[[{“value”:”
Table of Contents
- What Is a Vision-Language Model?
- Architecture of PaliGemma
- How Is PaliGemma Trained?
- Available Model Checkpoints
- Use Cases of PaliGemma
- Why PaliGemma?
- Setup and Imports
- Load and Inspect the Dataset
- Split the Dataset into Train-Test
- Preprocess the Dataset
- Fine-Tune Only the Text Decoder
- Using the QLoRA Technique
Fine Tune PaliGemma with QLoRA for Visual Question Answering
In this tutorial, we will learn about PaliGemma briefly and demonstrate how to fine-tune it using the QLoRA (Quantized Low-Rank Adaptation) technique to achieve improved inference results, helping us create a custom vision-language model tailored to our specific tasks.

This lesson is the 1st of a 4-part series on Vision-Language Models:
- Fine Tune PaliGemma with QLoRA for Visual Question Answering (this tutorial)
- Vision-Language Model: PaliGemma for Image Description Generator and More
- Deploy Gradio Applications on Hugging Face Spaces
- Object Detection with PaliGemma
To learn how to use and fine-tune PaliGemma on your own dataset, just keep reading.
What Is PaliGemma?
PaliGemma is an open Vision-Language Model (VLM) released by Google. It builds on the PaLI (Pathways Language and Image) series and the Gemma family of language models.
While many VLMs are getting larger to handle more tasks, PaliGemma focuses on being smaller and more efficient.
- Compact Size: Only about
3Bparameters, significantly smaller than many VLMs. - Competitive Performance: Can be fine-tuned to match the capabilities of larger models.
- Adaptability: Efficient and easy to customize for various tasks.
What Is a Vision-Language Model?
A Vision-Language Model (VLM) combines visual and textual understanding, processing images and text simultaneously to grasp their relationship. This enables VLMs to handle tasks like image captioning, visual question answering, and more.
How VLMs Work
- Image Processing: A component specifically trained to interpret visual data.
- Language Processing: Another component designed to handle textual information.
- Joint Understanding: The model learns how visuals and language relate, enabling it to describe images or answer questions about them.
For example, a VLM can look at a picture of a dog and generate a descriptive sentence about it.
As VLMs have evolved, they have become more powerful, with larger models able to handle more complex tasks.
However, recent efforts also focus on creating smaller, more efficient VLMs (e.g., PaliGemma) that can perform just as well without massive computational resources.
Architecture of PaliGemma
PaliGemma (architecture shown in Figure 1) is a simple input+text-in, text-out model that takes an image and text as input and generates text as output.
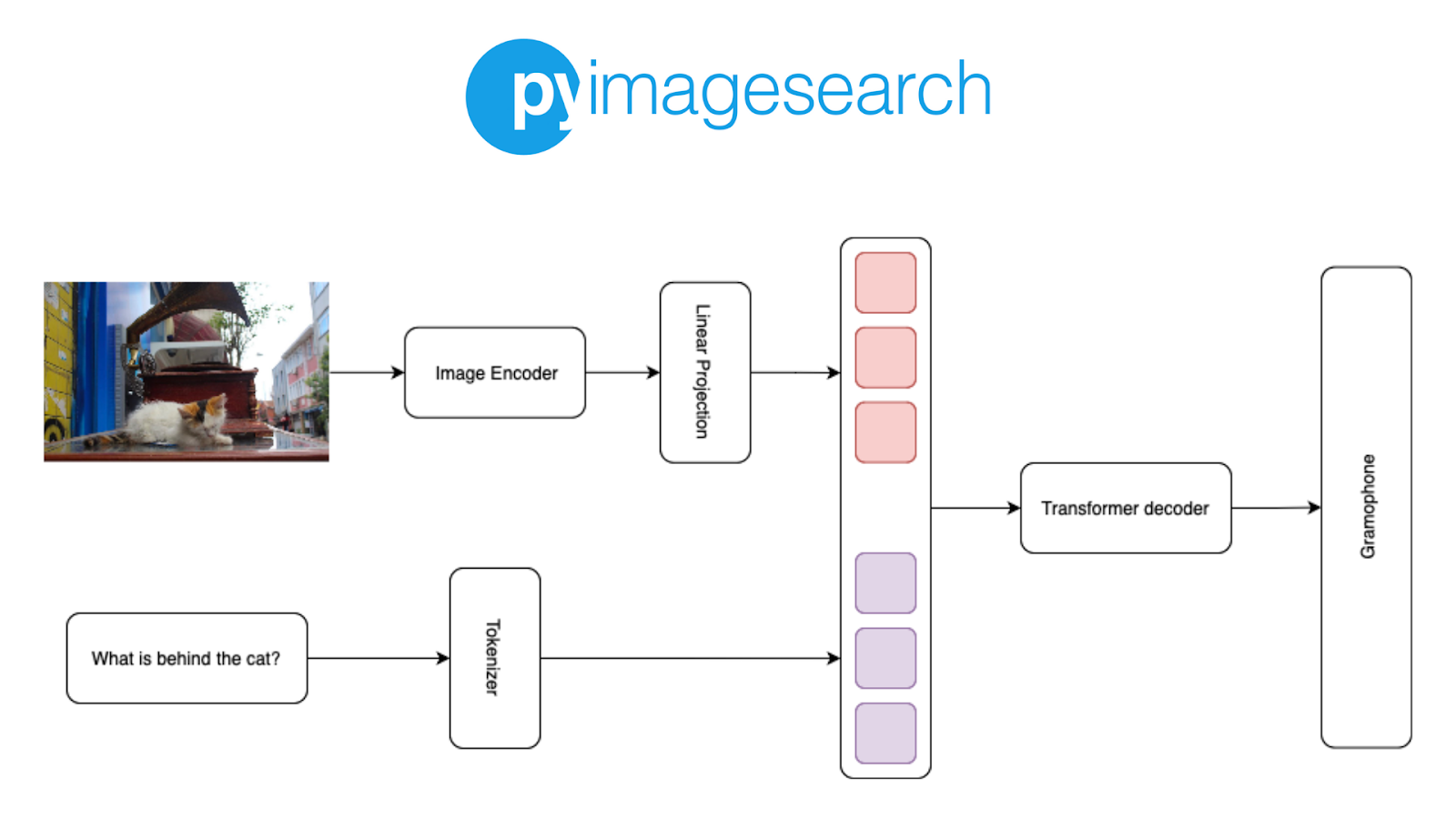
PaliGemma’s architecture is built on three key components:
1. Image Encoder
- PaliGemma uses the SigLIP (Sigmoid loss for Language-Image Pre-training) checkpoint, a publicly available image encoder.
- Specifically, it leverages the “shape optimized” Vision Transformer (ViT So400m).
- This model is pre-trained on a large scale using contrastive learning with a sigmoid loss, enabling it to process and understand images effectively.
2. Decoder-Only Language Model
- PaliGemma integrates the Gemma-2B model, a publicly available pre-trained language model for the language component.
- As a decoder-only model, it is designed to generate text based on both image and language inputs, allowing for tasks like image captioning or answering questions about an image.
3. Linear Layer Projection
- The output tokens from the SigLIP encoder are linearly projected into the same dimension as the Gemma-2B model’s vocabulary tokens.
- This linear projection ensures that the image and language features can be seamlessly combined and used for downstream tasks.
How Is PaliGemma Trained?
Inspired by the Pathways Language and Image (PaLI-3) models, PaliGemma follows the same training stages. The training stages are as follows:
1. Stage 0: Unimodal Pretraining
- The unimodal components of PaliGemma are pre-trained individually to leverage established training methods.
- No custom unimodal pre-training is performed; publicly available checkpoints are utilized.
- A SigLIP image encoder, specifically the “shape optimized” ViT-So400m model, is smaller yet effective compared to larger models like ViT-G.
- The model adopts the Gemma-2B decoder-only language model, balancing size and performance.
2. Stage 1: Multimodal Pretraining
- This stage combines unimodal models and trains them on various vision-language tasks.
- The focus is on creating a base model that can be fine-tuned well for diverse tasks rather than just aligning modalities.
- The image encoder remains frozen initially to maintain representation quality, although it later learns from tasks that provide valuable signals.
- Training occurs at
224pxresolution with 1 billion examples, aiming to cover a wide array of concepts and languages.
3. Stage 2: Resolution Increase
- The model from Stage 1 is valuable but limited to
224×224pixel resolution, which is insufficient for tasks requiring higher detail. - Two additional checkpoints are trained at resolutions of
448×448and896×896pixels. - Stage 2 emphasizes increasing resolution while retaining the task diversity from Stage 1, with fewer examples but higher information density.
- The text sequence length is increased to
512tokens for tasks that demand detailed input.
4. Stage 3: Transfer
- Stages 1 and 2 produce checkpoints at different resolutions rich in visual knowledge.
- These models need to be fine-tuned for specific tasks to be user-friendly.
- The model can be adapted for various inputs, including multiple images and bounding boxes.
Available Model Checkpoints
Google has released three types of PaliGemma models:
- Pretrained Checkpoints: These are base models trained on large datasets that can be further fine-tuned for specific downstream tasks.
- Mix Checkpoints: These base models have been fine-tuned on various tasks, making them easy to use with general-purpose free-text prompts.
- Fine-Tuned Checkpoints: These base models have been fine-tuned for specific tasks, providing targeted performance for particular applications.
Use Cases of PaliGemma
Keeping vision applications in mind, here are some tasks PaliGemma can be used for:
- Image and Short Video Captioning: Asking the model to generate descriptive captions for pictures or short videos.
- Visual Question Answering: Asking the model to generate relevant answers to specific questions about an image.
- Document Understanding: Asking the model to generate answers to specific questions about the text shown in the image.
- Diagram Understanding: Asking the model to generate answers to specific questions about diagrams shown in the image.
- Object Detection: Asking the model to identify (output bounding box coordinates) and label objects within an image.
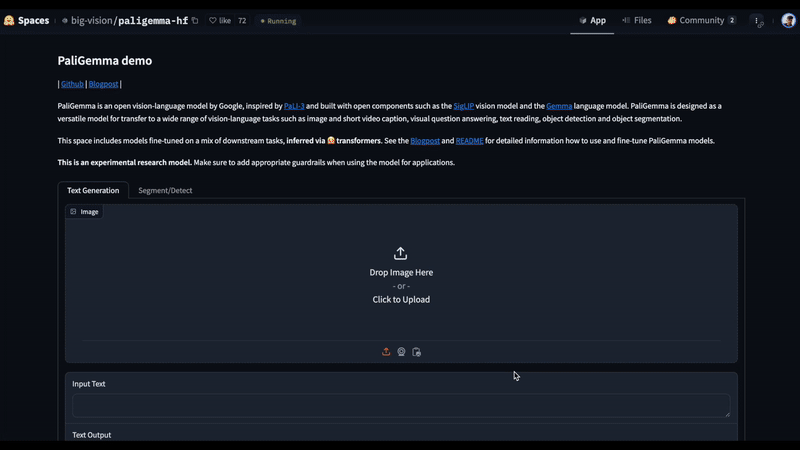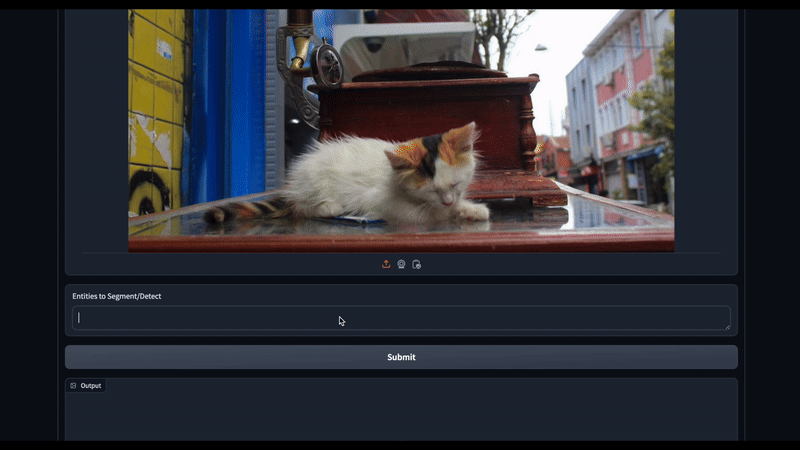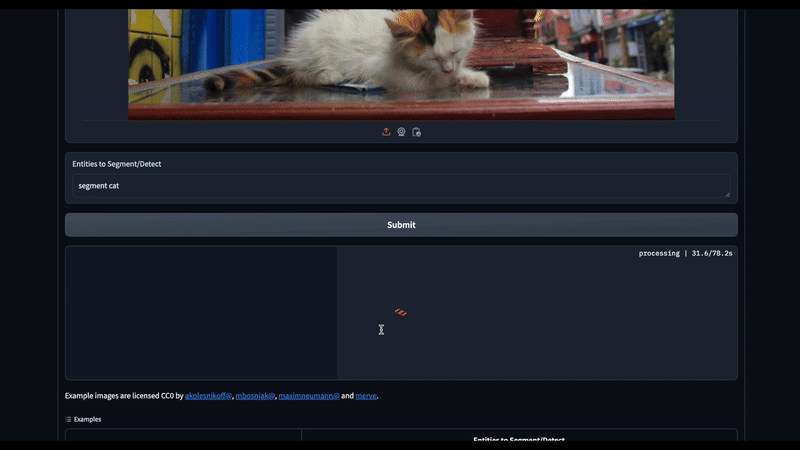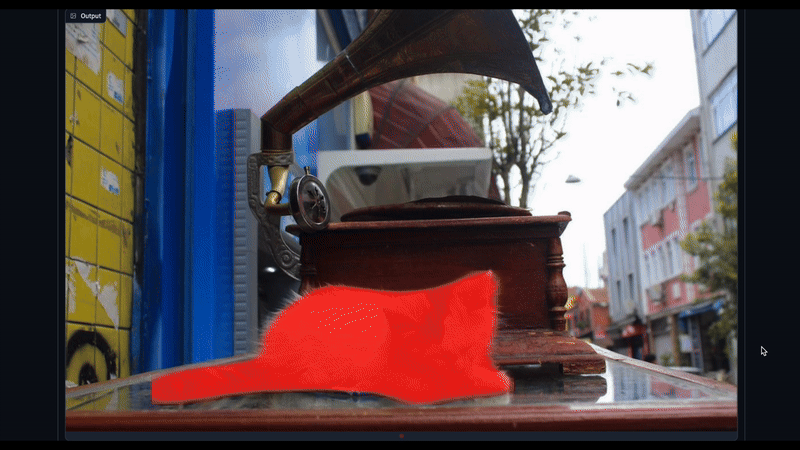
- Object Segmentation: Asking the model to segment (output polygon coordinates) that bound the detected objects in an image (shown in Figure 2).
- Science Question Answering: Asking the model to provide specific answers to questions related to scientific content, using visual inputs like graphs or diagrams in addition to text.
Why PaliGemma?
- PaliGemma’s compact architecture makes it highly effective across multiple tasks while keeping the model size manageable.
- Its key components (e.g., an image encoder, a language decoder, and a projection layer) allow it to handle complex tasks without requiring the massive computational power that larger models might need.
Overall, PaliGemma’s flexibility makes it a powerful tool for any task requiring a deep understanding of images and text.
Inference with PaliGemma
Enough talk. Let us look at how we can use Hugging Face Transformers, to do inference with the model.
Setup and Imports
!pip install -q -U transformers
First, we install the transformers library from Hugging Face, which allows us to use pre-trained models for inference easily.
import torch import requests from PIL import Image from transformers import AutoProcessor, PaliGemmaForConditionalGeneration
We import the necessary libraries.
- We import
torchto provide support for tensor computation. - We import
requeststo send HTTP requests for downloading images from the internet. - We import
ImagefromPILto open, manipulate, and process images. - From the
transformerslibrary, we importAutoProcessorandPaliGemmaForConditionalGenerationto work with the PaliGemma model.
pretrained_model_id = "google/paligemma-3b-pt-224" processor = AutoProcessor.from_pretrained(pretrained_model_id) pretrained_model = PaliGemmaForConditionalGeneration.from_pretrained(pretrained_model_id)
- We define a string variable
pretrained_model_idwith the identifier for the specific PaliGemma pre-trained model (3Bparameters,224pxresolution) from the Hugging Face Model Hub. - We load the pre-trained processor associated with the specified
pretrained_model_id. It is responsible for pre-processing input data (e.g., tokenizing text or resizing images) and post-processing the model’s outputs (e.g., decoding). - We load the pre-trained PaliGemma model associated with the specified
pretrained_model_id. It is responsible for generating text outputs based on the inputs (image + text) provided.
Run Inference
prompt = "What is behind the cat?"
image_file = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/cat.png?download=true"
raw_image = Image.open(requests.get(image_file, stream=True).raw)
inputs = processor(raw_image.convert("RGB"), prompt, return_tensors="pt")
output = pretrained_model.generate(**inputs, max_new_tokens=20)
print(processor.decode(output[0], skip_special_tokens=True)[len(prompt):])
- We define the
promptas a text input. - We assign the URL of an image to the variable
image_file. The image is hosted on the Hugging Face dataset repository. - We download the image from the URL using the
requestlibrary and open it using thePILlibrary (Image.open()).stream=Trueensures that the file is streamed in memory rather than downloaded fully before opening. - We process the image (
raw_image) and the text prompt (prompt) using theAutoProcessor. We convert the image to RGB format and prepare the inputs for the model.return_tensors="pt"returns the processed data as PyTorch tensors to be compatible with the pre-trained model. - We generate the model’s
outputbased on the processed inputs, with a maximum of20new tokens in the response. It tries to answer the prompt using the image and text as inputs. - We decode the generated output from the model using
processor.decode, converting the tokenized output back into human-readable text.skip_special_tokens=Trueremoves any special tokens that the model might have generated (e.g., start/end tokens).[len(prompt):]slices the response to exclude the prompt itself, printing only the generated answer.
In Figure 3, you can see the image and the generated output.
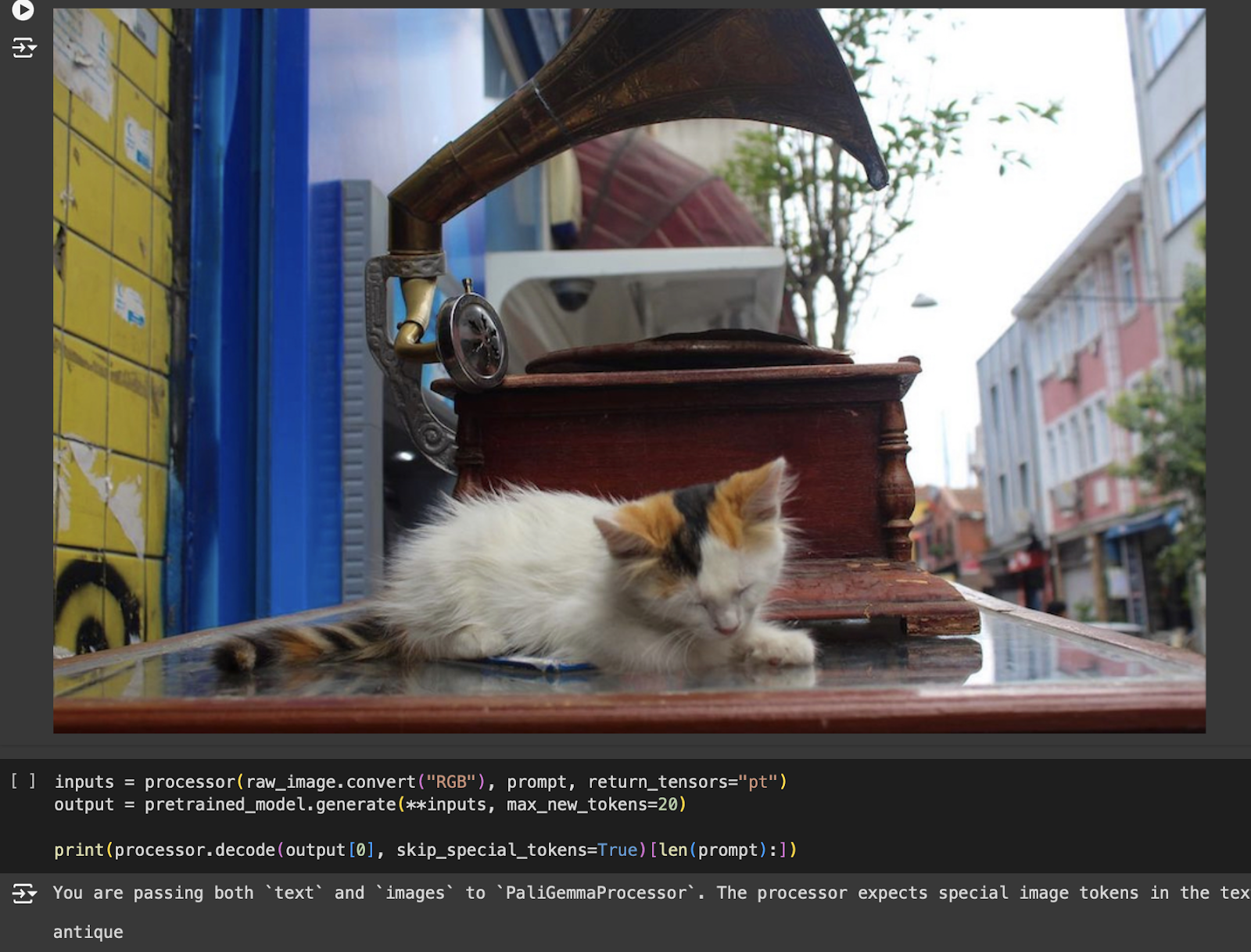
The generated answer is not accurate. Now, we will show the steps to fine-tune the model for improved results.
Fine-Tuning PaliGemma on a Custom Dataset
Fine-tuning involves adapting a pre-trained model to a specific task or dataset by training it further on new data. This allows the model to specialize and improve performance on domain-specific tasks.
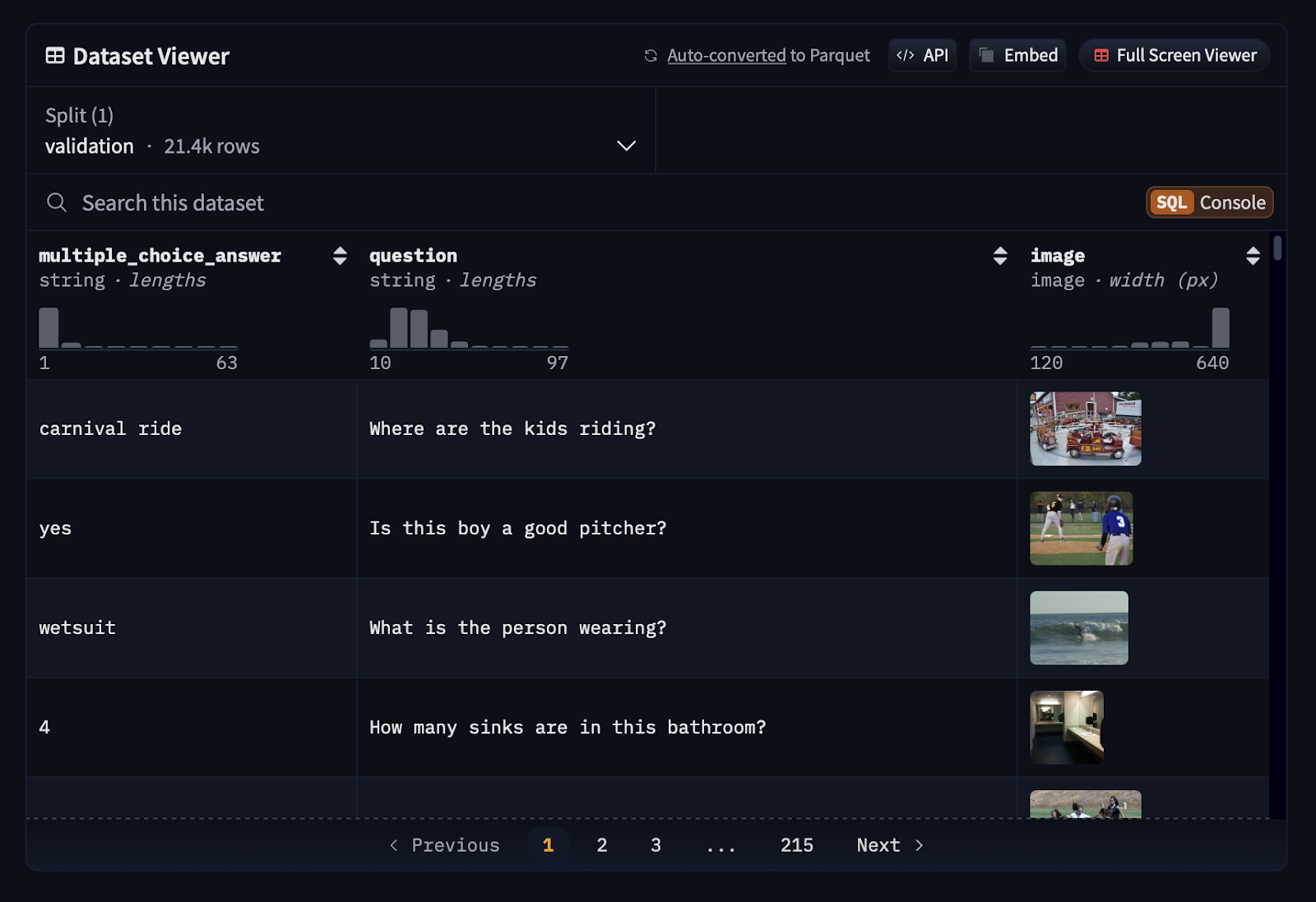
In our case, we fine-tune the PaliGemma model on a custom visual question answering dataset, vqav2-small, a small subset of the VQA v2.0 dataset hosted by Merve on Hugging Face.
The vqav2_small dataset (shown in Figure 4) consists of 21.4k examples with three features: image, question, and multiple_choice_answer. The model is trained using a combination of the image and question as input, while the multiple_choice_answer serves as the label for fine-tuning.
Setup and Imports
!pip install -q -U transformers datasets peft bitsandbytes
We install the following libraries:
transformers: for using pre-trained models.datasets: to load and process datasets.peft: to fine-tune large models with fewer parameters efficiently.bitsandbytes: to optimize the training of large models through quantization.
from huggingface_hub import notebook_login
notebook_login()
This allows us to log in to our Hugging Face account.
- We import the
notebook_loginfunction from thehuggingface_hublibrary, which authenticates our Hugging Face account in a notebook environment. - We run
notebook_login, which prompts us to enter a Hugging Face API token to log in to access Hugging Face models and datasets.
import torch import requests from PIL import Image from datasets import load_dataset from peft import get_peft_model, LoraConfig from transformers import Trainer from transformers import TrainingArguments from transformers import PaliGemmaProcessor from transformers import BitsAndBytesConfig from transformers import AutoProcessor, PaliGemmaForConditionalGeneration
We import several essential libraries to facilitate our tasks.
First, we import a torch library for tensor computation support. Next, requests allows us to send HTTP requests for downloading images from the internet, while PIL is utilized to open, manipulate, and process these images.
The load_dataset function from the datasets library enables us to load datasets for training and evaluation.
Additionally, we import get_peft_model and LoraConfig from the peft library; the former helps create a model with parameter-efficient fine-tuning (PEFT) techniques, and the latter configures the Low-Rank Adaptation (LoRA) method for fine-tuning.
To simplify the training and evaluation of models, we bring in the Trainer class and set the training configuration using TrainingArguments from the transformers library.
The PaliGemmaProcessor is essential for preparing inputs for the PaliGemma model and managing preprocessing tasks (e.g., tokenization).
For optimizing memory usage and computational efficiency during the training of large models, we utilize BitsAndBytesConfig to configure options related to quantization.
Finally, the AutoProcessor automatically selects the appropriate processor based on the model, and the PaliGemmaForConditionalGeneration class is used to generate outputs based on the input data.
device = "cuda" model_id = "google/paligemma-3b-pt-224"
Next, we define a string variable device as cuda. This will enable the model to run on a GPU, speeding up the training and evaluation computational speed.
We also define a string variable model_id with the identifier for the specific PaliGemma pre-trained model (3B parameters, 224px resolution) from the Hugging Face Model Hub.
Load and Inspect the Dataset
ds = load_dataset('merve/vqav2-small')
- We use the
load_datasetfunction from thedatasetslibrary to load the datasetmerve/vqav2-small, hosted by Merve on Hugging Face.
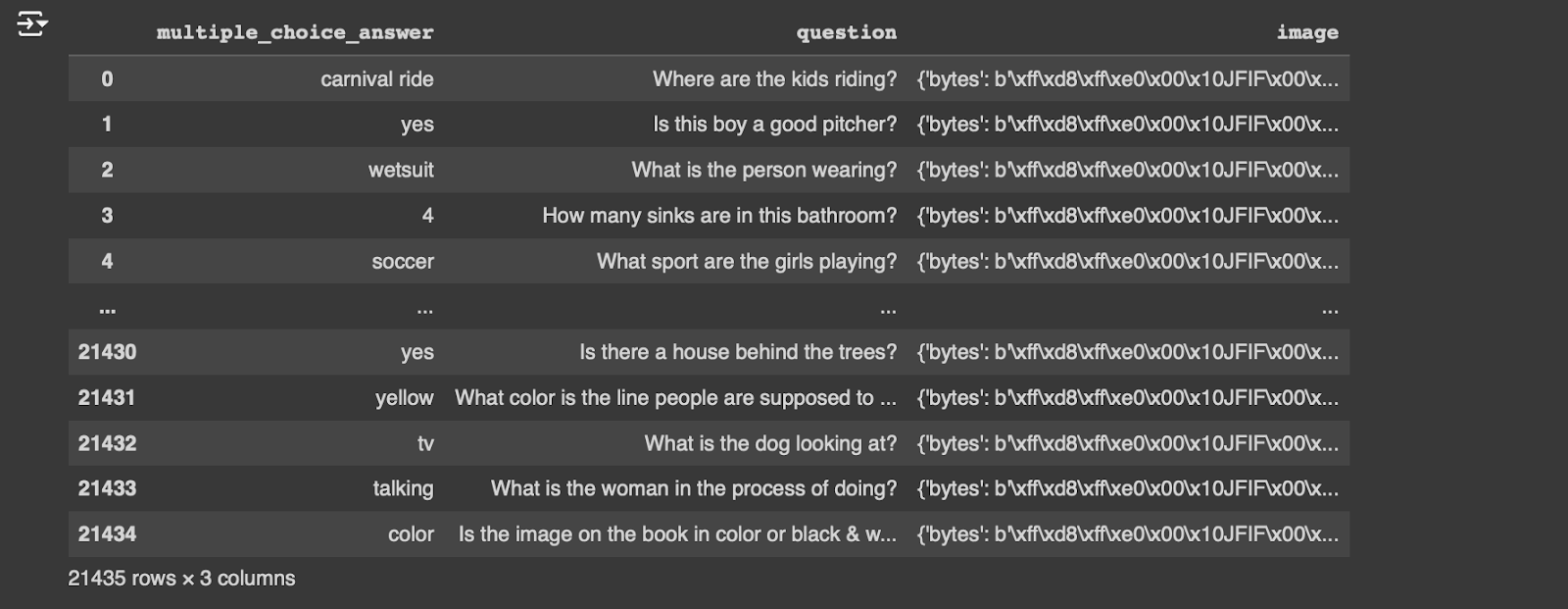
ds_dataframe = ds['validation'].to_pandas()
Here, we use the to_pandas() method to convert the dataset to a dataframe (shown in Figure 5) to inspect a few of the rows and columns.
Split the Dataset into Train-Test
We split the dataset into training and testing sets for fine-tuning and inference.
split_ds = ds["validation"].train_test_split(test_size=0.05) train_ds = split_ds["train"] test_ds = split_ds["test"]
- We use the
train_test_splitmethod to split the dataset into training and testing sets. We specify atest_sizeof0.05, meaning that 5% of the data will be allocated for testing.
Preprocess the Dataset
We preprocess the dataset to convert it into a suitable format for model fine-tuning, which includes processing text, images, and labels.
processor = PaliGemmaProcessor.from_pretrained(model_id)
def collate_fn(examples):
texts = [f"<image> <bos> answer {example['question']}" for example in examples]
labels= [example['multiple_choice_answer'] for example in examples]
images = [example["image"].convert("RGB") for example in examples]
tokens = processor(text=texts, images=images, suffix=labels,
return_tensors="pt", padding="longest")
tokens = tokens.to(torch.bfloat16).to(device)
return tokens
We initialize the PaliGemmaProcessor using a pre-trained model specified by model_id and define a custom collate_fn function to preprocess a list of examples from the dataset. This function performs several key tasks:
- Formats each example’s question into a text prompt with special tokens.
- Extracts the multiple-choice answers and stores them in a list called
labels. - Converts each image in the examples to RGB format, collecting them in a list named
images. - Next, we utilize the
PaliGemmaProcessorto tokenize the text, images, and labels, returning the processed data as PyTorch tensors with padding to the longest sequence. - For efficiency, we convert the processed tensors to the
bfloat16data type and move them to the specified device, which is the GPU in this case. - Finally, the function returns the processed
tokens, making them ready for input into the model.
Fine-Tune Only the Text Decoder
Since our dataset closely resembles the ones PaliGemma was initially trained on, there’s no need to fine-tune the image encoder or the multimodal projector. We will focus on fine-tuning only the text decoder.
model = PaliGemmaForConditionalGeneration.from_pretrained(model_id, torch_dtype=torch.bfloat16).to(device)
for param in model.vision_tower.parameters():
param.requires_grad = False
for param in model.multi_modal_projector.parameters():
param.requires_grad = False
First, we load the PaliGemma model using the model ID (model_id) provided. We convert the model’s parameters to the bfloat16 data type for more efficient memory use and computation. We also transfer the model to the device (GPU here).
Next, we loop through all the model’s vision_tower parameters and set requires_grad = False to freeze the parameters, preventing them from being updated during fine-tuning.
Finally, we loop through all the model’s multi_modal_projector parameters and set requires_grad = False to freeze the parameters, preventing them from being updated during fine-tuning.
Using the QLoRA Technique
Now, we set up the configuration to use the Quantized Low-Rank Adapters (QLoRA) technique for model optimization and fine-tuning.
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
lora_config = LoraConfig(
r=8,
target_modules=["q_proj", "o_proj", "k_proj", "v_proj", "gate_proj", "up_proj", "down_proj"],
task_type="CAUSAL_LM",
)
BitsAndBytesConfig
load_in_4bit=True: enables 4-bit quantization to reduce memory consumption.bnb_4bit_quant_type="nf4": specifies the quantization type, here using"nf4"for more efficient weight representation.bnb_4bit_compute_dtype=torch.bfloat16: sets the computation to usebfloat16to improve computational efficiency during training.
LoraConfig
r=8: sets the rank (number of dimensions) for low-rank adaptation.target_modules=["q_proj", "o_proj", "k_proj", "v_proj", "gate_proj", "up_proj", "down_proj"]: specifies which modules to fine-tune within the model’s language tower (e.g., query, key, and value projections).task_type="CAUSAL_LM": defines the task type for the fine-tuning, in this case, causal language modeling.
model = PaliGemmaForConditionalGeneration.from_pretrained(model_id, quantization_config=bnb_config, device_map={"":0})
model = get_peft_model(model, lora_config)
model.print_trainable_parameters() # trainable params: 11,298,816 || all params: 2,934,765,296 || trainable%: 0.3850
First, we load the pre-trained PaliGemma model with the specified model ID. We apply the bnb_config for 4-bit quantization to optimize memory usage. We use device_map={"":0} to map the model to the default device (typically GPU 0).
Next, we use get_peft_model to apply the LoRA (Low-Rank Adaptation) configuration to fine-tune the model efficiently by updating only specific parts of the model (e.g., language tower).
Finally, for verification, we print the total number of trainable parameters (11,298,816) out of the total model parameters (2,934,765,296), showing that only 0.385% of the model is being fine-tuned for efficiency.
Define the Training Arguments
We define the training arguments for fine-tuning a model using the Hugging Face Trainer API, including configurations for the number of epochs, batch size, learning rate, optimizer, logging, and saving checkpoints.
args=TrainingArguments(
num_train_epochs=2,
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
warmup_steps=2,
learning_rate=2e-5,
weight_decay=1e-6,
adam_beta2=0.999,
logging_steps=100,
optim="adamw_hf",
save_strategy="steps",
save_steps=1000,
save_total_limit=1,
output_dir="finetuned_paligemma_vqav2_small",
bf16=True,
dataloader_pin_memory=False
report_to=["tensorboard"]
)
We set up the training configuration by specifying key parameters such as training for 2 epochs, a batch size of 4 per device, and accumulating gradients over 4 steps to simulate a larger batch size.
To ensure stability during early training, we include 2 warmup_steps and use a learning_rate of 2e-5 with a small weight_decay of 1e-6 for regularization. The adamw_hf optimizer is configured with an adam_beta2 value of 0.999, and metrics are logged every 100 steps using logging_steps.
We also save model checkpoints every 1,000 steps (as specified by save_steps), limiting the number of saved checkpoints to 1 (using save_total_limit). The checkpoints are stored in the finetuned_paligemma_vqav2_small directory, as defined in output_dir.
Additionally, we enable bfloat16 precision (bf16=True) to reduce memory usage and disable data loader memory pinning (dataloader_pin_memory=False), which can help decrease memory overhead in specific environments.
Finally, we set report_to=["tensorboard"] to log the training progress.
Start the Training
We initialize a Hugging Face Trainer with the specified model, training dataset, data collation function, and training arguments, then start the fine-tuning process.
trainer = Trainer(
model=model,
train_dataset=train_ds,
data_collator=collate_fn,
args=args
)
trainer.train()
We create an instance of the Hugging Face Trainer class with the following parameters:
- The pre-trained
modelto be fine-tuned. - The dataset (
train_ds) and data collator (collate_fn) to handle batching and preprocessing. - Training configurations from
argsto specify details (e.g., batch size and learning rate).
Finally, we start the training process (shown in Figure 6) using trainer.train().
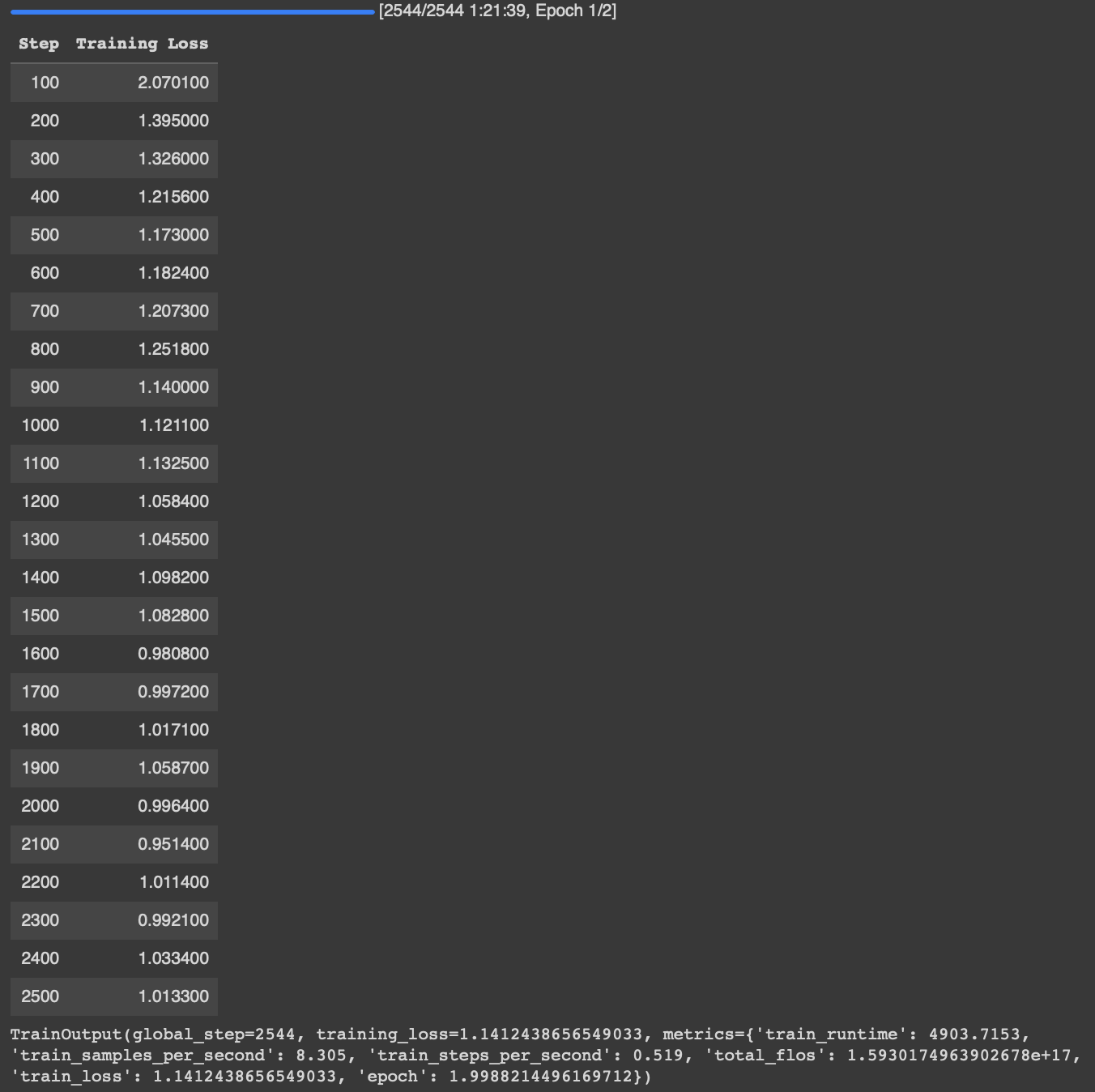
The training progress is also visualized on TensorBoard here.
Push the Fine-Tuned PaliGemma Model to the Hub
We upload our fine-tuned model, which includes the safetensors file and model configurations, to the Hub so that it can be used later for inference. The fine-tuned model can be found here: Hugging Face Model Hub.
trainer.push_to_hub()
We use the push_to_hub() method of the Trainer class to accomplish this.
Inference with Fine-Tuned PaliGemma Model
Now, we can use our uploaded fine-tuned PaliGemma model to run inference on examples from our test split dataset.
Setup
pretrained_model_id = "google/paligemma-3b-pt-224" finetuned_model_id = "pyimagesearch/finetuned_paligemma_vqav2_small" processor = AutoProcessor.from_pretrained(pretrained_model_id) model = PaliGemmaForConditionalGeneration.from_pretrained(finetuned_model_id)
We first initialize the processor with pretrained_model_id to handle input preprocessing. Next, we load the model using finetuned_model_id, which points to our fine-tuned version of PaliGemma.
Run Inference
prompt = "What is behind the cat?"
image_file = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/cat.png?download=true"
raw_image = Image.open(requests.get(image_file, stream=True).raw)
inputs = processor(raw_image.convert("RGB"), prompt, return_tensors="pt")
output = model.generate(**inputs, max_new_tokens=20)
print(processor.decode(output[0], skip_special_tokens=True)[len(prompt):])
Here, we have the same inference code as before. We define the text prompt and download the image using requests, then open it with the PIL library (Image.open()). After that, we preprocess the image and prompt using the processor, generate a response from the model, and finally decode the output to get the answer.
When we ran inference with the pre-trained model, the output generated was antique (see Figure 3), which wasn’t entirely accurate. However, after fine-tuning, the model generated a gramophone (shown in Figure 7), which is a more accurate result.

Now, let’s run inference on some examples from the test split dataset and observe the results.
From this point, the inference logic remains the same, with the only difference being that the images are now sourced from the test split dataset, and the input text prompt is to "Describe the image."
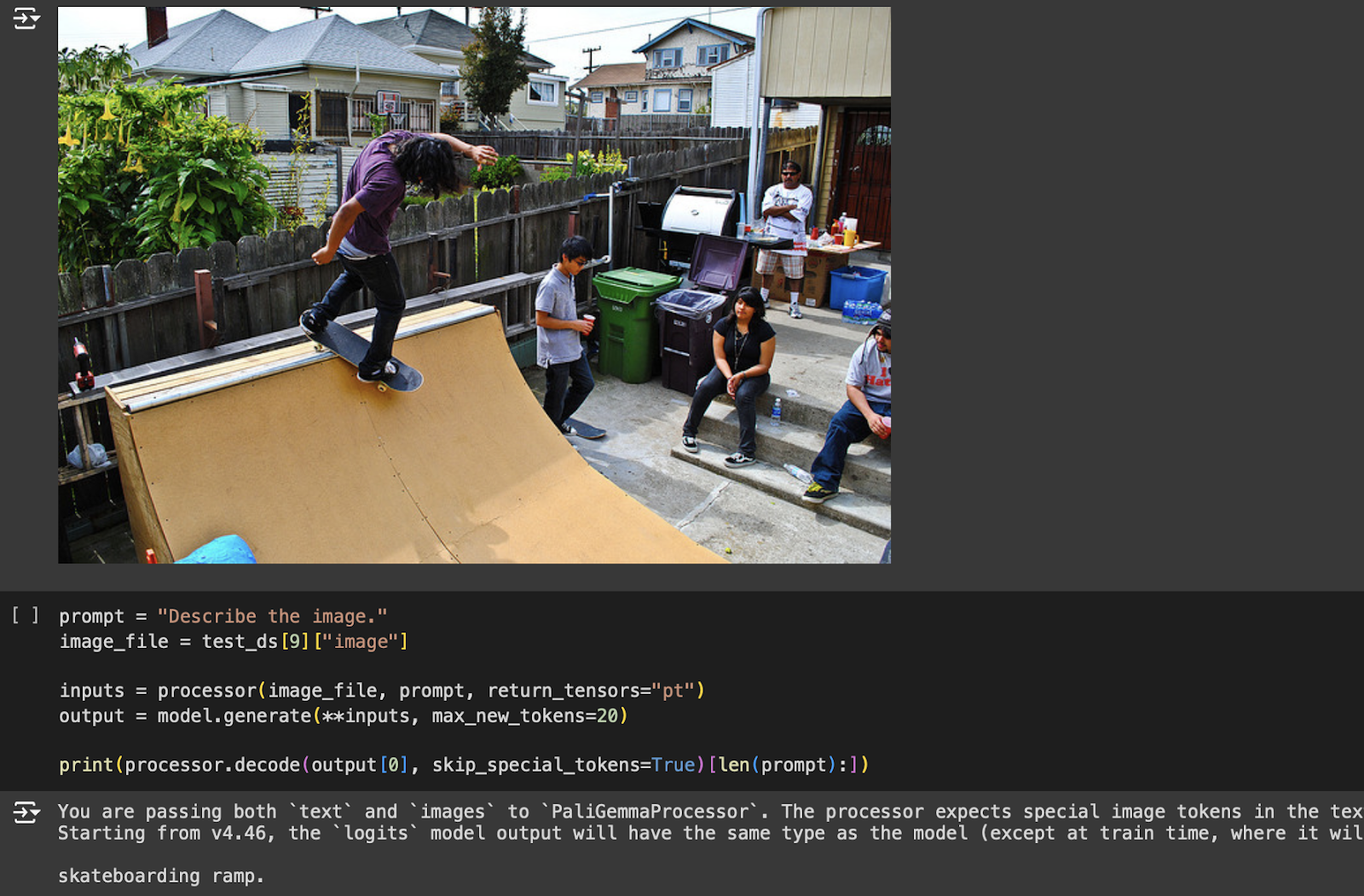
prompt = "Describe the image." image_file = test_ds[9]["image"] inputs = processor(image_file, prompt, return_tensors="pt") output = model.generate(**inputs, max_new_tokens=20) print(processor.decode(output[0], skip_special_tokens=True)[len(prompt):])
The generated output from the fine-tuned model (Figure 8) is: skateboarding ramp.
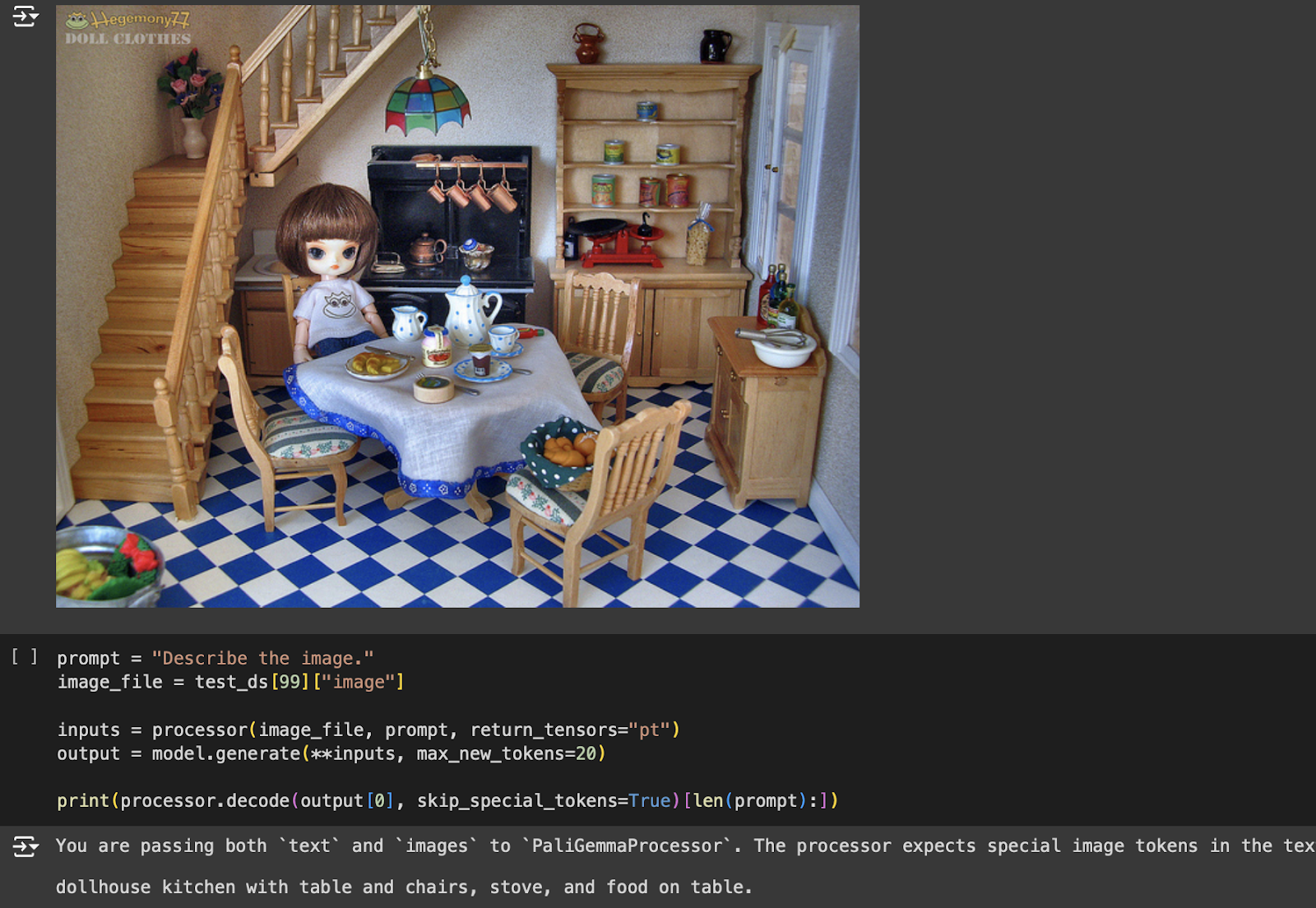
prompt = "Describe the image." image_file = test_ds[99]["image"] inputs = processor(image_file, prompt, return_tensors="pt") output = model.generate(**inputs, max_new_tokens=20) print(processor.decode(output[0], skip_special_tokens=True)[len(prompt):])
The generated output from the fine-tuned model (Figure 9) is: dollhouse kitchen with table and chairs, stove, and food on table.
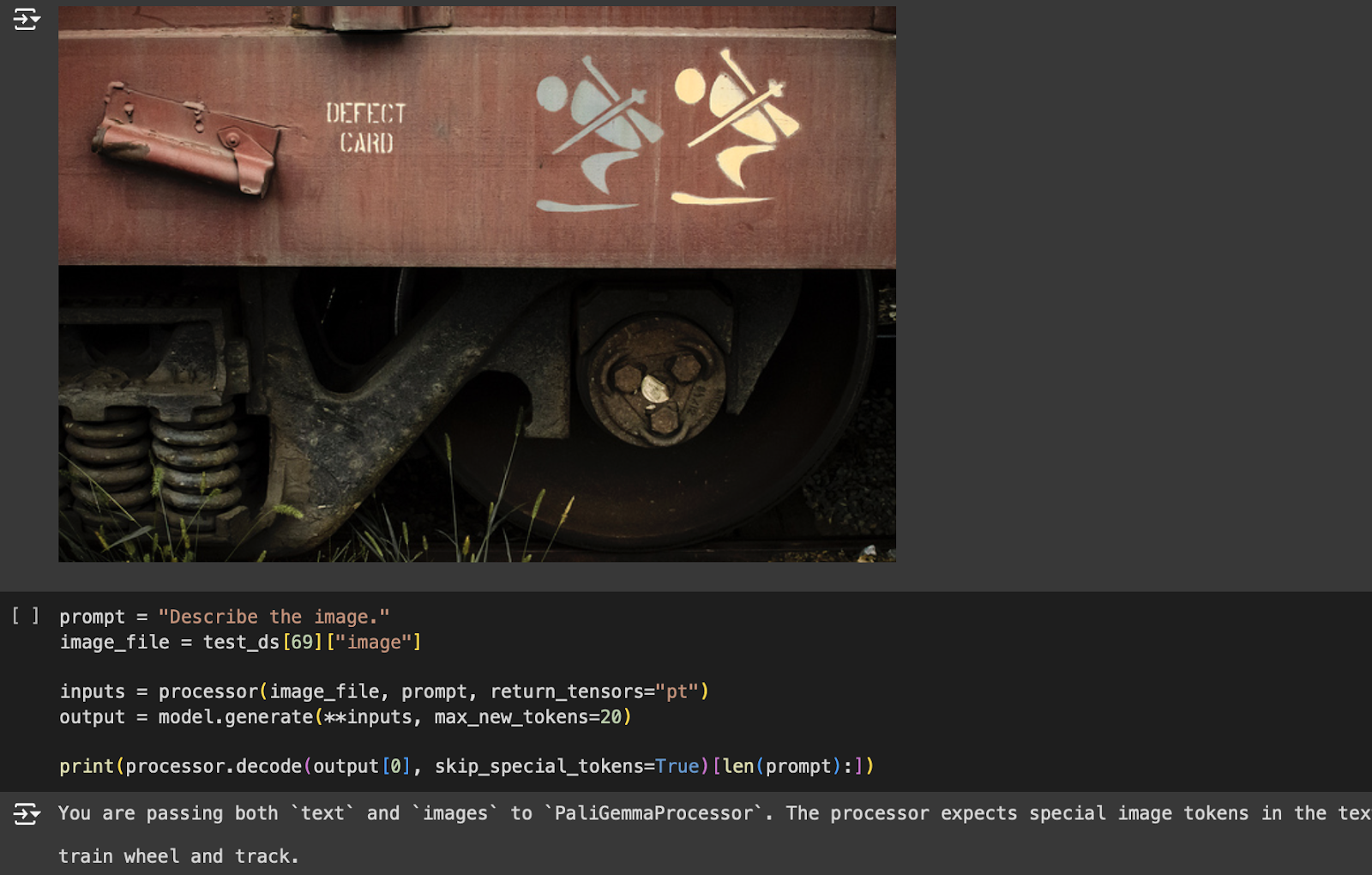
prompt = "Describe the image." image_file = test_ds[69]["image"] inputs = processor(image_file, prompt, return_tensors="pt") output = model.generate(**inputs, max_new_tokens=20) print(processor.decode(output[0], skip_special_tokens=True)[len(prompt):])
The generated output from the fine-tuned model (Figure 10) is: train wheel and track.
What’s next? We recommend PyImageSearch University.
86 total classes • 115+ hours of on-demand code walkthrough videos • Last updated: October 2024
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you’re serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you’ll find:
- ✓ 86 courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this tutorial, we covered the following key points:
- Overview of PaliGemma: We explored PaliGemma, a vision-language model (VLM), discussing its architecture, training methods, and available model checkpoints. We highlighted its use cases and benefits, emphasizing its efficiency and performance.
- Initial Inference Results: We observed that the generated output from the pre-trained model lacked accuracy.
- Fine-Tuning with QLoRA: We demonstrated how to fine-tune the pre-trained model using the QLoRA technique to enhance its performance.
- Improved Inference Results: After fine-tuning, we ran inference with the updated model and noted significant improvements in the accuracy and relevance of the generated outputs.
References
- Understanding PaliGemma in 50 Minutes or Less
- PaliGemma Paper
- PaliGemma — Google’s Cutting-Edge Open Vision Language Model
- Introducing PaliGemma: Google’s Latest Visual Language Model
Citation Information
Thakur, P. “Fine Tune PaliGemma with QLoRA for Visual Question Answering,” PyImageSearch, P. Chugh, S. Huot, K. Kidriavsteva, and R. Raha, eds., 2024, https://pyimg.co/1qgi9
@incollection{Thakur_2024_PaliGemma,
author = {Piyush Thakur},
title = {{Fine Tune PaliGemma with QLoRA for Visual Question Answering}},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Susan Huot and Kseniia Kidriavsteva and Ritwik Raha},
year = {2024},
url = {https://pyimg.co/1qgi9},
}
To download the source code to this post (and be notified when future tutorials are published here on PyImageSearch), simply enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you’ll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!
The post Fine Tune PaliGemma with QLoRA for Visual Question Answering appeared first on PyImageSearch.
“}]] [[{“value”:”Table of Contents Fine Tune PaliGemma with QLoRA for Visual Question Answering What Is PaliGemma? What Is a Vision-Language Model? Architecture of PaliGemma How Is PaliGemma Trained? Available Model Checkpoints Use Cases of PaliGemma Why PaliGemma? Inference with PaliGemma Setup…
The post Fine Tune PaliGemma with QLoRA for Visual Question Answering appeared first on PyImageSearch.”}]]  Read More Computer Vision, Fine Tuning, Gemma, PEFT, QLoRA, Transformers, Tutorial, Vision-Language Model, ai model optimization, clip, cross-attention, custom dataset, fine-tuning, gemma, hugging face, hugging face trainer, inference, machine-learning, multimodal, paligemma, pre-trained models, qlora, siglip, transformers, tutorial, vision models, vision-language model, vlm
Read More Computer Vision, Fine Tuning, Gemma, PEFT, QLoRA, Transformers, Tutorial, Vision-Language Model, ai model optimization, clip, cross-attention, custom dataset, fine-tuning, gemma, hugging face, hugging face trainer, inference, machine-learning, multimodal, paligemma, pre-trained models, qlora, siglip, transformers, tutorial, vision models, vision-language model, vlm