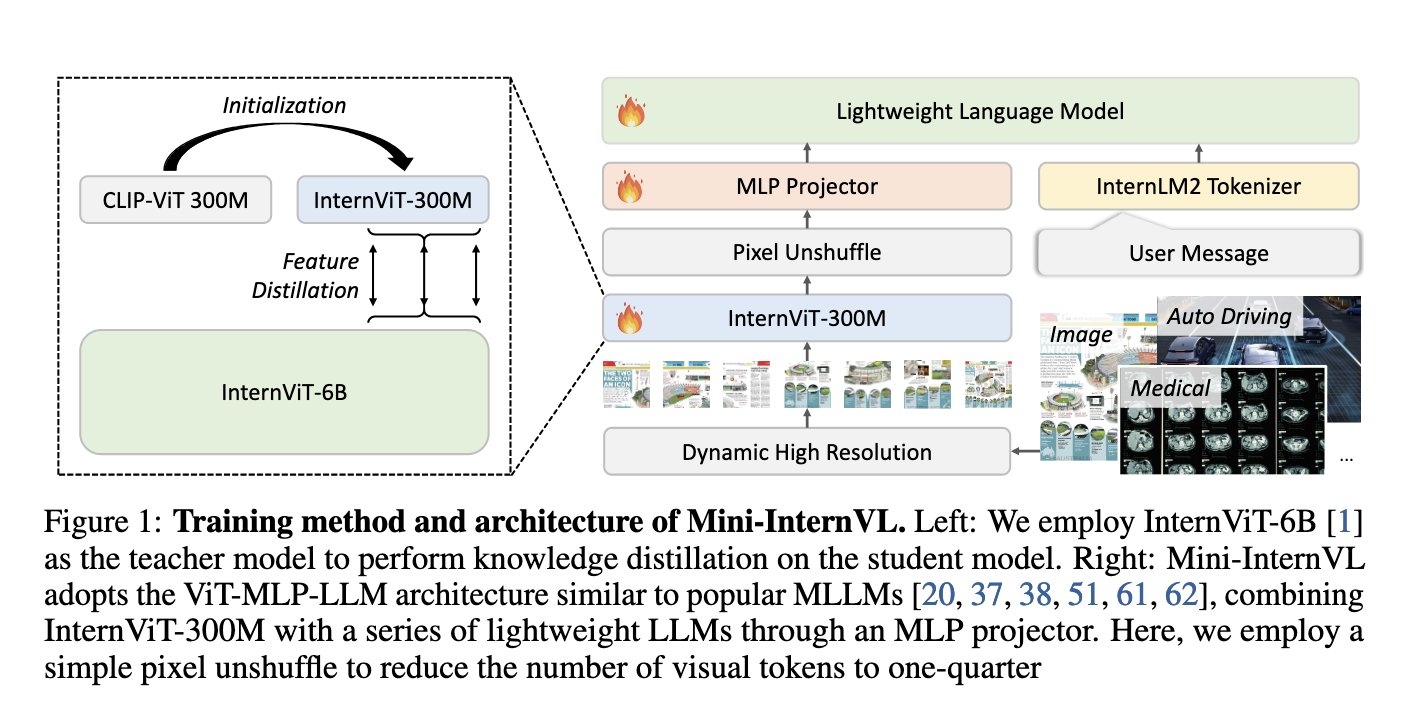
Researchers from Shanghai AI Laboratory, Tsinghua University, Nanjing University, Fudan University, The Chinese University of Hong Kong, SenseTime Research and Shanghai Jiao Tong University have introduced Mini-InternVL, a series of lightweight MLLMs with parameters ranging from 1B to 4B to deliver efficient multimodal understanding across various domains. Mini-InternVL seeks to maintain 90% of the performance of larger multimodal models using only 5% of the parameters, making it both resource-effective and accessible on consumer-grade devices. The research team designed Mini-InternVL as a pocket-sized solution adaptable to tasks such as autonomous driving, medical imaging, and remote sensing while offering lower computational overhead than traditional MLLMs. By creating a unified adaptation framework, Mini-InternVL supports effective model transfer across domains, promoting accessibility and applicability across specialized fields.
Mini-InternVL employs a robust vision encoder called InternViT-300M, distilled from the larger InternViT-6B model. This vision encoder enhances the model’s representational capacity, allowing for effective cross-domain transfer with reduced resource requirements. The Mini-InternVL series comprises three model variants: Mini-InternVL-1B, Mini-InternVL-2B, and Mini-InternVL-4B, with parameter counts of 1 billion, 2 billion, and 4 billion, respectively. Each variant is connected to pre-trained language models like Qwen2-0.5B, InternLM2-1.8B, and Phi-3-Mini, allowing for flexible deployment. Training occurs in two stages: first, through language-image alignment, where the model is pre-trained on extensive datasets across various tasks, ensuring robust alignment of visual and textual elements. Second, the model undergoes visual instruction tuning, which involves training on datasets specific to multimodal tasks such as image captioning, chart interpretation, and visual question answering. The diverse range of tasks during this multi-stage training enhances Mini-InternVL’s adaptability and performance in real-world scenarios.

Mini-InternVL demonstrates significant performance achievements on various multimodal benchmarks, achieving up to 90% of the performance of larger models like InternVL2-Llama3-76B with only 5% of its parameters. Specifically, Mini-InternVL-4B performed well on general multimodal benchmarks, scoring 78.9 on the MMBench and 81.5 on ChartQA, both essential benchmarks for vision-language tasks. The model also performed competitively on domain-specific tasks, matching or even outperforming some proprietary models in accuracy and efficiency. For instance, in the autonomous driving domain, Mini-InternVL-4B achieved an accuracy score comparable to models using significantly more resources. Furthermore, Mini-InternVL models excelled in medical imaging and remote sensing, demonstrating strong generalization capabilities with minimal fine-tuning. The Mini-InternVL-4B model achieved a final average score of 72.8 across multiple benchmarks, highlighting its strength as a lightweight, high-performing model capable of transferring seamlessly across specialized fields without excessive resource demands.
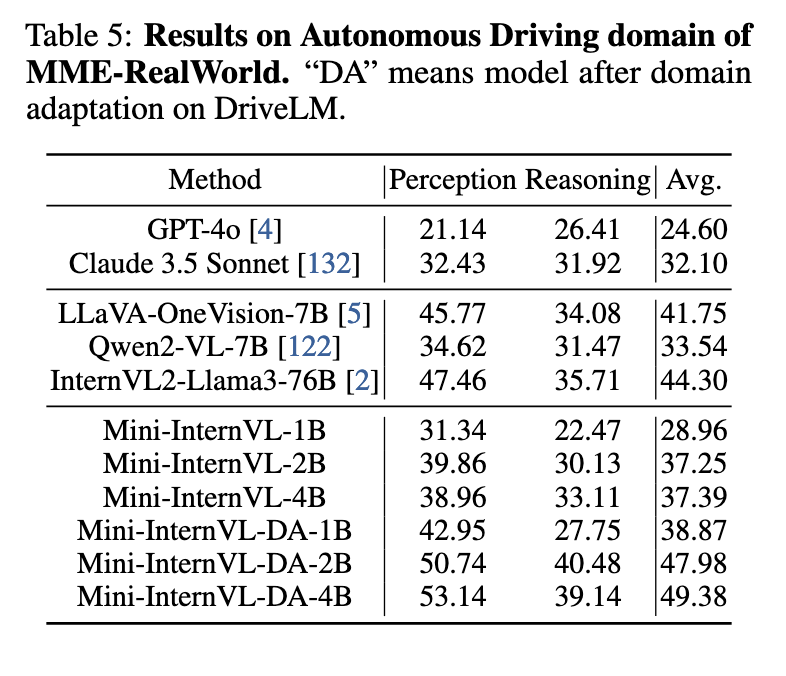
The researchers successfully addressed the high computational barriers in multimodal model deployment by introducing Mini-InternVL. This model demonstrates that efficient architecture and training methods can achieve competitive performance levels while significantly reducing resource requirements. By employing a unified adaptation framework and a robust vision encoder, Mini-InternVL provides a scalable solution for specialized applications in resource-limited environments, advancing the practical applicability of multimodal large language models in specialized fields.
Check out the Paper and Model Card on Hugging Face. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Trending] LLMWare Introduces Model Depot: An Extensive Collection of Small Language Models (SLMs) for Intel PCs
The post Mini-InternVL: A Series of Multimodal Large Language Models (MLLMs) 1B to 4B, Achieving 90% of the Performance with Only 5% of the Parameters appeared first on MarkTechPost.
“}]] [[{“value”:”Multimodal large language models (MLLMs) rapidly evolve in artificial intelligence, integrating vision and language processing to enhance comprehension and interaction across diverse data types. These models excel in tasks like image recognition and natural language understanding by combining visual and textual data processing into one coherent framework. This integrated approach allows MLLMs to perform highly
The post Mini-InternVL: A Series of Multimodal Large Language Models (MLLMs) 1B to 4B, Achieving 90% of the Performance with Only 5% of the Parameters appeared first on MarkTechPost.”}]] Read More AI Paper Summary, AI Shorts, Applications, Artificial Intelligence, Computer Vision, Editors Pick, New Releases, Staff, Tech News, Technology