[[{“value”:”

The static knowledge base and hallucination-creating inaccuracy or fabrication of information are two common issues with large language models (LLMs). The parametric knowledge within LLMs is inherently static, making it challenging to provide up-to-date information in real-time scenarios. Retrieval-augmented generation (RAG) addresses the problem of integrating external, real-time information to enhance accuracy and relevance. However, noise, ambiguity, and deviation in intent in user queries are often a hindrance to effective document retrieval. Query rewriting plays an important role in refining such inputs to ensure that retrieved documents more closely match the actual intent of the user.
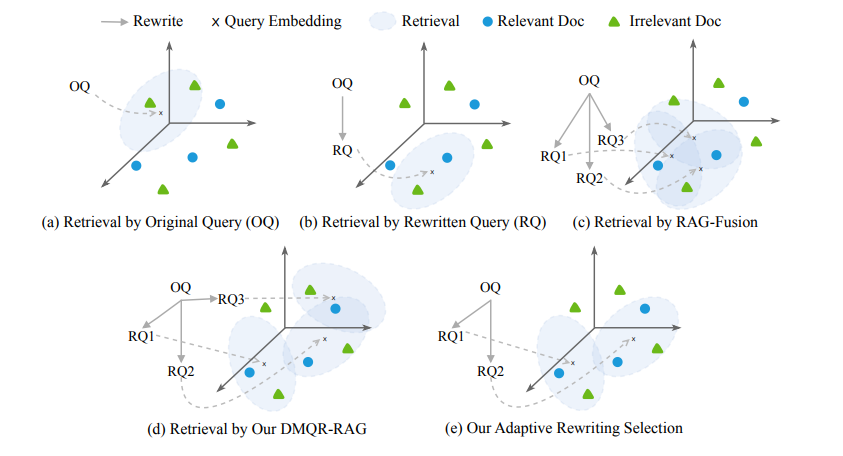
Current methods for query rewriting in RAG systems can be broadly categorized into two- training-based and prompt-based approaches. Training-based methods involve supervised fine-tuning using annotated data or reinforcement learning, while prompt-based methods use prompt engineering to guide LLMs in specific rewriting strategies. While prompt-based methods are cost-effective, they often lack generalization and diversity. Multi-strategy rewriting addresses these issues by combining different prompt-based techniques to handle diverse query types and enhance retrieval diversity.
To address this, researchers from Renmin University of China, Southeast University, Beijing Jiaotong University, and Kuaishou Technology have proposed DMQR-RAG, a Diverse Multi-Query Rewriting framework. This framework uses four strategies of rewriting at different levels of information to improve performance over baseline approaches. Moreover, an adaptive strategy selection method is proposed to minimize the number of rewrites while optimizing overall performance.
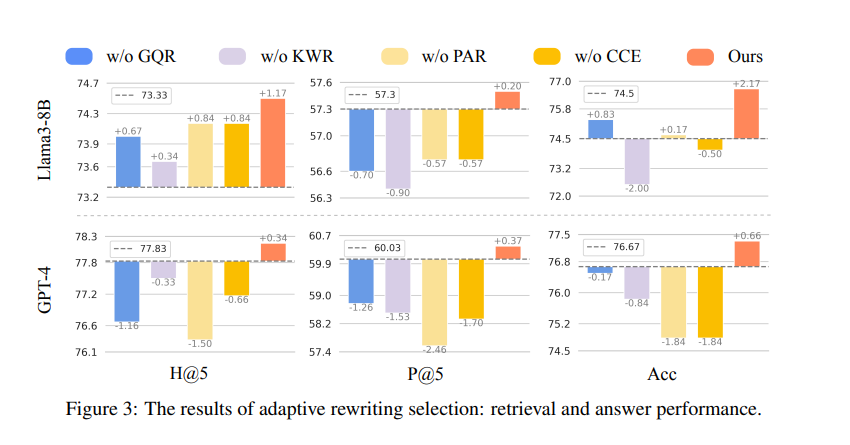
The DMQR-RAG framework introduced four rewriting strategies: GQR, KWR, PAR, and CCE. GQR refines a query by omitting noise and maintaining relevant information to produce the actual query. Similarly, KWR is used to extract keywords that search engines prefer. PAR constructs a pseudo answer to broaden the query with useful information, while CCE concentrates on finding key information where detailed queries were extracted.
The framework also supports a strategy selection method of adaptive rewriting strategy that dynamically determines the best strategies for any given query, avoiding superfluous rewrites and optimizing retrieval performance. In both academic and industrial environments, through a wide range of experiments, these proposed methods validate that the processes may lead to significant improvement in document retrieval and final response quality. The approach outperforms baseline methods, achieving approximately 10% performance gains and demonstrating particular effectiveness for smaller language models by reducing unnecessary rewrites and minimizing retrieval noise. The proposed method demonstrated superior performance across datasets like AmbigNQ, HotpotQA, and FreshQA, achieving higher recall (H@5) and precision (P@5) compared to baselines. For example, DMQR-RAG improved P@5 by up to 14.46% on FreshQA and surpassed RAG-Fusion in most metrics. It also showed versatility by performing well with smaller LLMs and proving effective in real-world industry scenarios.
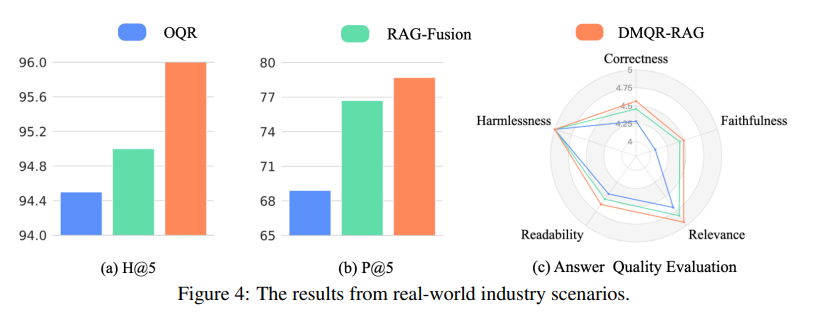
In conclusion, DMQR-RAG solved the problem of improving relevance-aggregate retrieval systems, developing a diverse multi-query rewriting framework, and an adaptive strategy selection method. Its improvements include enhanced relevance and diversity of retrieved documents. These innovations lead to better overall performance in retrieval-augmented generation. DMQR-RAG proves effective in real-world scenarios, improving query retrieval across 15 million user queries. It increases hit and precision rates while enhancing response correctness and relevance without sacrificing other performance metrics.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.

 ‘
‘The post DMQR-RAG: A Diverse Multi-Query Rewriting Framework Designed to Improve the Performance of Both Document Retrieval and Final Responses in RAG appeared first on MarkTechPost.
“}]] [[{“value”:”The static knowledge base and hallucination-creating inaccuracy or fabrication of information are two common issues with large language models (LLMs). The parametric knowledge within LLMs is inherently static, making it challenging to provide up-to-date information in real-time scenarios. Retrieval-augmented generation (RAG) addresses the problem of integrating external, real-time information to enhance accuracy and relevance. However,
The post DMQR-RAG: A Diverse Multi-Query Rewriting Framework Designed to Improve the Performance of Both Document Retrieval and Final Responses in RAG appeared first on MarkTechPost.”}]] Read More AI Paper Summary, AI Shorts, Applications, Artificial Intelligence, Editors Pick, Information Retrieval, Staff, Tech News, Technology