[[{“value”:”

Despite their advanced reasoning capabilities, the latest LLMs often miss the mark when deciphering relationships. In this article, we explore the Reversal Curse, a pitfall that affects LLMs across tasks such as comprehension and generation. To understand the underlying issue, it is a phenomenon that occurs when dealing with two entities, denoted as a and b, connected by their relation R and its inverse. LLMs excel at handling sequences such as “aRb” but struggle with “b R inverse a.” While LLMs can quickly answer questions like “Who is the mother of Tom Cruise?” when asked, they are more likely to hallucinate and falter when asked, “Who is Mary Lee Pfeiffer’s son?” This seems straightforward, given that the model already knows the relationship between Tom Cruise and Mary Lee Pfeiffer.
Researchers from the Renmin University of China have presented the reversal curse of LLMs to the research community, shedding light on its probable causes and suggesting potential mitigation strategies. They identify the Training Objective Function as one of the key factors influencing the extent of the reversal curse.
To fully grasp the reversal curse, we must first understand the training process of LLMs. Next-token prediction (NTP) is the dominant pre-training objective for current large language models, such as GPT and Llama. In models like GPT and Llama, attention masks during training depend on the preceding tokens, meaning each token focuses solely on its prior context, making it impossible to account for subsequent tokens. As a result, if a occurs before b in the training corpus, the model maximizes the probability of b given over the likelihood of a given b. Therefore, there is no guarantee that LLMs can provide a high probability for a when presented with b. In contrast, GLM models are pre-trained with autoregressive blank in-filling objectives, where the masked token controls both preceding and succeeding tokens, making them more robust to the reversal curse. The authors argue that this difference in sequence training is the root cause of LLMs’ underperformance with inverse relations.
To test this hypothesis, the authors fine-tuned GLMs on “Name to Description” data, using fictitious names and feeding descriptions to retrieve information about the entities.
The GLMs achieved approximately 80% accuracy on this task, while Llama’s accuracy was 0%.
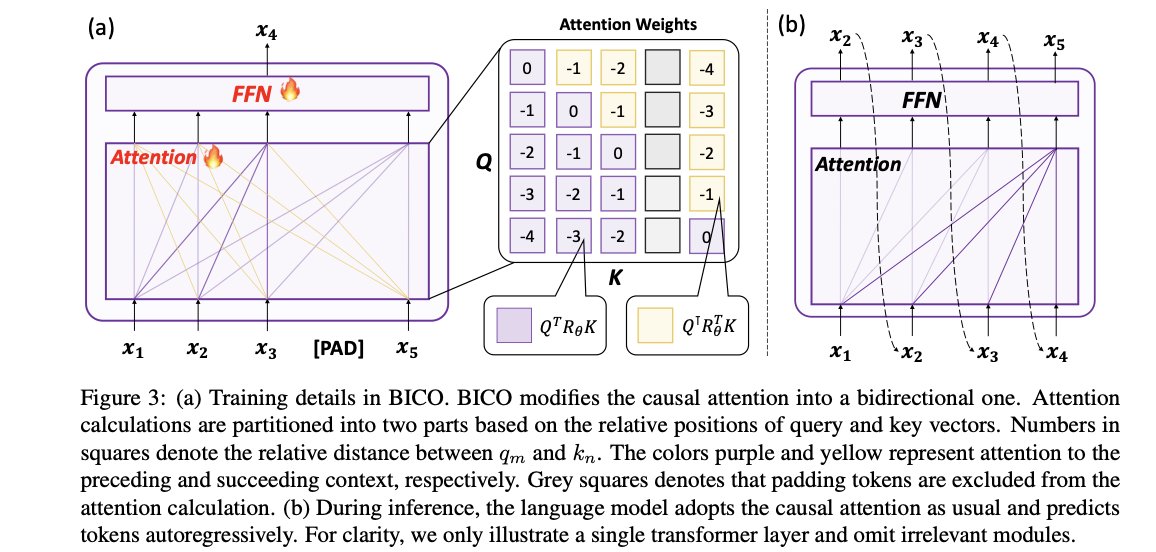
To address this issue, the authors propose a method that adapts the training objective of LLMs to something similar to ABI. They fine-tuned models using Bidirectional Causal Language Model Optimization (BICO) to reverse-engineer mathematical tasks and translation problems. BICO adopts an autoregressive blank infilling objective, similar to GLM, but with tailored modifications designed explicitly for causal language models. The authors introduced rotary (relative) position embeddings and modified the attention function to make it bidirectional. This fine-tuning method improved the model’s accuracy in reverse translation and mathematical problem-solving tasks.
In conclusion, the authors analyze the reversal curse and propose a fine-tuning strategy to mitigate this pitfall. By adopting a causal language model with an ABI-like objective, this study sheds light on the reversal underperformance of LLMs. This work could be further expanded to examine the impact of advanced techniques, such as RLHF, on the reversal curse.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[FREE AI WEBINAR] Implementing Intelligent Document Processing with GenAI in Financial Services and Real Estate Transactions– From Framework to Production
The post Bidirectional Causal Language Model Optimization to Make GPT and Llama Robust Against the Reversal Curse appeared first on MarkTechPost.
“}]] [[{“value”:”Despite their advanced reasoning capabilities, the latest LLMs often miss the mark when deciphering relationships. In this article, we explore the Reversal Curse, a pitfall that affects LLMs across tasks such as comprehension and generation. To understand the underlying issue, it is a phenomenon that occurs when dealing with two entities, denoted as a and
The post Bidirectional Causal Language Model Optimization to Make GPT and Llama Robust Against the Reversal Curse appeared first on MarkTechPost.”}]] Read More AI Paper Summary, AI Shorts, Applications, Artificial Intelligence, Editors Pick, Language Model, Machine Learning, Staff, Tech News, Technology