[[{“value”:”

Knowledge distillation (KD) is a machine learning technique focused on transferring knowledge from a large, complex model (teacher) to a smaller, more efficient one (student). This approach is used extensively to reduce large language models’ computational load and resource requirements while retaining as much of their performance as possible. Using this method, researchers can develop smaller practical models for real-time applications while preserving essential performance attributes.
In KD, a central challenge is bridging the gap between the data distributions used for training and those encountered during inference. Conventional approaches like supervised KD rely on a static set of data, which can lead to a distribution mismatch, causing the model to underperform when faced with real-world inputs. On-policy KD, another technique, trains the student on generated outputs. However, this can introduce low-quality samples that may not align with the teacher model’s high standards, ultimately resulting in flawed feedback. This limitation hampers the effectiveness of KD as it fails to provide consistent guidance to the student model across different learning stages.
To tackle these challenges, researchers have developed multiple KD methods. Supervised KD, for example, uses a predetermined dataset to train the student, but this fixed approach does not accommodate changes in the student’s output distribution at inference time. On-policy KD attempts to adapt to the student’s evolving outputs by incorporating its self-generated samples during training, aligning the training distribution more closely with inference. However, on-policy KD needs help with low-quality data, as the early training phases often involve out-of-distribution samples that fail to represent the teacher’s ideal predictions. As a result, both methods need help consistently enhancing the student model’s performance across various tasks and conditions.

Researchers from UC Santa Barbara, Google Cloud AI Research, Google DeepMind, and CMU have introduced Speculative Knowledge Distillation (SKD), an innovative approach that employs a dynamic, interleaved sampling technique. SKD blends elements of both supervised and on-policy KD. The student model proposes tokens, while the teacher model selectively replaces poorly ranked tokens based on their distribution. This cooperative process ensures the training data remains high-quality and relevant to the student’s inference-time distribution. Using SKD, the researchers facilitate adaptive knowledge transfer that helps the student model continuously align with the teacher’s standards while allowing flexibility in the student’s outputs.
In greater detail, SKD’s approach incorporates a token interleaving mechanism where the student and teacher models interactively propose and refine tokens during training. At the beginning of training, the teacher model substantially replaces many of the student’s initial low-quality proposals, resembling supervised KD. However, as the student model improves, the training gradually shifts towards on-policy KD, where more student tokens are accepted without modification. SKD’s design also includes a filtering criterion based on top-K sampling, where only student tokens within the teacher’s highest probability predictions are accepted. This balance allows SKD to avoid the pitfalls of traditional supervised and on-policy KD, resulting in a more adaptive and efficient knowledge transfer that does not depend heavily on any fixed distribution.

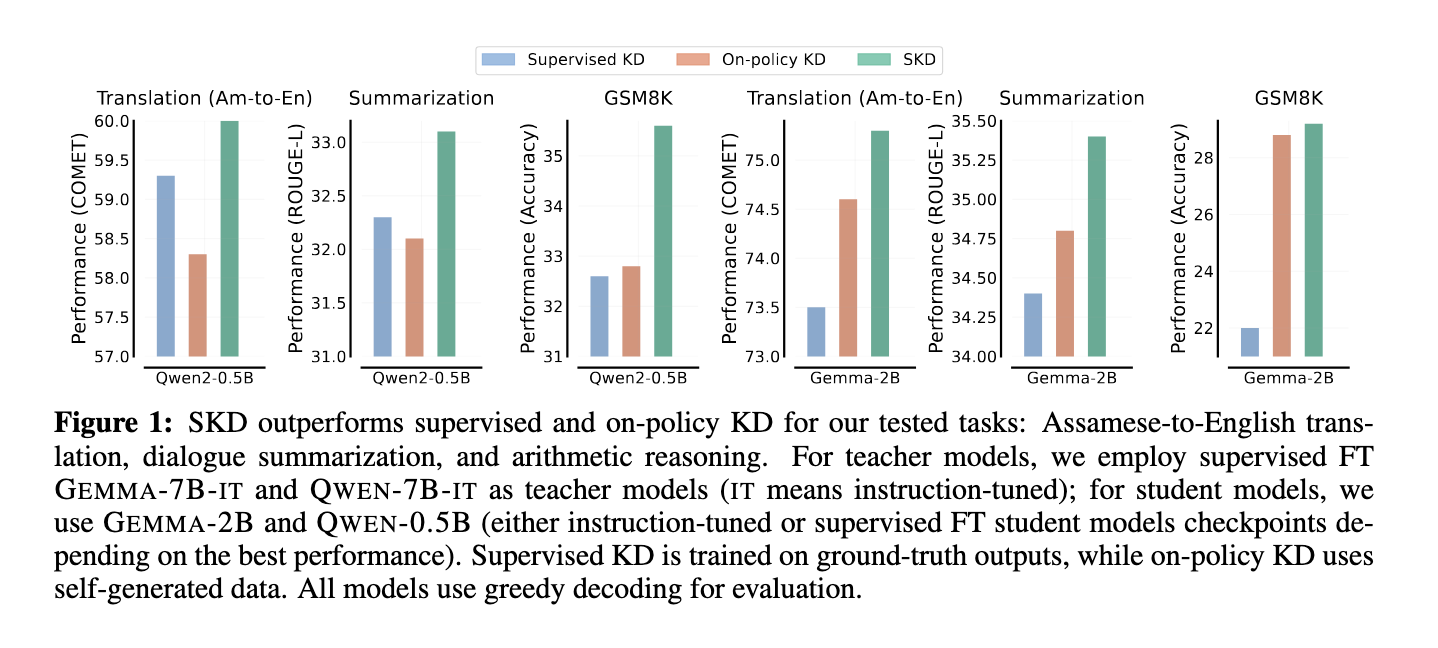
The researchers validated SKD’s effectiveness by testing it across various natural language processing (NLP) tasks, demonstrating substantial improvements in accuracy and adaptability over previous methods. For instance, in a low-resource translation task, SKD achieved a 41.8% improvement over traditional KD approaches, significantly enhancing the quality of Assamese-to-English translations. In summarization tasks, SKD outperformed other methods with a 230% increase, and in arithmetic reasoning, SKD demonstrated a 160% improvement. These results underscore SKD’s robustness across tasks with different data requirements, model types, and initializations, reinforcing its viability as a versatile solution for real-time, resource-constrained AI applications. Furthermore, testing with an instruction-following dataset yielded gains of 198% and 360% in specialized math tasks, highlighting SKD’s exceptional adaptability across task-specific and task-agnostic scenarios.
In addition to superior performance metrics, SKD exhibits resilience across different model initializations and data sizes, proving effective even in low-data environments where only 100 samples are available. Traditional KD approaches often fail in such settings due to overfitting, but SKD’s end-to-end approach effectively bypasses this issue by dynamically adjusting the guidance provided by the teacher. Further, by generating high-quality training data that aligns closely with the student’s inference-time needs, SKD achieves a seamless balance between supervised and on-policy KD, instilling confidence in its adaptability.
In summary, Speculative Knowledge Distillation presents a substantial advance in KD by addressing distribution mismatches and poor-quality student data that previously limited KD effectiveness. By allowing a more dynamic teacher-student interaction and adapting to the evolving quality of student proposals, SKD provides a more reliable and efficient means of distilling knowledge. Its ability to outperform traditional methods consistently across various domains highlights its potential to drive significant improvements in the efficiency and scalability of AI applications, particularly in resource-constrained settings.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Sponsorship Opportunity with us] Promote Your Research/Product/Webinar with 1Million+ Monthly Readers and 500k+ Community Members
The post This AI Paper from Google Research Introduces Speculative Knowledge Distillation: A Novel AI Approach to Bridging the Gap Between Teacher and Student Models appeared first on MarkTechPost.
“}]] [[{“value”:”Knowledge distillation (KD) is a machine learning technique focused on transferring knowledge from a large, complex model (teacher) to a smaller, more efficient one (student). This approach is used extensively to reduce large language models’ computational load and resource requirements while retaining as much of their performance as possible. Using this method, researchers can develop
The post This AI Paper from Google Research Introduces Speculative Knowledge Distillation: A Novel AI Approach to Bridging the Gap Between Teacher and Student Models appeared first on MarkTechPost.”}]] Read More AI Paper Summary, AI Shorts, Applications, Artificial Intelligence, Editors Pick, Machine Learning, Staff, Tech News, Technology