[[{“value”:”

Recent advancements in Large Language Models (LLMs) have demonstrated exceptional natural language understanding and generation capabilities. Research has explored the unexpected abilities of LLMs beyond their primary training task of text prediction. These models have shown promise in function calling for software APIs, supported by the launch of GPT-4 plugin features. Integrated tools include web browsers, translation systems, Dialogue State Tracking (DST), and robotics. While LLMs show promising results in general complex reasoning, they still face challenges in mathematical problem-solving and logical capacities. To address this, researchers have proposed techniques like function calls, which allow LLMs to execute provided functions and utilize their outputs to assist in various task completion. These functions vary from basic tools like calculators that perform arithmetic operations to more advanced methods. However, concentrating on specific tasks using only a small portion of available APIs highlights the inefficiency of relying solely on large models, which require major computational power for both training and inference and because of the expensive cost of training. This situation calls for creating smaller, task-specific LLMs that maintain core functionality while reducing operational costs. While promising, the trend toward smaller models introduces new challenges.
Current methods involve using large-scale LLMs for reasoning tasks, which are resource-intensive and costly. Due to their generalized nature, these models often struggle with specific logical and mathematical problem-solving.
The proposed research method introduces a novel framework for training smaller LLMs in function calling, focusing on specific reasoning tasks. This approach employs an agent that queries the LLM by injecting descriptions and examples of usable functions into the prompt, creating a dataset of correct and incorrect reasoning chain completions.
To address the drawbacks of oversized LLMs, which incur excessive training and inference costs, a group of researchers introduced a novel framework to train smaller language models starting from the function-calling abilities of large models for specific logical and mathematical reasoning tasks. Given a problem and a set of useful functions for its solution, this framework involves an agent that queries a large-scale LLM by injecting function descriptions and examples into the prompt and managing the proper function calls needed to find the solution, all in a step-by-step reasoning chain. This procedure is used to create a dataset with correct and incorrect completions. The generated dataset then trains a smaller model using a Reinforcement Learning from Human Feedback (RLHF) approach, known as Direct Preference Optimization (DPO). We present this methodology tested on two reasoning tasks, First-Order Logic (FOL) and math, using a custom-built set of FOL problems inspired by the HuggingFace dataset.

The proposed framework’s pipeline comprises four stages: first, defining tasks and problems to assess the abilities of large language models (LLMs) in various reasoning domains. Next, functions specific to each task are set up, allowing the LLM to solve reasoning steps, manage the chain flow, and verify results. A pre-trained, large-scale LLM is then chosen to generate a dataset of correct and incorrect completions using a chain-of-thought prompting approach. Finally, a smaller LLM model is fine-tuned using the Direct Policy Optimization (DPO) algorithm on the created dataset. Experimentation involved testing the model on first-order logic (FOL) and mathematical problems, with results generated using an agent-based library, Microchain, which facilitates LLM querying with predefined functions to create a chain-of-thought dataset.
Data augmentation was conducted to extend the dataset, and fine-tuning was performed on Mistral-7B using a single GPU. Performance metrics demonstrated the model’s accuracy improvement in FOL tasks and moderate gains in mathematical tasks, with statistical significance confirmed through a Wilcoxon test.
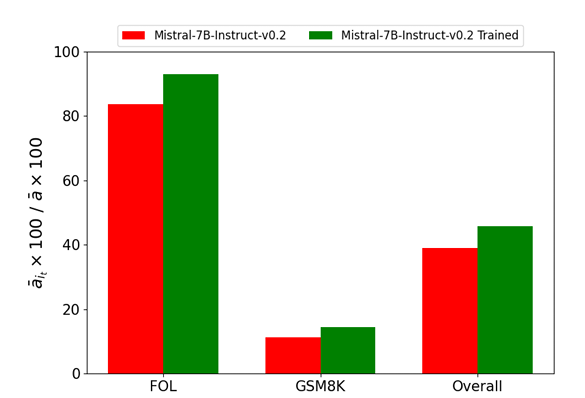
In conclusion, the researchers proposed a new framework for improving the function-calling abilities of small-scale LLMs, focusing on specific logical and mathematical reasoning tasks. This method reduces the need for large models and boosts the performance on logical and math-related tasks. The experimental results demonstrate significant improvements in the performance of the small-scale model on FOL tasks, achieving near-perfect accuracy in most cases. In future work, there is great scope to explore the application of the introduced framework to a broader range of reasoning tasks and function types.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Trending] LLMWare Introduces Model Depot: An Extensive Collection of Small Language Models (SLMs) for Intel PCs
The post Efficient Function Calling in Small-Scale LLMs: A Game-Changer for AI Reasoning Tasks appeared first on MarkTechPost.
“}]] [[{“value”:”Recent advancements in Large Language Models (LLMs) have demonstrated exceptional natural language understanding and generation capabilities. Research has explored the unexpected abilities of LLMs beyond their primary training task of text prediction. These models have shown promise in function calling for software APIs, supported by the launch of GPT-4 plugin features. Integrated tools include web
The post Efficient Function Calling in Small-Scale LLMs: A Game-Changer for AI Reasoning Tasks appeared first on MarkTechPost.”}]] Read More AI Paper Summary, AI Shorts, Applications, Artificial Intelligence, Editors Pick, Staff, Tech News, Technology