[[{“value”:”

Advancements in large language models (LLMs) have revolutionized natural language processing, with applications spanning text generation, translation, and summarization. These models rely on large amounts of data, large parameter counts, and expansive vocabularies, necessitating sophisticated techniques to manage computational and memory requirements. A critical component of LLM training is the cross-entropy loss computation, which, while central to model accuracy, presents significant memory challenges due to the size and complexity of the vocabulary.
The memory requirements of the cross-entropy loss layer constrict training large language models, especially as vocabulary sizes reach hundreds of thousands of tokens. The issue becomes acute in models like Gemma 2 (2B), where the cross-entropy loss computation alone can consume up to 24 GB of memory, accounting for up to 90% of the memory footprint during training. These limitations restrict batch sizes and force trade-offs between model performance and computational feasibility, posing a significant bottleneck for scalability.
Previous methods aimed at reducing memory usage, such as FlashAttention and hierarchical vocabularies, have addressed specific components like self-attention but fall short in alleviating the burden of the cross-entropy layer. Chunking methods reduce memory requirements but introduce latency trade-offs, limiting their practical use. Also, these approaches need to fully exploit the sparsity of gradients or leverage hardware optimizations, leaving room for improvement.
Researchers at Apple introduced the Cut Cross-Entropy (CCE) method, a novel approach designed to overcome the memory challenges associated with large vocabulary models. Unlike conventional methods that compute and store all logits for tokens in memory, CCE dynamically calculates only the necessary logits and performs log-sum-exp reductions in on-chip memory. This technique eliminates the need to materialize large matrices in GPU memory, significantly reducing the memory footprint. For instance, in the Gemma 2 model, the memory usage for loss computation dropped from 24 GB to just 1 MB, with total classifier head memory consumption reduced from 28 GB to 1 GB.
The core of CCE lies in its efficient computation strategy, which employs custom CUDA kernels to process embeddings and perform reductions. By calculating logits on the fly and avoiding intermediate memory storage, the method capitalizes on shared GPU memory, which is faster and more efficient than traditional global memory usage. Also, gradient filtering selectively skips computations that contribute negligibly to the gradient, leveraging the inherent sparsity of the softmax matrix. Vocabulary sorting optimizes processing by grouping tokens with significant contributions, minimizing wasted computation. Together, these innovations enable a memory-efficient, low-latency loss computation mechanism.
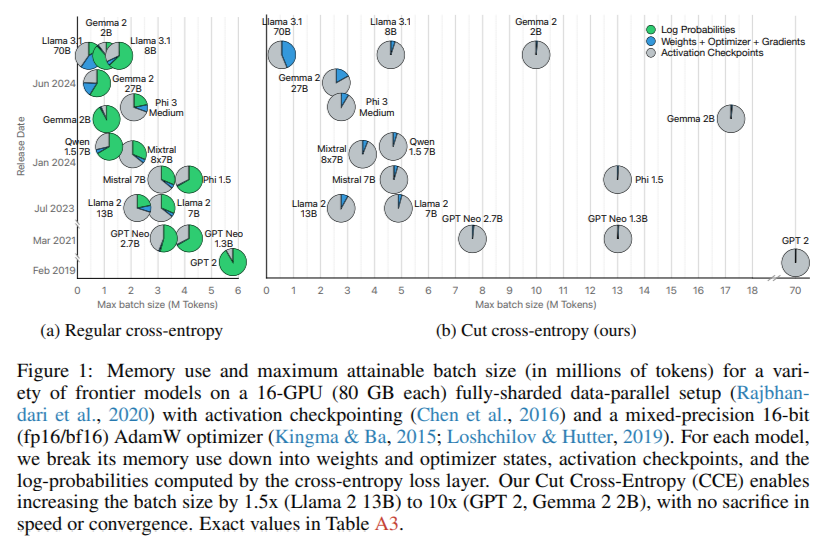
The performance gains from CCE are remarkable. Memory reductions enabled a 10-fold increase in batch size for smaller models like GPT-2 and a 1.5-fold increase for larger models like Llama 2 (13B). Training throughput remained unaffected, and experimental results demonstrated stable convergence, matching the performance of traditional methods. For a batch of 8,192 tokens with a vocabulary size 256,000, CCE achieved a peak memory usage of just 1 MB compared to 28 GB in baseline methods. Training stability tests on models such as Llama 3 (8B) and Phi 3.5 Mini confirmed the reliability of CCE, with indistinguishable loss curves compared to existing approaches.
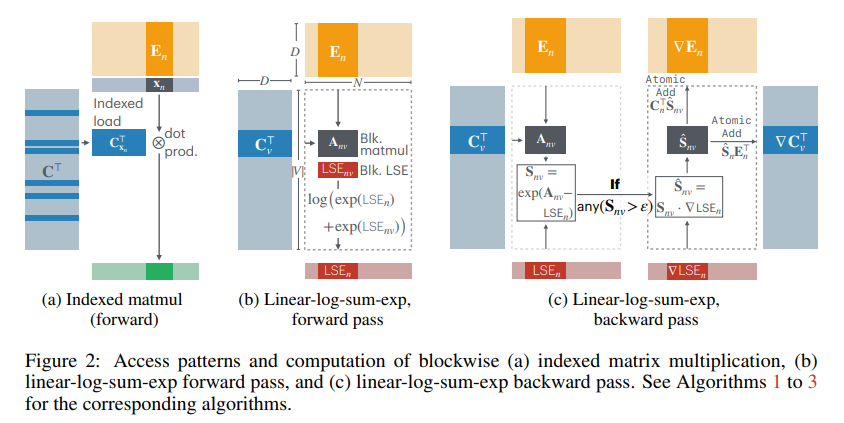
This research highlights several key takeaways:
- Significant Memory Reduction: CCE reduces memory usage for cross-entropy loss computation to negligible levels, as low as 1 MB for large-scale models like Gemma 2 (2B).
- Improved Scalability: By enabling larger batch sizes, the method supports more efficient utilization of computational resources, which is crucial for training extensive models.
- Efficiency Gains: Custom CUDA kernels and gradient filtering ensure that the reduction in memory footprint does not compromise training speed or model convergence.
- Practical Applicability: The method is adaptable to various architectures and scenarios, with potential applications extending to image classification and contrastive learning.
- Future Potential: CCE’s ability to handle large vocabularies with minimal memory impact could facilitate training even more extensive models with improved pipeline balancing.
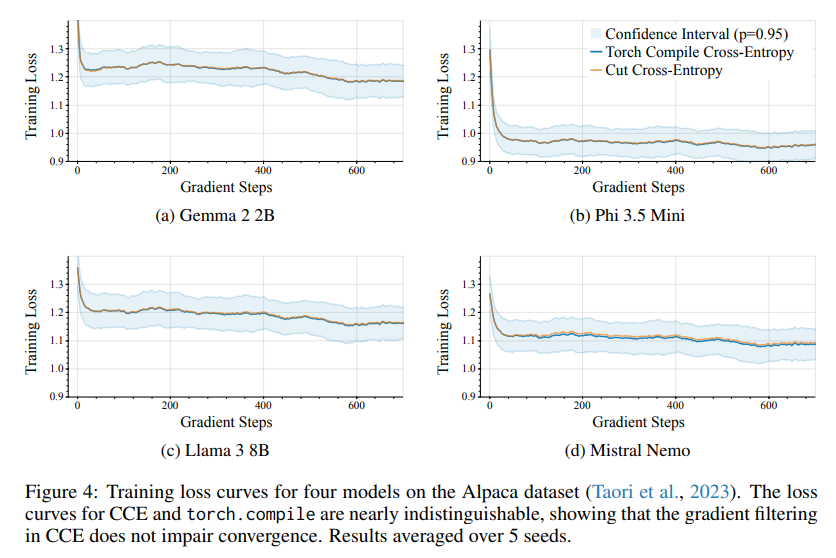

In conclusion, the CCE method represents a significant breakthrough in training large language models by addressing the critical bottleneck of memory-intensive cross-entropy loss layers. Through innovative techniques like dynamic logit computation, gradient filtering, and vocabulary sorting, CCE enables dramatic reductions in memory usage without sacrificing speed or accuracy. This advancement not only enhances the efficiency of current models but also paves the way for more scalable and balanced architectures in the future, opening new possibilities for large-scale machine learning.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[FREE AI WEBINAR] Implementing Intelligent Document Processing with GenAI in Financial Services and Real Estate Transactions
The post Apple Researchers Propose Cut Cross-Entropy (CCE): A Machine Learning Method that Computes the Cross-Entropy Loss without Materializing the Logits for all Tokens into Global Memory appeared first on MarkTechPost.
“}]] [[{“value”:”Advancements in large language models (LLMs) have revolutionized natural language processing, with applications spanning text generation, translation, and summarization. These models rely on large amounts of data, large parameter counts, and expansive vocabularies, necessitating sophisticated techniques to manage computational and memory requirements. A critical component of LLM training is the cross-entropy loss computation, which, while
The post Apple Researchers Propose Cut Cross-Entropy (CCE): A Machine Learning Method that Computes the Cross-Entropy Loss without Materializing the Logits for all Tokens into Global Memory appeared first on MarkTechPost.”}]] Read More AI Paper Summary, AI Shorts, Applications, Artificial Intelligence, Editors Pick, Machine Learning, Staff, Tech News, Technology