
[[{“value”:”

Retrieval-augmented generation (RAG) represents a great advancement in the capability of large language models (LLMs) to perform tasks accurately by incorporating relevant external information into their processing workflows. This approach, blending information retrieval techniques with generative modeling, has seen growing utility in complex applications such as machine translation, question answering, and comprehensive content generation. By embedding documents into LLMs’ contexts, RAG enables models to access and utilize more extensive and nuanced data sources, effectively expanding the model’s capacity to handle specialized queries. This technique has proven especially valuable in industries that require precise and informed responses, offering a transformative potential for fields where accuracy and specificity are paramount.
A major challenge facing the development of large language models is the effective management of vast contextual information. As LLMs grow more powerful, so does the demand for their ability to synthesize large volumes of data without losing the quality of their responses. However, incorporating extensive external information often results in performance degradation, as the model may need help to retain critical information across long contexts. This issue is compounded in retrieval scenarios, where models must pull from expansive information databases and integrate them cohesively to generate meaningful output. Consequently, optimizing LLMs for longer context lengths is a crucial research goal, particularly as applications increasingly rely on high-volume, data-rich interactions.
Most conventional RAG approaches use embedding documents in vector databases to facilitate efficient, similarity-based retrieval. This process typically involves breaking down documents into retrievable chunks that can be matched to a user’s query based on relevance. While this method has proven useful for short-to-moderate context lengths, many open-source models experience a decline in accuracy as context size increases. While some more advanced models exhibit promising accuracy with up to 32,000 tokens, limitations remain in harnessing even greater context lengths to consistently enhance performance, suggesting a need for more sophisticated approaches.
The research team from Databricks Mosaic Research undertook a comprehensive evaluation of RAG performance across an array of both open-source and commercial LLMs, including well-regarded models such as OpenAI’s GPT-4, Anthropic’s Claude 3.5, and Google’s Gemini 1.5. This evaluation tested the impact of increasing context lengths, ranging from 2,000 tokens up to an unprecedented 2 million tokens, to assess how well various models could maintain accuracy when handling extensive contextual information. By varying context lengths across 20 prominent LLMs, the researchers aimed to identify which models demonstrate superior performance in long-context scenarios, making them better suited for applications requiring large-scale data synthesis.
The research employed a consistent methodology across all models, embedding document chunks using OpenAI’s text-embedding-3-large model and then storing these chunks in a vector store. The study’s tests were conducted on three specialized datasets: Databricks DocsQA, FinanceBench, and Natural Questions, each chosen for its relevance to real-world RAG applications. In the generation stage, these embedded chunks were then provided to a range of generative models, where performance was gauged based on the model’s ability to produce accurate responses to user queries by integrating retrieved information from the context. This approach compared each model’s capacity to handle information-rich scenarios effectively.
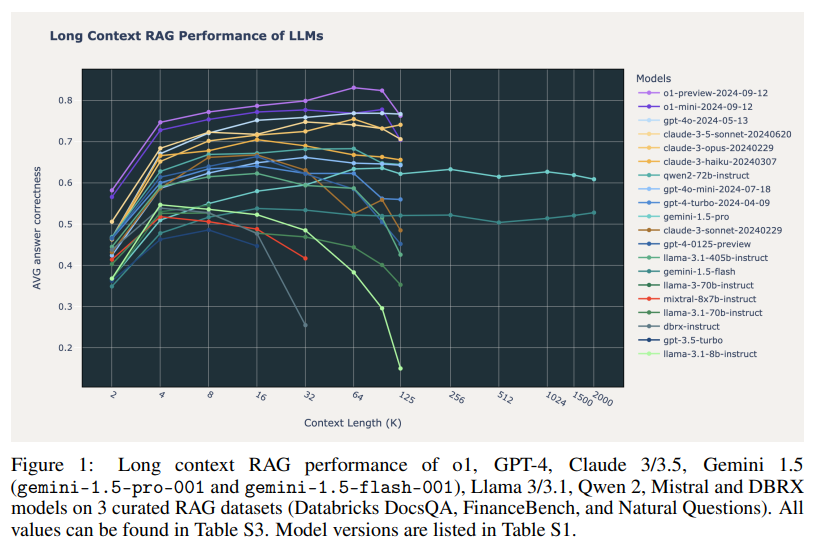
The results showed notable variance in performance across the models. Not all benefited equally from expanded context lengths, as extending context did not consistently improve RAG accuracy. The research found that models such as OpenAI’s o1-mini and o1-preview, GPT-4o, Claude 3.5 Sonnet, and Gemini 1.5 Pro showed steady improvements, sustaining high accuracy levels even up to 100,000 tokens. However, other models, particularly open-source options like Qwen 2 (70B) and Llama 3.1 (405B), displayed performance degradation beyond the 32,000-token mark. Only a few of the latest commercial models demonstrated consistent long-context capabilities, revealing that while extending context can enhance RAG performance, many models still face substantial limitations beyond certain token thresholds. Of particular interest, Google’s Gemini 1.5 Pro model maintained accuracy at extremely long contexts, handling up to 2 million tokens effectively, a remarkable feat not widely observed among other tested models.
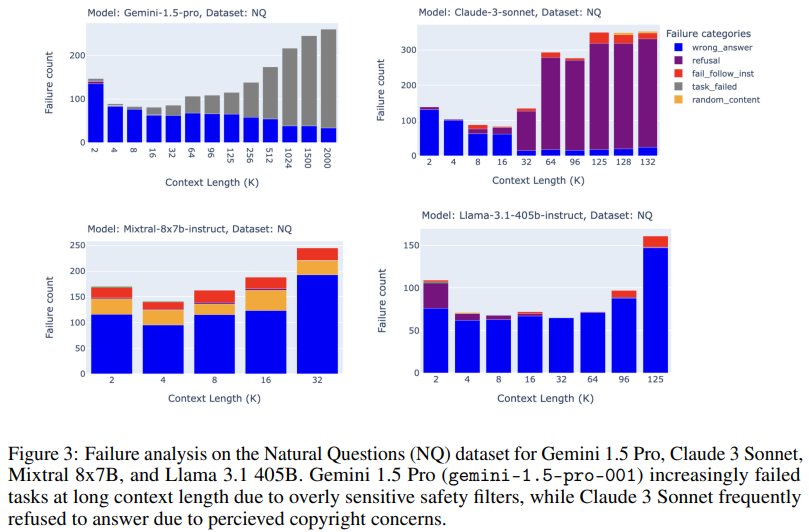
Analyzing the failure patterns of models in long-context scenarios provided additional insights. Some models, such as Claude 3 Sonnet, frequently refused to respond due to concerns around copyright compliance, especially as context lengths increased. Other models, including Gemini 1.5 Pro, encountered difficulties due to overly sensitive safety filters, resulting in repeated refusals to complete certain tasks. Open-source models also exhibited unique failure patterns; Llama 3.1, for example, demonstrated consistent failures in contexts above 64k tokens, often by providing irrelevant or random content. These results underscore that long-context models fail in various ways, largely dependent on context length and task demands, and suggest specific areas for future improvement.
The study’s key findings reveal the potential and limitations of using long-context LLMs for RAG applications. While certain state-of-the-art models, such as OpenAI’s o1 and Google’s Gemini 1.5 Pro, displayed consistent improvement in accuracy across long contexts, most models only demonstrated optimal performance within shorter ranges, around 16,000 to 32,000 tokens. The research team hypothesizes that advanced models like o1 benefit from increased test-time computation, allowing them to handle complex questions and avoid confusion from less relevant retrieved documents. The team’s findings highlight the complexities of long-context RAG applications and provide valuable insights for researchers seeking to refine these techniques.
Key takeaways from the research include:
- Performance Stability: Only a select group of commercial models, such as OpenAI’s o1 and Google’s Gemini 1.5 Pro, maintained consistent performance up to 100,000 tokens and beyond.
- Performance Decline in Open-Source Models: Most open-source models, including Qwen 2 and Llama 3.1, experienced significant performance drops beyond 32,000 tokens.
- Failure Patterns: Models like Claude 3 Sonnet and Gemini 1.5 Pro failed differently, with issues like task refusals due to safety filters or copyright concerns.
- High-Cost Challenges: Long-context RAG is cost-intensive, with processing costs ranging from $0.16 to $5 per query, depending on the model and context length.
- Future Research Needs: The study suggests further research on context management, error handling, and cost mitigation in practical RAG applications.

In conclusion, while extended context lengths present exciting possibilities for LLM-based retrieval, practical limitations persist. Advanced models like OpenAI’s o1 and Google’s Gemini 1.5 show promise, but broader applicability across diverse models and use cases requires continued refinement and targeted improvements. This research marks an essential step toward understanding the trade-offs and challenges inherent in scaling RAG systems for real-world applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Sponsorship Opportunity with us] Promote Your Research/Product/Webinar with 1Million+ Monthly Readers and 500k+ Community Members
The post Databricks Mosaic Research Examines Long-Context Retrieval-Augmented Generation: How Leading AI Models Handle Expansive Information for Improved Response Accuracy appeared first on MarkTechPost.
“}]] [[{“value”:”Retrieval-augmented generation (RAG) represents a great advancement in the capability of large language models (LLMs) to perform tasks accurately by incorporating relevant external information into their processing workflows. This approach, blending information retrieval techniques with generative modeling, has seen growing utility in complex applications such as machine translation, question answering, and comprehensive content generation. By
The post Databricks Mosaic Research Examines Long-Context Retrieval-Augmented Generation: How Leading AI Models Handle Expansive Information for Improved Response Accuracy appeared first on MarkTechPost.”}]] Read More AI Paper Summary, AI Shorts, Applications, Artificial Intelligence, Editors Pick, Machine Learning, Staff, Tech News, Technology