[[{“value”:”

In the evolving field of artificial intelligence, a major challenge has been building models that excel in specific tasks while also being capable of understanding and reasoning across multiple data types, such as text, images, and audio. Traditional large language models have been successful in natural language processing (NLP) tasks, but they often struggle to handle diverse modalities simultaneously. Multimodal tasks require a model that can effectively integrate and reason over different types of data, which demands significant computational resources, large-scale datasets, and a well-designed architecture. Moreover, the high costs and proprietary nature of most state-of-the-art models create barriers for smaller institutions and developers, limiting broader innovation.
Meet Pixtral Large: A Step Towards Accessible Multimodal AI
Mistral AI has taken a meaningful step forward with the release of Pixtral Large: a 124 billion-parameter multimodal model built on top of Mistral Large 2. This model, released with open weights, aims to make advanced AI more accessible. Mistral Large 2 has already established itself as an efficient, large-scale transformer model, and Pixtral builds on this foundation by expanding its capabilities to understand and generate responses across text, images, and other data types. By open-sourcing Pixtral Large, Mistral AI addresses the need for accessible multimodal models, contributing to community development and fostering research collaboration.
Technical Details
Technically, Pixtral Large leverages the transformer backbone of Mistral Large 2, adapting it for multimodal integration by introducing specialized cross-attention layers designed to fuse information across different modalities. With 124 billion parameters, the model is fine-tuned on a diverse dataset comprising text, images, and multimedia annotations. One of the key strengths of Pixtral Large is its modular architecture, which allows it to specialize in different modalities while maintaining a general understanding. This flexibility enables high-quality multimodal outputs—whether it involves answering questions about images, generating descriptions, or providing insights from both text and visual data. Furthermore, the open-weights model allows researchers to fine-tune Pixtral for specific tasks, offering opportunities to tailor the model for specialized needs.
To effectively utilize Pixtral Large, Mistral AI recommends employing the vLLM library for production-ready inference pipelines. Ensure that vLLM version 1.6.2 or higher is installed:
pip install --upgrade vllmAdditionally, install mistral_common version 1.4.4 or higher:
pip install --upgrade mistral_commonFor a straightforward implementation, consider the following example:
from vllm import LLM
from vllm.sampling_params import SamplingParams
model_name = "mistralai/Pixtral-12B-2409"
sampling_params = SamplingParams(max_tokens=8192)
llm = LLM(model=model_name, tokenizer_mode="mistral")
prompt = "Describe this image in one sentence."
image_url = "https://picsum.photos/id/237/200/300"
messages = [
{
"role": "user",
"content": [
{"type": "text", "text": prompt},
{"type": "image_url", "image_url": {"url": image_url}}
]
},
]
outputs = llm.chat(messages, sampling_params=sampling_params)
print(outputs[0].outputs[0].text)This script initializes the Pixtral model and processes a user message containing both text and an image URL, generating a descriptive response.
Significance and Potential Impact
The release of Pixtral Large is significant for several reasons. First, the inclusion of open weights provides an opportunity for the global research community and startups to experiment, customize, and innovate without bearing the high costs often associated with multimodal AI models. This makes it possible for smaller companies and academic institutions to develop impactful, domain-specific applications. Initial tests conducted by Mistral AI indicate that Pixtral outperforms its predecessors in cross-modality tasks, demonstrating improved accuracy in visual question answering (VQA), enhanced text generation for image descriptions, and strong performance on benchmarks such as COCO and VQAv2. Test results show that Pixtral Large achieves up to a 7% improvement in accuracy compared to similar models on benchmark datasets, highlighting its effectiveness in comprehending and linking diverse types of content. These advancements can support the development of applications ranging from automated media editing to interactive assistants.
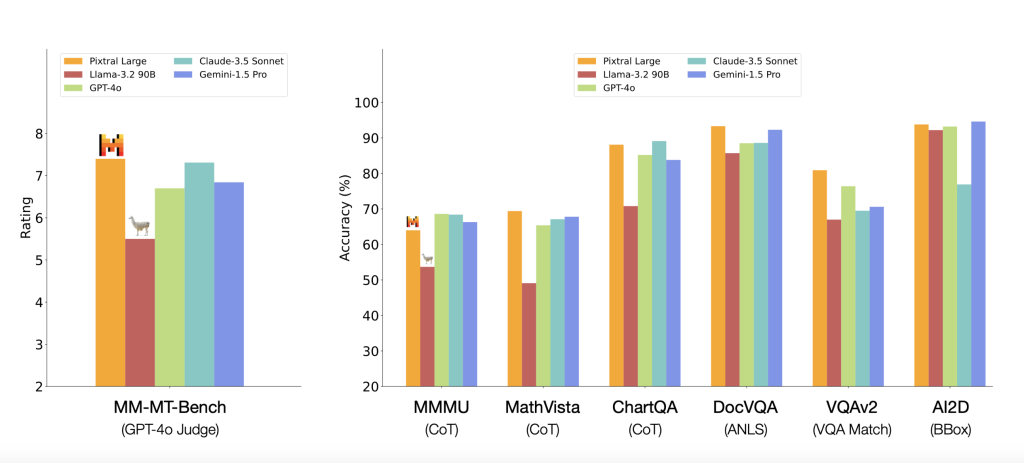

Conclusion
Mistral AI’s release of Pixtral Large marks an important development in the field of multimodal AI. By building on the robust foundation provided by Mistral Large 2, Pixtral Large extends capabilities to multiple data formats while maintaining strong performance. The open-weight nature of the model makes it accessible for developers, startups, and researchers, promoting inclusivity and innovation in a field where such opportunities have often been limited. This initiative by Mistral AI not only extends the technical possibilities of AI models but also aims to make advanced AI resources broadly available, providing a platform for further breakthroughs. It will be interesting to see how this model is applied across industries, encouraging creativity and addressing complex problems that benefit from an integrated understanding of multimodal data.
Check out the Details and Model on Hugging Face. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
Why AI-Language Models Are Still Vulnerable: Key Insights from Kili Technology’s Report on Large Language Model Vulnerabilities [Read the full technical report here]
The post Mistral AI Releases Pixtral Large: A 124B Open-Weights Multimodal Model Built on Top of Mistral Large 2 appeared first on MarkTechPost.
“}]] [[{“value”:”In the evolving field of artificial intelligence, a major challenge has been building models that excel in specific tasks while also being capable of understanding and reasoning across multiple data types, such as text, images, and audio. Traditional large language models have been successful in natural language processing (NLP) tasks, but they often struggle to
The post Mistral AI Releases Pixtral Large: A 124B Open-Weights Multimodal Model Built on Top of Mistral Large 2 appeared first on MarkTechPost.”}]] Read More AI Shorts, Applications, Artificial Intelligence, Editors Pick, Language Model, Machine Learning, New Releases, Staff, Tech News, Technology