[[{“value”:”

Artificial intelligence has transformed code generation, with large language models (LLMs) for code now integral to software engineering. These models support code synthesis, debugging, and optimization tasks by analyzing vast codebases. However, the development of these code-focused LLMs faces significant challenges. Training requires high-quality instruction-following data, typically gathered through labor-intensive human annotation or leveraging knowledge from larger proprietary models. While these approaches improve model performance, they introduce issues around data accessibility, licensing, and cost. As the demand for transparent, efficient, and scalable methods for training these models grows, innovative solutions that bypass these challenges without sacrificing performance become crucial.
Knowledge distillation from proprietary models can violate licensing restrictions, limiting its use in open-source projects. One major limitation is that human-curated data, though valuable, is costly and challenging to scale. Some open-source methods, like OctoCoder and OSS-Instruct, have attempted to overcome these limitations. However, they often need more performance benchmarks and transparency requirements. These limitations underscore the need for a solution that maintains high performance and aligns with open-source values and transparency.
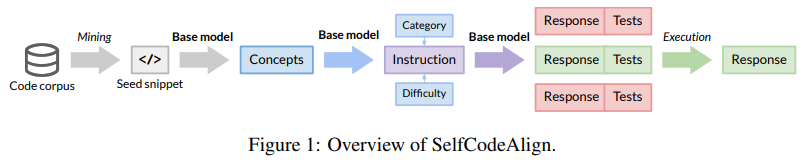
Researchers from the University of Illinois Urbana-Champaign, Northeastern University, University of California Berkeley, ServiceNow Research, Hugging Face, Roblox, and Cursor AI introduced a novel approach called SelfCodeAlign. This approach enables LLMs to train independently, generating high-quality instruction-response pairs without human intervention or proprietary model data. Unlike other models that rely on human annotations or knowledge transfer from large models, SelfCodeAlign generates instructions autonomously by extracting diverse coding concepts from seed data. The model then uses these concepts to create unique tasks and produces multiple responses. These responses are paired with automated test cases and are validated in a controlled sandbox environment. Only those responses that pass are used for final instruction tuning, ensuring the data is accurate and diverse.
SelfCodeAlign’s methodology begins by extracting seed code snippets from a large corpus, focusing on diversity and quality. The initial dataset, “The Stack V1,” is filtered to select 250,000 high-quality Python functions from a pool of 5 million, using stringent quality checks. After choosing these snippets, the model breaks down each into fundamental coding concepts, such as data type conversion or pattern matching. It then generates tasks and responses based on these concepts, assigning difficulty levels and categories to ensure variety. This multi-step approach ensures high-quality data and minimizes biases, making the model adaptable to various coding challenges.
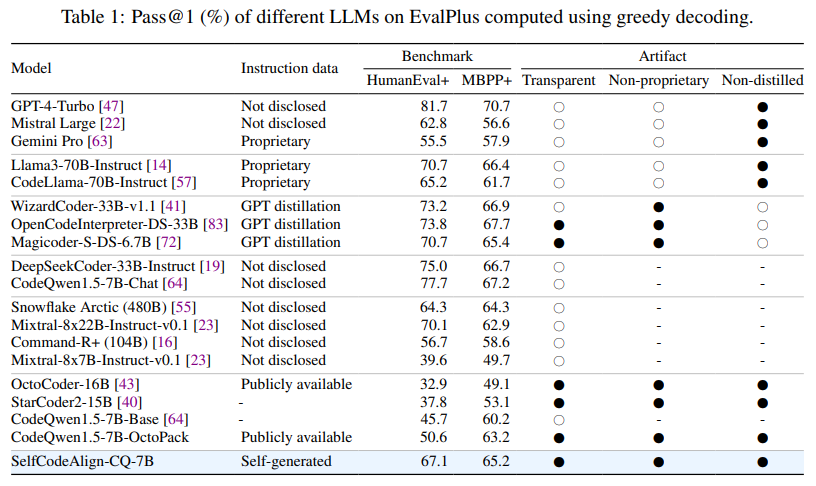
The effectiveness of SelfCodeAlign was rigorously tested with the CodeQwen1.5-7B model. Benchmarked against models like CodeLlama-70B, SelfCodeAlign surpassed many state-of-the-art solutions, achieving a HumanEval+ pass@1 score of 67.1%, which is 16.5 points higher than its baseline model, CodeQwen1.5-7B-OctoPack. The model performed consistently well across various tasks, including function and class generation, data science programming, and code editing, demonstrating that SelfCodeAlign enhances performance across different model sizes, from 3B to 33B parameters. In class-level generation tasks, SelfCodeAlign achieved a pass@1 rate of 27% at the class level and 52.6% at the method level, outperforming many proprietary instruction-tuned models. These results highlight SelfCodeAlign’s potential to produce models that are not only effective but also smaller in size, further increasing accessibility.
Regarding efficiency, on the EvalPerf benchmark, which assesses code efficiency, the model achieved a Differential Performance Score (DPS) of 79.9%. This indicates that SelfCodeAlign-generated solutions matched or exceeded the efficiency of 79.9% of comparable solutions in various efficiency-level tests. Also, SelfCodeAlign achieved a pass@1 rate of 39% in code editing tasks, excelling in corrective, adaptive, and perfective coding changes. This consistent performance across diverse benchmarks emphasizes the effectiveness of SelfCodeAlign’s self-generated data approach.
The main takeaways from SelfCodeAlign’s success are transformative for the field of code LLMs:
- Transparency and Accessibility: SelfCodeAlign is a fully open-source and transparent approach that requires no proprietary model data, making it ideal for researchers focused on ethical AI and reproducibility.
- Efficiency Gains: With a DPS of 79.9% on efficiency benchmarks, SelfCodeAlign demonstrates that smaller, independently trained models can achieve impressive results on par with much larger proprietary models.
- Versatility Across Tasks: The model excels across various coding tasks, including code synthesis, debugging, and data science applications, underscoring its utility for multiple domains in software engineering.
- Cost and Licensing Benefits: SelfCodeAlign’s ability to operate without costly human-annotated data or proprietary LLM distillation makes it highly scalable and economically viable, addressing common limitations in traditional instruction-tuning methods.
- Adaptability for Future Research: The model’s pipeline can accommodate fields beyond coding, showing promise for adaptation in different technical domains.

In conclusion, SelfCodeAlign provides an innovative solution to the challenges of training instruction-following models in code generation. By eliminating the need for human annotations and reliance on proprietary models, SelfCodeAlign offers a scalable, transparent, and high-performance alternative that could redefine how code LLMs are developed. The research demonstrates that autonomous self-alignment, without distillation, can yield results comparable to large, costly models, marking a significant advancement in open-source LLMs for code generation.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Sponsorship Opportunity with us] Promote Your Research/Product/Webinar with 1Million+ Monthly Readers and 500k+ Community Members
The post SelfCodeAlign: An Open and Transparent AI Framework for Training Code LLMs that Outperforms Larger Models without Distillation or Annotation Costs appeared first on MarkTechPost.
“}]] [[{“value”:”Artificial intelligence has transformed code generation, with large language models (LLMs) for code now integral to software engineering. These models support code synthesis, debugging, and optimization tasks by analyzing vast codebases. However, the development of these code-focused LLMs faces significant challenges. Training requires high-quality instruction-following data, typically gathered through labor-intensive human annotation or leveraging knowledge
The post SelfCodeAlign: An Open and Transparent AI Framework for Training Code LLMs that Outperforms Larger Models without Distillation or Annotation Costs appeared first on MarkTechPost.”}]] Read More AI Paper Summary, AI Shorts, Applications, Artificial Intelligence, Editors Pick, Staff, Tech News, Technology