[[{“value”:”

Contrastive learning has become essential for building representations from paired data like image-text combinations in AI. It has shown great utility in transferring learned knowledge to downstream tasks, especially in domains with complex data interdependencies, such as robotics and healthcare. In robotics, for instance, agents gather data from visual, tactile, and proprioceptive sensors, while healthcare professionals integrate medical images, biosignals, and genomic data. Each domain demands a model capable of simultaneously processing multiple data types. Yet, existing models in contrastive learning are predominantly limited to two modalities, restricting the representation quality and usefulness across complex, multimodal scenarios.
A major challenge lies in the limitations of two-modality models, such as CLIP, which are structured to capture only pairwise data dependencies. This setup restricts the model from understanding joint conditional dependencies across more than two data types, leading to a significant information gap. When analyzing multiple modalities—like images, audio, and text—the dependencies between each pair do not reflect the full complexity; for instance, if three types of data exist, a pairwise model might understand the connection between image-text and text-audio but miss the broader relationships, particularly when one data type depends conditionally on another. This inability to represent cross-modal relationships beyond pairs of data types remains a barrier for healthcare and multimedia applications.
Historically, researchers have extended pairwise contrastive models to multiple modalities by applying objectives like CLIP to pairs of modalities. While this two-at-a-time approach introduces a degree of multimodal compatibility, it is limited by the need for specialized architectures or additional training steps for each modality pairing, complicating generalization. Alternative models that handle multiple data types require complex structures and intricate tuning, which ultimately restricts their applicability. While effective in limited applications, these methods demand manual intervention to define suitable modality pairings, leaving room for approaches that capture all modality interactions within a single objective function.
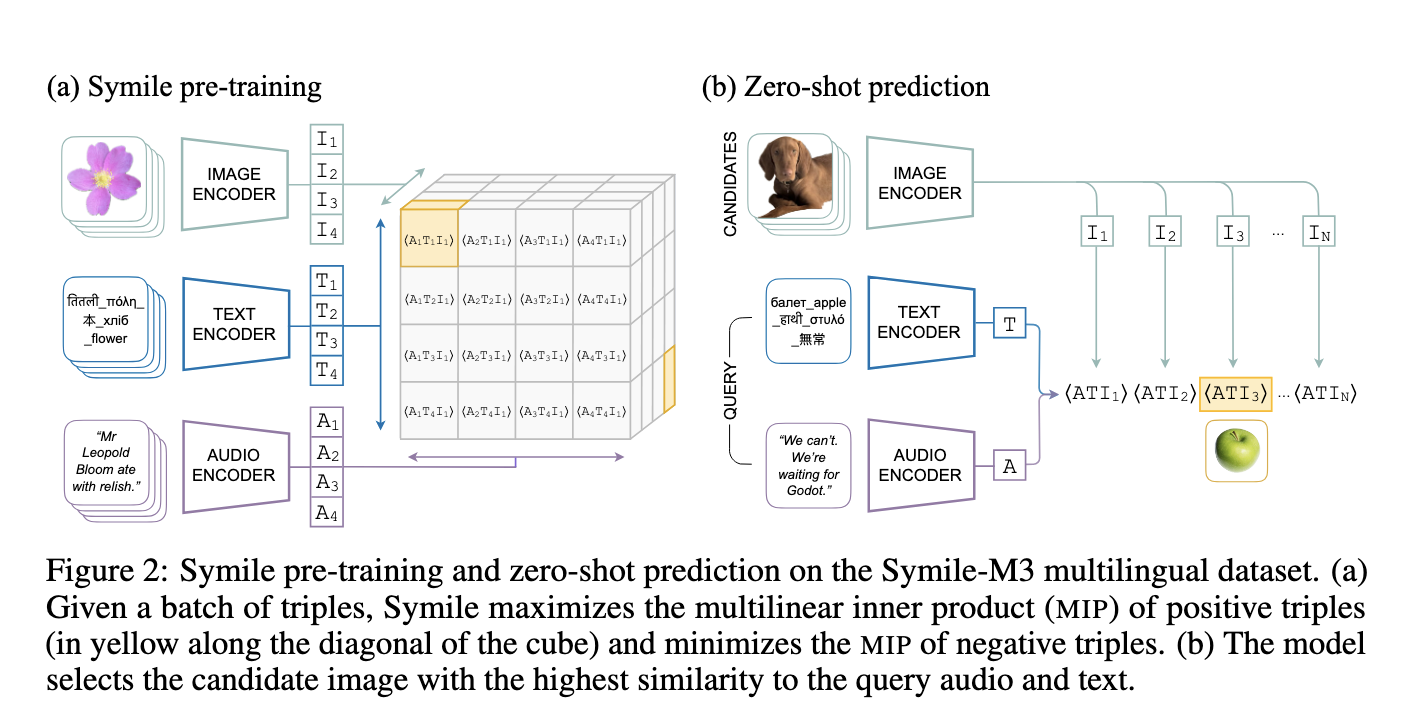
Researchers from New York University present Symile, an innovative contrastive learning model that surpasses these limitations by capturing higher-order dependencies across multiple data modalities without complex adjustments. Unlike pairwise methods, Symile leverages a total correlation objective that accommodates any number of modalities, creating a unified representation without relying on complex architectural changes. The researchers structured Symile to flexibly handle varying modalities, targeting a generalization of mutual information that estimates dependencies across data types. By deriving a lower bound on total correlation, Symile’s model objective captures modality-specific representations that retain critical joint information, enabling it to perform well in scenarios where data from several modalities is incomplete or missing.
Symile’s methodology involves a novel contrastive objective that uses the multilinear inner product (MIP), a scoring function that generalizes dot products to account for three or more vectors, to measure similarity between multiple data types. Symile maximizes positive tuple scores and minimizes negative ones within a batch through this function. The model then averages these losses across all modalities. This enables Symile to capture more than just pairwise information, adding a third layer of “conditional information” among the data types. The researchers optimized the model using a new negative sampling approach, creating more diverse negative samples within each batch simplifying computations for broader datasets.
Symile’s performance on multimodal data tasks highlights its effectiveness over traditional pairwise models. Testing involved various experiments, including cross-modal classification and retrieval of diverse datasets. In one experiment using a synthetic dataset with controlled variables, Symile achieved a near-perfect accuracy of 1.00 when interpreting data with mutual conditional information across three modalities. At the same time, CLIP reached only 0.50, which is effectively the rate of random chance. Further experiments on a large multilingual dataset, Symile-M3, demonstrated Symile’s accuracy of 93.9% in predicting image content based on text and audio across two languages, whereas CLIP achieved just 47.3%. This gap widens as the dataset complexity increases; Symile maintained 88.2% accuracy when using ten languages, while CLIP’s dropped to 9.4%. On a medical dataset incorporating chest X-rays, electrocardiograms, and lab data, Symile achieved 43.5% accuracy in predicting correct matches, outperforming CLIP’s 38.7%.
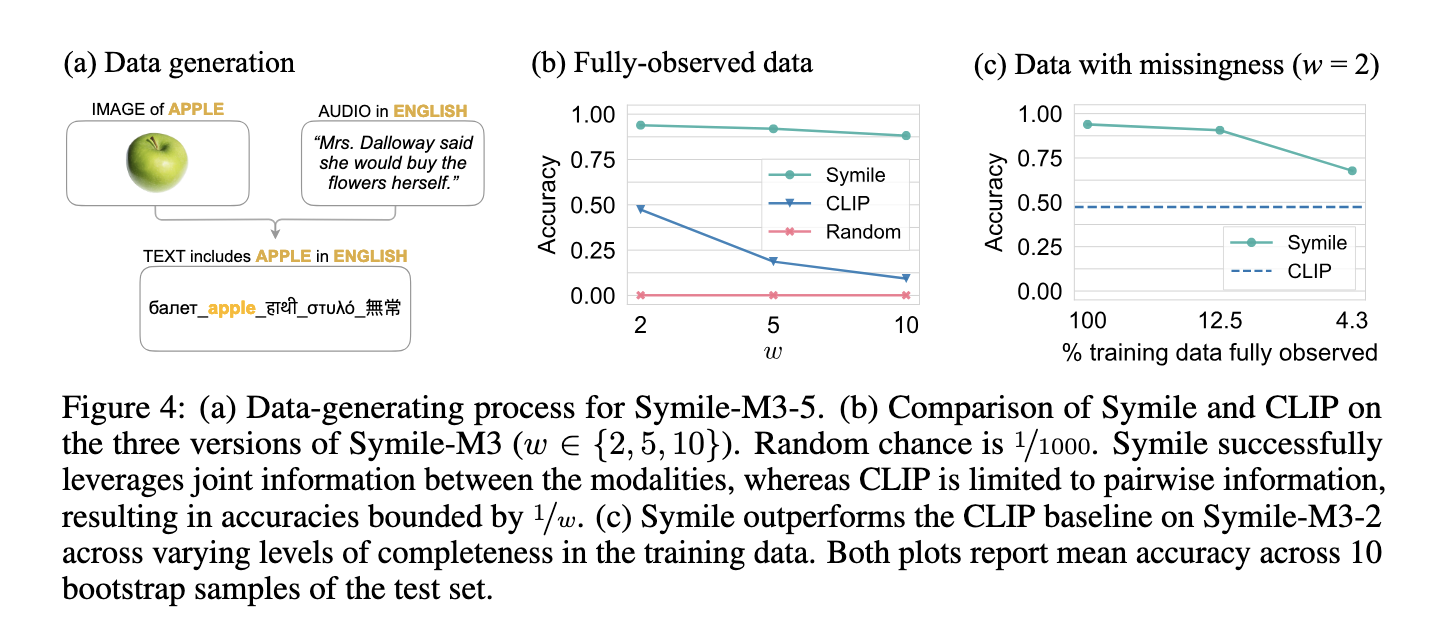
Through its ability to capture joint information among modalities, Symile’s approach allows it to perform well even when some data types are missing. For example, in a variant of Symile-M3 where each modality was randomly omitted with a probability of 50%, Symile maintained high accuracy at 90.6%, significantly outperforming CLIP under the same constraints. The Symile model handled missing data by adapting the objective to maintain accuracy through out-of-support samples, a feature critical for real-world applications like healthcare where all data may not always be available.
This research addresses a major gap in contrastive learning by enabling a model to process multiple data types simultaneously with a straightforward, architecture-independent objective. Symile’s total correlation approach, by capturing more than pairwise information, represents a substantial advancement over two-modality models and delivers superior performance, especially in complex, data-dense domains like healthcare and multilingual tasks. By improving representation quality and adaptability, Symile is well-positioned as a valuable tool for multimodal integration, offering a flexible solution that aligns with real-world data’s complex, high-dimensional nature.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Upcoming Live LinkedIn event] ‘One Platform, Multimodal Possibilities,’ where Encord CEO Eric Landau and Head of Product Engineering, Justin Sharps will talk how they are reinventing data development process to help teams build game-changing multimodal AI models, fast‘
The post Researchers from New York University Introduce Symile: A General Framework for Multimodal Contrastive Learning appeared first on MarkTechPost.
“}]] [[{“value”:”Contrastive learning has become essential for building representations from paired data like image-text combinations in AI. It has shown great utility in transferring learned knowledge to downstream tasks, especially in domains with complex data interdependencies, such as robotics and healthcare. In robotics, for instance, agents gather data from visual, tactile, and proprioceptive sensors, while healthcare
The post Researchers from New York University Introduce Symile: A General Framework for Multimodal Contrastive Learning appeared first on MarkTechPost.”}]] Read More AI Paper Summary, AI Shorts, Applications, Artificial Intelligence, Editors Pick, Machine Learning, Staff, Tech News, Technology