[[{“value”:”

Graph Convolutional Networks (GCNs) have become integral in analyzing complex graph-structured data. These networks capture the relationships between nodes and their attributes, making them indispensable in domains like social network analysis, biology, and chemistry. By leveraging graph structures, GCNs enable node classification and link prediction tasks, fostering advancements in scientific and industrial applications.
Large-scale graph training presents significant challenges, particularly in maintaining efficiency and scalability. The irregular memory access patterns caused by graph sparsity and the extensive communication required for distributed training make it difficult to achieve optimal performance. Moreover, partitioning graphs into subgraphs for distributed computation creates imbalanced workloads and increased communication overhead, further complicating the training process. Addressing these challenges is crucial for enabling the training of GCNs on massive datasets.
Existing methods for GCN training include mini-batch and full-batch approaches. Mini-batch training reduces memory usage by sampling smaller subgraphs, allowing computations to fit within limited resources. However, this method often sacrifices accuracy as it needs to retain the complete structure of the graph. While preserving the graph’s structure, full-batch training faces scalability issues due to increased memory and communication demands. Most current frameworks are optimized for GPU platforms, with a limited focus on developing efficient solutions for CPU-based systems.
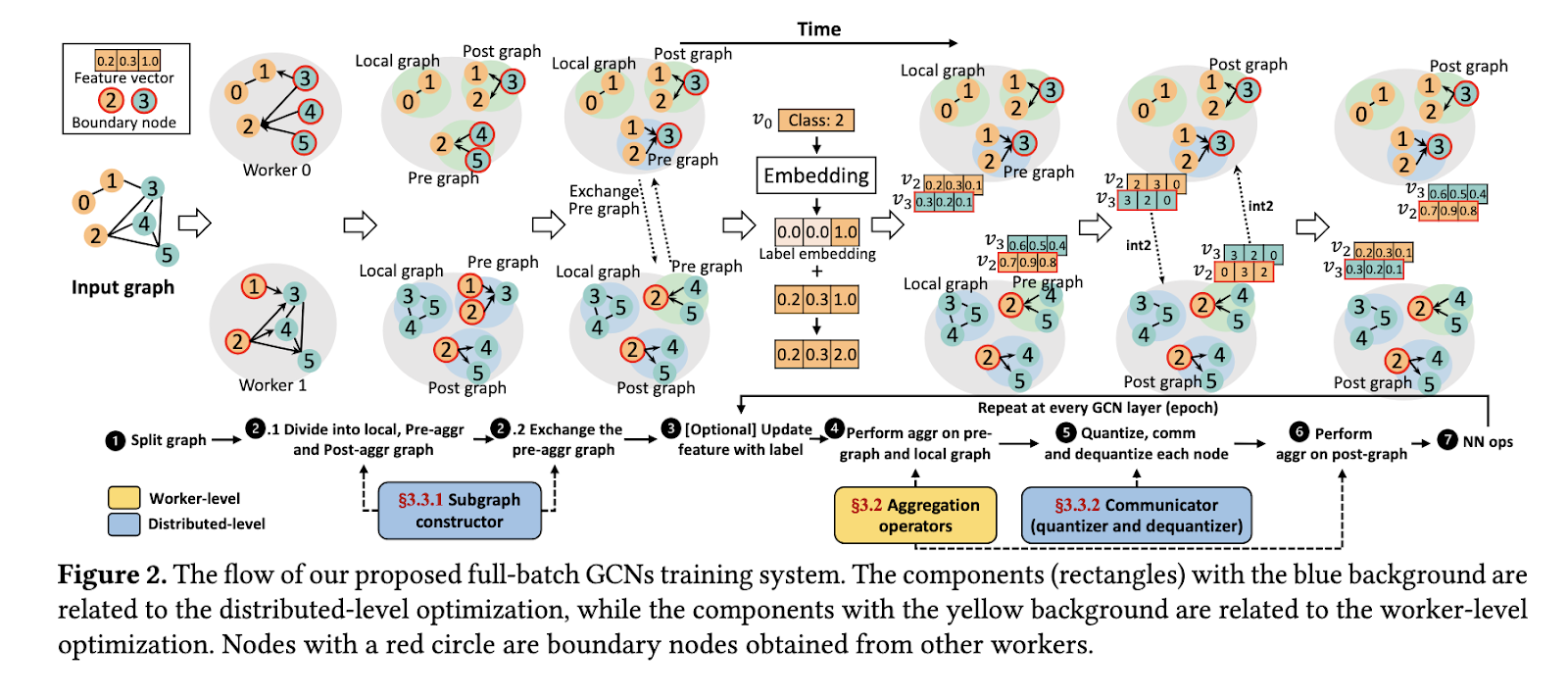
The research team, including collaborators from the Tokyo Institute of Technology, RIKEN, the National Institute of Advanced Industrial Science and Technology, and Lawrence Livermore National Laboratory, have introduced a novel framework called SuperGCN. This system is tailored for CPU-powered supercomputers, addressing scalability and efficiency challenges in GCN training. The framework bridges the gap in distributed graph learning by focusing on optimized graph-related operations and communication reduction techniques.
SuperGCN leverages several innovative techniques to enhance its performance. The framework employs optimized CPU-specific implementations of graph operators, ensuring efficient memory usage and balanced workloads across threads. The researchers proposed a hybrid aggregation strategy that uses the minimum vertex cover algorithm to categorize edges into pre- and post-aggregation sets, reducing redundant communications. Furthermore, the framework incorporates Int2 quantization to compress messages during communication, significantly lowering data transfer volumes without compromising accuracy. Label propagation is used alongside quantization to mitigate the effects of reduced precision, ensuring convergence and maintaining high model accuracy.
The performance of SuperGCN was evaluated on datasets such as Ogbn-products, Reddit, and the large-scale Ogbn-papers100M, demonstrating remarkable improvements over existing methods. The framework achieved up to a sixfold speedup compared to Intel’s DistGNN on Xeon-based systems, with performance scaling linearly as the number of processors increased. On ARM-based supercomputers like Fugaku, SuperGCN scaled to over 8,000 processors, showcasing unmatched scalability for CPU platforms. The framework achieved processing speeds comparable to GPU-powered systems, requiring significantly less energy and cost. On Ogbn-papers100M, SuperGCN attained an accuracy of 65.82% with label propagation enabled, outperforming other CPU-based methods.
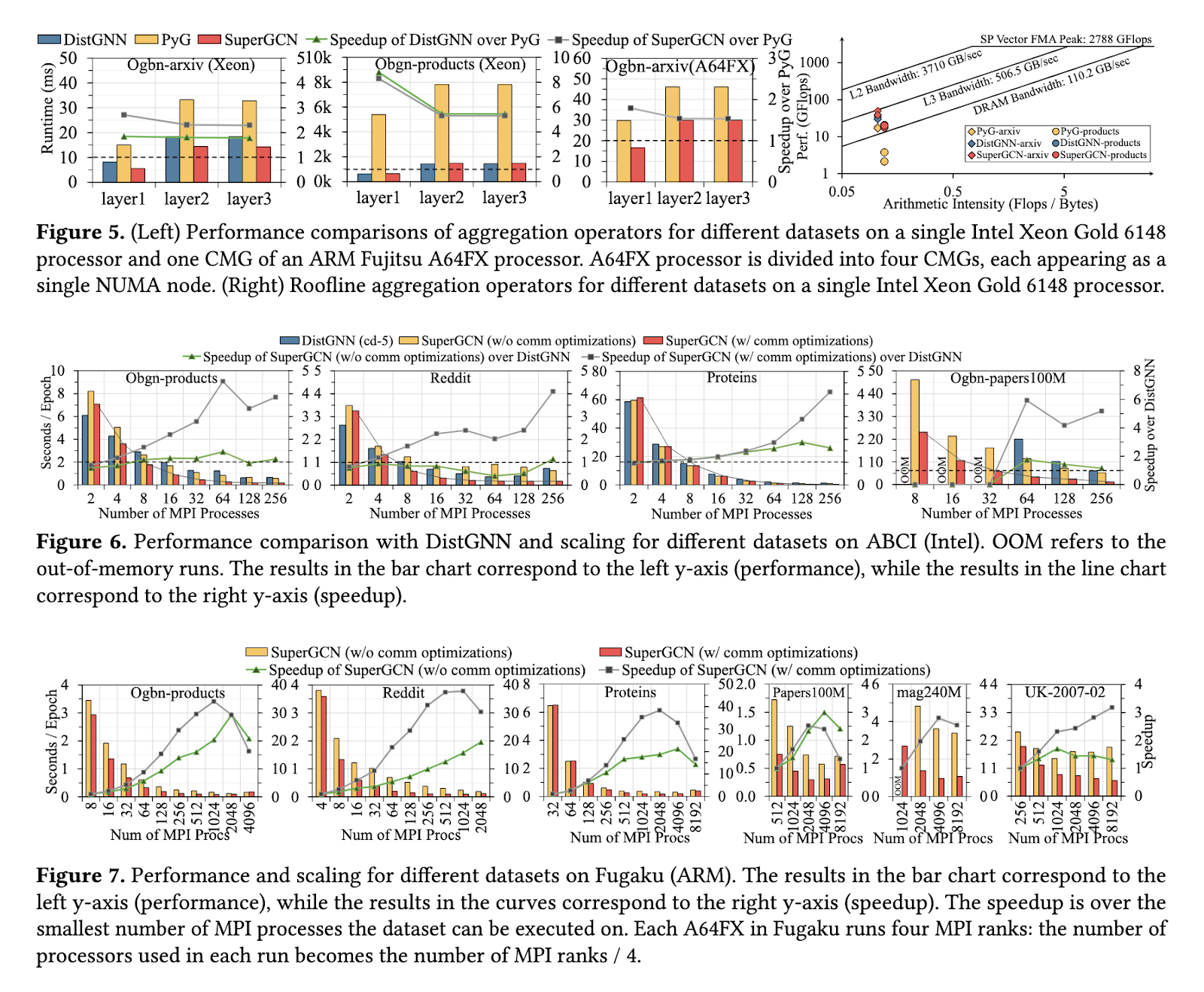
By introducing SuperGCN, the researchers addressed critical bottlenecks in distributed GCN training. Their work demonstrates that efficient, scalable solutions are achievable on CPU-powered platforms, providing a cost-effective alternative to GPU-based systems. This advancement marks a significant step in enabling large-scale graph processing while preserving computational and environmental sustainability.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.

 ‘
‘The post This AI Paper Introduces SuperGCN: A Scalable and Efficient Framework for CPU-Powered GCN Training on Large Graphs appeared first on MarkTechPost.
“}]] [[{“value”:”Graph Convolutional Networks (GCNs) have become integral in analyzing complex graph-structured data. These networks capture the relationships between nodes and their attributes, making them indispensable in domains like social network analysis, biology, and chemistry. By leveraging graph structures, GCNs enable node classification and link prediction tasks, fostering advancements in scientific and industrial applications. Large-scale graph
The post This AI Paper Introduces SuperGCN: A Scalable and Efficient Framework for CPU-Powered GCN Training on Large Graphs appeared first on MarkTechPost.”}]] Read More AI Paper Summary, AI Shorts, Applications, Artificial Intelligence, Editors Pick, Machine Learning, Staff, Tech News, Technology