[[{“value”:”

Multimodal Retrieval Augmented Generation (RAG) technology has opened new possibilities for artificial intelligence (AI) applications in manufacturing, engineering, and maintenance industries. These fields rely heavily on documents that combine complex text and images, including manuals, technical diagrams, and schematics. AI systems capable of interpreting both text and visuals have the potential to support intricate, industry-specific tasks, but such tasks present unique challenges. Effective multimodal data integration can improve task accuracy and efficiency in contexts where visuals are essential to understanding complex instructions or configurations.
The AI system’s ability to provide accurate, relevant answers using text and image-based information from documents is a unique challenge in industrial settings. Traditional large language models (LLMs) often need more domain-specific knowledge and face limitations in handling multimodal inputs, leading to a tendency for ‘hallucinations’ or inaccuracies in the responses generated. For instance, in question-answering tasks requiring both text and images, a text-only RAG model may fail to interpret key visual elements like device schematics or operational layouts, which are common in technical fields. This underscores the need for a solution that not only retrieves text data but also effectively integrates image data to improve the relevance and accuracy of AI-driven insights.
Current retrieval and generation techniques often focus on either text or images independently, resulting in gaps when handling documents that require both types of input. Some text-only models attempt to improve relevance by accessing large datasets, while image-only approaches rely on techniques like optical character recognition or direct embeddings to interpret visuals. However, these methods are limited in supporting industrial use cases where the integration of both text and image is crucial. Multimodal systems that can retrieve and process multiple input types have emerged as an important advancement to bridge these gaps. Still, optimizing such systems for industrial settings needs to be explored.

Researchers at LMU Munich, in a collaborative effort with Siemens, have developed a multimodal RAG system specifically designed to address these challenges within industrial environments. Their proposed solution incorporates two multimodal LLMs—GPT-4 Vision and LLaVA—and uses two distinct strategies to handle image data: multimodal embeddings and image-based textual summaries. These strategies allow the system to not only retrieve relevant images based on textual queries but also to provide more contextually accurate responses by leveraging both modalities. The multimodal embedding approach, utilizing CLIP, aligns text and image data in a shared vector space, whereas the image-summary approach converts visuals into descriptive text stored alongside other textual data, ensuring that both types of information are available for synthesis.
The multimodal RAG system employs these strategies to maximize accuracy in retrieving and interpreting data. In the text-only RAG setting, text from industrial documents is embedded using a vector-based model and matched to the most relevant sections for response generation. For image-only RAG, researchers employed CLIP to embed images alongside textual questions, making it possible to compute cross-modal similarities and locate the most relevant images. Meanwhile, the combined RAG approach leverages both modalities, creating a more integrated retrieval process. The image-summary technique processes images into concise textual summaries, facilitating retrieval while retaining the original visuals for answer synthesis. Each approach was carefully designed to optimize the RAG system’s performance, ensuring the availability of both text and images for the LLM to generate a comprehensive response.
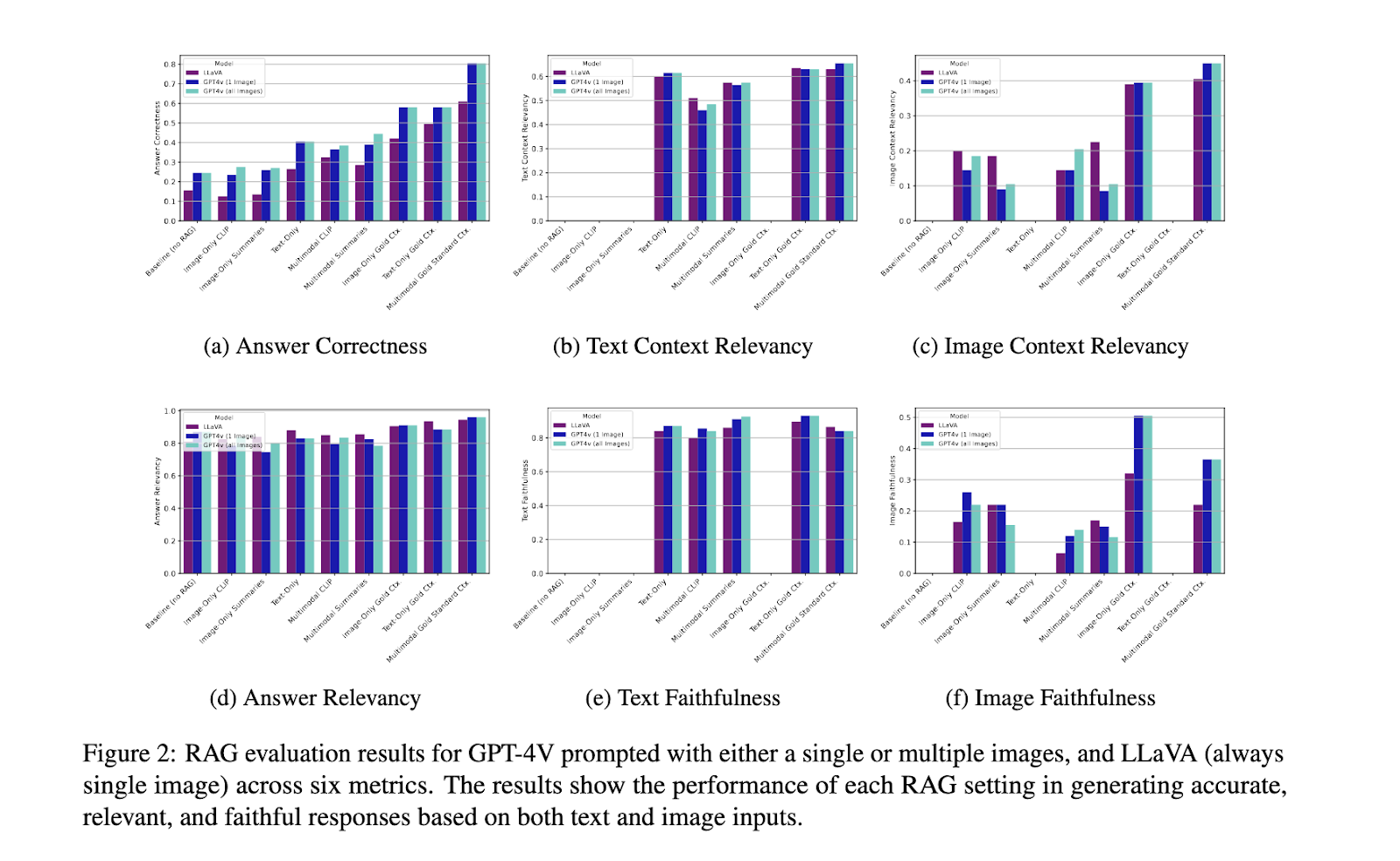
The performance of the proposed multimodal RAG system demonstrated substantial improvements, particularly in its capacity to handle complex industrial queries. Results indicated that the multimodal approach achieved significantly higher accuracy than text-only or image-only RAG setups, with combined approaches showing distinct advantages. For instance, accuracy increased by nearly 80% when images were included alongside text in the retrieval process, compared to text-only accuracy rates. Furthermore, the image-summary method proved particularly effective, surpassing the multimodal embedding technique in contextual relevance. The system’s performance was measured across six key evaluation metrics: answer accuracy and contextual alignment. The results showed that image summaries offered enhanced flexibility and potential for refining the retrieval and generation components. Further, the system faced challenges in image retrieval quality, with further improvements needed for fully optimized multimodal RAG.
The research team’s work demonstrates that the integration of multimodal RAG for industrial applications can significantly enhance AI performance in fields requiring visual and textual interpretation. By addressing the limitations of text-only systems and introducing innovative methods for image processing, the researchers have provided a framework that supports more accurate and contextually appropriate answers to complex, multimodal queries. The results underscore the potential of multimodal RAG as a critical tool in AI-driven industrial applications, particularly as advancements in image retrieval and processing continue. This potential opens up exciting possibilities for the future of the field, inspiring further research and development in this area.
Check out the Paper.. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Trending] LLMWare Introduces Model Depot: An Extensive Collection of Small Language Models (SLMs) for Intel PCs
The post This AI Paper Explores New Ways to Utilize and Optimize Multimodal RAG System for Industrial Applications appeared first on MarkTechPost.
“}]] [[{“value”:”Multimodal Retrieval Augmented Generation (RAG) technology has opened new possibilities for artificial intelligence (AI) applications in manufacturing, engineering, and maintenance industries. These fields rely heavily on documents that combine complex text and images, including manuals, technical diagrams, and schematics. AI systems capable of interpreting both text and visuals have the potential to support intricate, industry-specific
The post This AI Paper Explores New Ways to Utilize and Optimize Multimodal RAG System for Industrial Applications appeared first on MarkTechPost.”}]] Read More AI Paper Summary, AI Shorts, Applications, Artificial Intelligence, Editors Pick, Language Model, Machine Learning, Staff, Tech News, Technology