[[{“value”:”

A significant challenge in the field of artificial intelligence is to facilitate large language models (LLMs) to generate 3D meshes from text descriptions directly. Conventional techniques restrict LLMs from operating as text-based components and remove multimodal workflows that combine textual and 3D content creation. Most of the existing frameworks require additional architectures or massive computational resources, making them difficult to use in real-time, interactive environments like video games, virtual reality, and industrial design, for example. Lacking unified systems that colloquially blend text understanding and 3D generation further complicates efficient and accessible 3D content creation. In contrast, the solutions to such problems might change the landscape of multimodal AI and make 3D design workflows more intuitive and scalable.
Existing approaches to 3D generation can be broadly categorized into auto-regressive models and score-distillation methods. Auto-regressive models like MeshGFT and PolyGen tokenize 3D mesh data and use transformers to create object meshes. They perform well but have been trained from scratch and do not come with any integration of natural language; besides this, they require huge computational resources. Score-distillation methods comprise DreamFusion and Magic3D; they use a single pre-trained diffusion model for creating objects. These methods rely on intermediate representations such as signed distance fields or voxel grids, which include more processing and are computationally expensive and, therefore, are not very efficient for real-time applications. Neither type allows the flexibility needed to easily insert text-based and 3D generation capabilities within a unified, efficient framework.
NVIDIA and Tsinghua University researchers introduce LLAMA-MESH, the first-ever framework combining the representations of text and 3D modalities into a single architecture. The text-based OBJ file format encodes 3D meshes in plain text, consisting of vertex coordinates and face definitions. Because there is neither the need to expand token vocabularies nor to alter tokenizers, the design cuts computational cost; by using spatial knowledge and combining that with the LLMs’ conditioned foundation, LLAMA-MESH allows users to generate 3D content directly from text prompts. Its training on an editorial dataset of interleaved text-3D dialogues allows for generating capabilities, including the interpretation and description of 3D meshes in natural language. Furthermore, its integration eliminates separate architectures and, hence renders the framework highly efficient and versatile for conducting multimodal tasks.
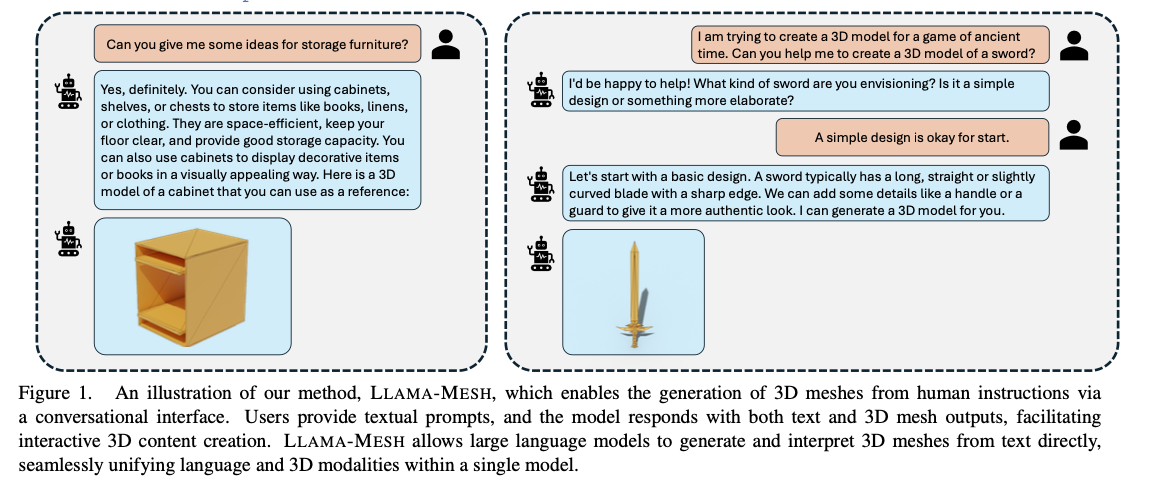
Meshes are encoded in the OBJ format, with vertex coordinates and face definitions converted into plain text sequences. Quantization is applied to vertex coordinates to reduce the length of the token sequences without compromising the geometric fidelity for compatibility with the LLM context window. Fine-tuning takes place over a dataset developed from Objaverse, that contains over 31,000 curated meshes, extended to 125,000 samples through data augmentation. Captions are produced with Cap3D while the richness of dialogue structures is decided based on rule-based patterns as well as LLM augmentation techniques. It was fine-tuned on 32 A100 GPUs for 21,000 iterations using a mix of mesh generation, mesh understanding, and conversational tasks. The used architecture is LLaMA 3.1-8B-Instruct, providing a good initialization when combining the text and 3D modalities.
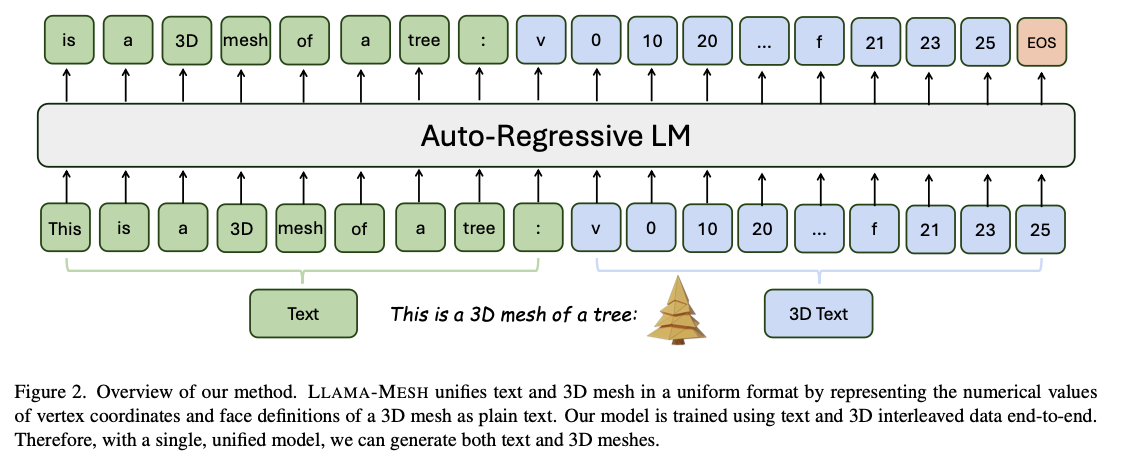
LLAMA-MESH achieves outstanding performance: creates diverse, high-quality 3D meshes with artist-like topology while outperforming traditional approaches in terms of computational efficiency on the balance of multimodal tasks, with sound language understanding and reasoning capabilities. The architecture appears stronger for text-to-3D generation, proven in real-world design and interactive environment applications. That is, end-to-end integration of text understanding and 3D creation was enabled; it is a significant advancement in multimodal AI.
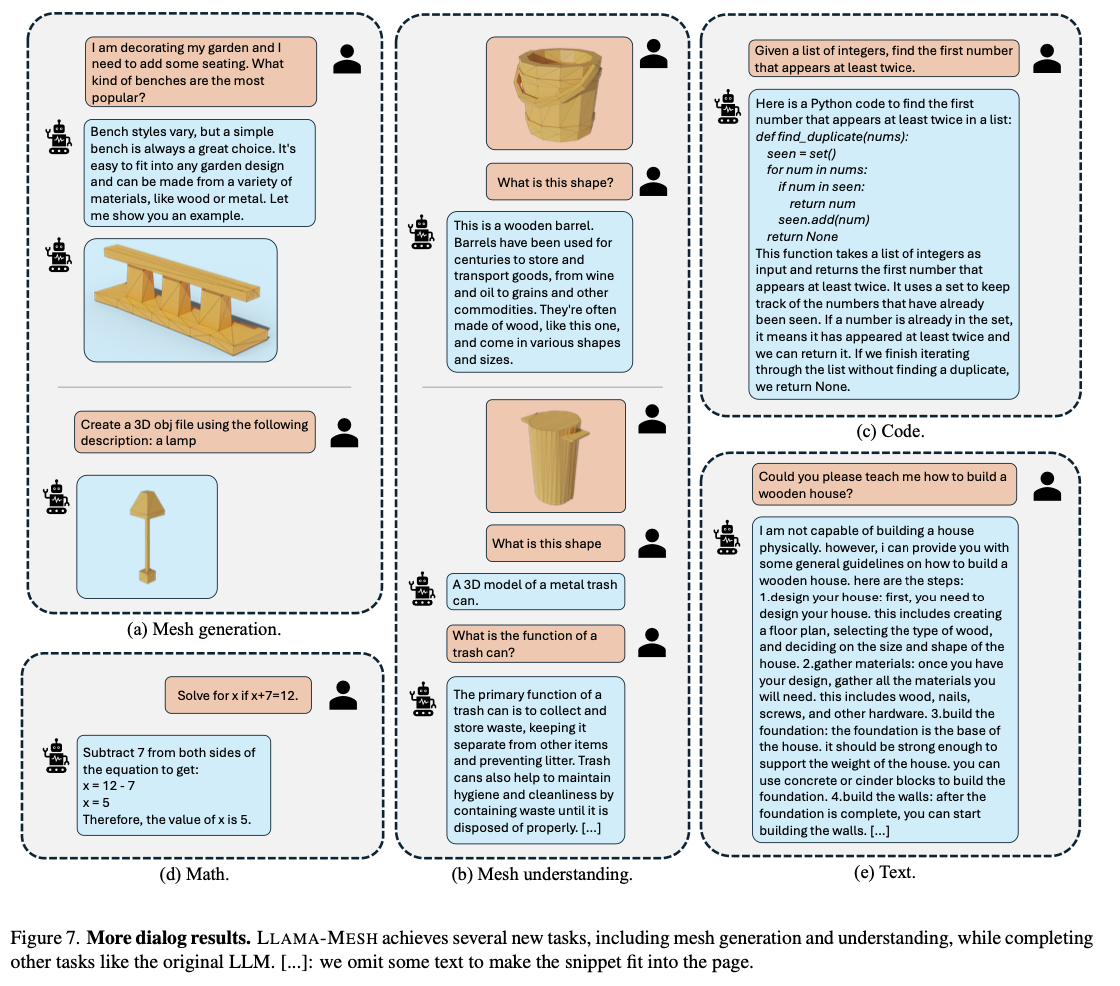

By bridging the gap between textual and 3D modalities, LLAMA-MESH offers an efficient and unified solution for generating and interpreting 3D meshes directly from textual prompts. Equally well-suited outcomes like such that would be produced through specialized 3D models, a strength of this is thought to be as robust a language-awareness ability. This work has unlocked new ways and avenues toward more intuitive, language-driven approaches to 3D workflows and has made tremendous changes in gaming, virtual reality, and industrial design applications.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[FREE AI WEBINAR] Implementing Intelligent Document Processing with GenAI in Financial Services and Real Estate Transactions– From Framework to Production
The post LLaMA-Mesh: A Novel AI Approach that Unifies 3D Mesh Generation with Large Language Models by Representing Meshes as Plain Text appeared first on MarkTechPost.
“}]] [[{“value”:”A significant challenge in the field of artificial intelligence is to facilitate large language models (LLMs) to generate 3D meshes from text descriptions directly. Conventional techniques restrict LLMs from operating as text-based components and remove multimodal workflows that combine textual and 3D content creation. Most of the existing frameworks require additional architectures or massive computational
The post LLaMA-Mesh: A Novel AI Approach that Unifies 3D Mesh Generation with Large Language Models by Representing Meshes as Plain Text appeared first on MarkTechPost.”}]] Read More AI Paper Summary, AI Shorts, Applications, Artificial Intelligence, Editors Pick, Machine Learning, Staff, Tech News, Technology