[[{“value”:”

A fundamental challenge in studying EEG-to-Text models is ensuring that the models learn from EEG inputs and not just memorize text patterns. In many reports in the literature where great results have been obtained on brain signal translation to text, there seems to be reliance on implicit teacher-forcing evaluation methods that could artificially inflate performance metrics. This procedure introduces the actual target sequences at every step, masking any deficits in the real learning abilities of the model. Current research is also missing an important benchmark: testing how the models do on purely noise inputs. This kind of baseline is essential to distinguish between models that are genuinely decoding information from the EEG signal and those that simply rely on memorized patterns in data. This challenge must be addressed to develop practical applications of accurate and reliable EEG-to-Text systems, especially for people with disabilities since they rely on such models for communication.
Most current approaches use encoder-decoder architectures with pre-trained models such as BART, PEGASUS, and T5. The model leverages properties from word embeddings and transformers to map EEG signals to text, where they can then be evaluated in terms of BLEU and ROUGE. However, teacher forcing significantly inflated the scores of the performances and concealed what the model could or could not do. Additionally, because baselines using noise were not used in tests, it is not even known whether these models could actually obtain any meaningful information from the EEG signals or merely just reproduce memorized sequences. This limitation limits model reliability and prevents their more accurate usage in real-world applications, thus emphasizing the need for evaluation methods that will more accurately reflect the models’ learning efficacy.
The researchers from Kyung Hee University and the Australian Artificial Intelligence Institute introduce a more robust assessment framework to address the foreseen issues. This methodology presents four experimental scenarios, which are training and testing on EEG data, training and testing with random noise only, training with EEG but testing on noise, and training on noise but testing on the data of EEG. In contrast between performance through these scenarios, investigators can determine whether models learn meaningful information that lies in the EEG signal or memorize. Furthermore, the methodology employs a range of pre-trained transformer-based models to evaluate the effects of different architectures on model performance. This new strategy allows for much more distinct and trustworthy testing for the EEG-to-Text model, which is now placed at a new level.
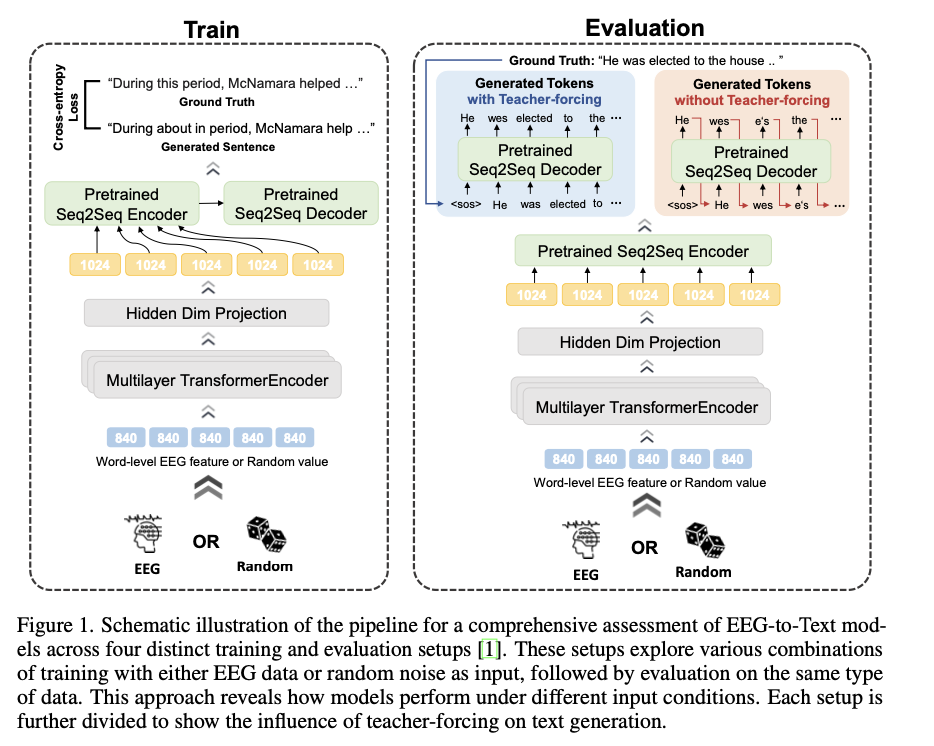
The experiments relied on the following two datasets: ZuCo 1.0 and ZuCo 2.0 – EEG data recorded during the natural reading process that occurs through a series of movie reviews and Wikipedia articles. EEG signals were processed to get 840 features per word that were divided according to eye fixations. In addition, eight specific frequency bands (theta1, theta2, alpha1, alpha2, beta1, beta2, gamma1, and gamma2) were used to ensure the comprehensive feature extraction. The data split was divided into 80% for training, 10% for development, and 10% for testing. The training was conducted for 30 epochs over Nvidia RTX 4090 GPUs, and performance metrics for the model consisted of BLEU, ROUGE, and WER. The training configuration with the evaluating conditions provides a robust framework in which the correctness of the proposed method in actual learning conditions may be determined.
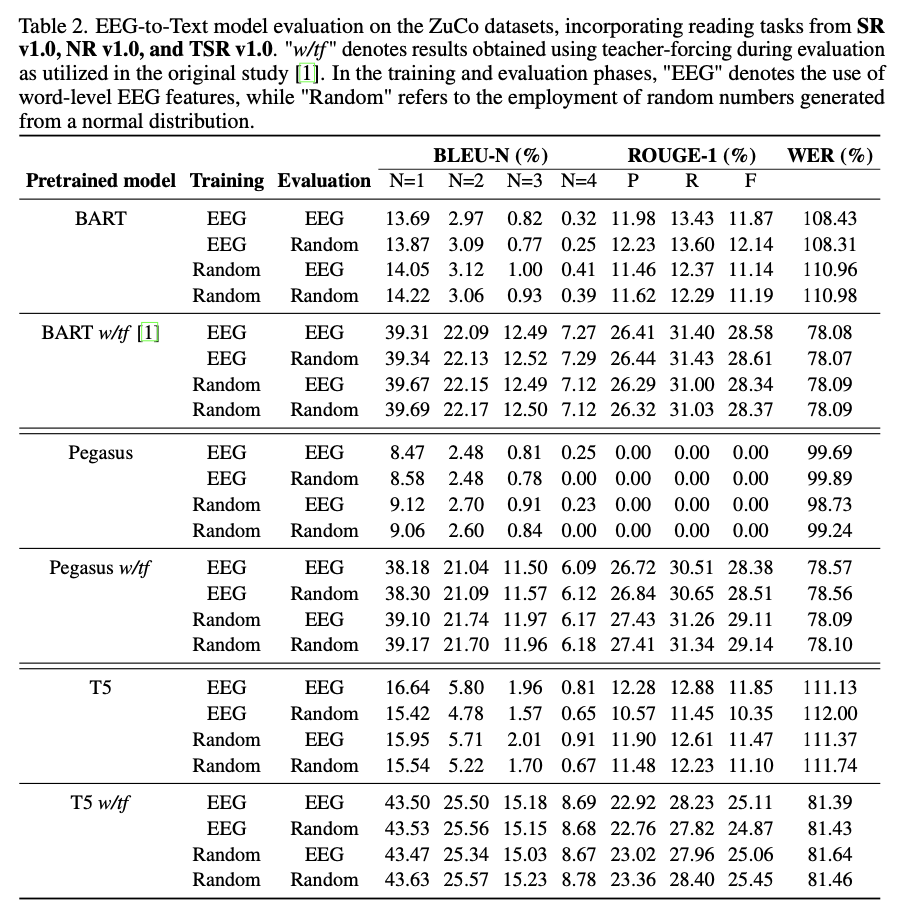
The evaluation reveals that models scored substantially higher when evaluated with teacher-forcing, inflating perceived performance by up to threefold. For instance, without teacher forcing, the BLEU-1 score of EEG-trained models drastically plummeted, which brought the possibility that such models don’t understand what’s going on in the input. More surprisingly, it was shown that model performance was close to being the same whether the input was EEG data or simply pure noise, which gives reason to suspect models often depend on memorized patterns of input rather than learning genuinely about EEG. Thus, it emphasizes the strong necessity for evaluation techniques that do not make use of teacher-forcing and noise baselines to measure the accuracy to which models may learn solely from EEG data.
In conclusion, this work redefines the standards for evaluating EEG-to-Text through strict benchmarking practices such that actual learning occurs from the EEG inputs. This new evaluation methodology by introducing diversified training and testing scenarios removes some long-standing problems regarding teacher-forcing and memorization and allows a more explicit distinction between real learning and memorized patterns. Through this, the authors offer a basis for better and more robust EEG-to-Text models that open ways toward developing communication systems to help people with impairments in the real world. Emphasis on transparent reporting and rigorous baselines will build trust in EEG-to-Text research, leading to further work that will be able to reliably capture the true potential of these models for robust and effective communication solutions.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Sponsorship Opportunity with us] Promote Your Research/Product/Webinar with 1Million+ Monthly Readers and 500k+ Community Members
The post Are EEG-to-Text Models Really Learning or Just Memorizing? A Deep Dive into Model Reliability appeared first on MarkTechPost.
“}]] [[{“value”:”A fundamental challenge in studying EEG-to-Text models is ensuring that the models learn from EEG inputs and not just memorize text patterns. In many reports in the literature where great results have been obtained on brain signal translation to text, there seems to be reliance on implicit teacher-forcing evaluation methods that could artificially inflate performance
The post Are EEG-to-Text Models Really Learning or Just Memorizing? A Deep Dive into Model Reliability appeared first on MarkTechPost.”}]] Read More AI Paper Summary, AI Shorts, Applications, Artificial Intelligence, Editors Pick, Language Model, Large Language Model, Staff, Tech News, Technology