[[{“value”:”

The rapid advancement of large language models (LLMs) has exposed critical infrastructure challenges in model deployment and communication. As models scale in size and complexity, they encounter significant storage, memory, and network bandwidth bottlenecks. The exponential growth of model sizes creates computational and infrastructural strains, particularly in data transfer and storage mechanisms. Current models like Mistral demonstrate the magnitude of these challenges, generating over 40 PBs of transferred information monthly and requiring extensive network resources. The storage requirements for model checkpoints and distributed updates can accumulate hundreds or thousands of times the original model size.
Existing research in model compression has developed multiple approaches to reduce model sizes while attempting to maintain performance. Four primary model-compression methods have emerged: pruning, network architecture modification, knowledge distillation, and quantization. Among these techniques, quantization remains the most popular, deliberately trading accuracy for storage efficiency and computational speed. These methods share the goal of reducing model complexity, but each approach introduces inherent limitations. Pruning can potentially remove critical model information, distillation may not perfectly capture original model nuances, and quantization introduces entropy variations. Researchers have also begun exploring hybrid approaches that combine multiple compression techniques.
Researchers from IBM Research, Tel Aviv University, Boston University, MIT, and Dartmouth College have proposed ZipNN, a lossless compression technique specifically designed for neural networks. This method shows great potential in model size reduction, achieving significant space savings across popular machine learning models. ZipNN can compress neural network models by up to 33%, with some instances showing reductions exceeding 50% of the original model size. When applied to models like Llama 3, ZipNN outperforms vanilla compression techniques by over 17%, improving compression and decompression speeds by 62%. The method has the potential to save an ExaByte of network traffic monthly from large model distribution platforms like Hugging Face.
ZipNN’s architecture is designed to enable efficient, parallel neural network model compression. The implementation is primarily written in C (2000 lines) with Python wrappers (4000 lines), utilizing the Zstd v1.5.6 library and its Huffman implementation. The core methodology revolves around a chunking approach that allows independent processing of model segments, making it particularly suitable for GPU architectures with multiple concurrent processing cores. The compression strategy operates at two granularity levels: chunk level and byte-group level. To enhance user experience, the researchers implemented seamless Hugging Face Transformers library integration, enabling automatic model decompression, metadata updates, and local cache management with optional manual compression controls.
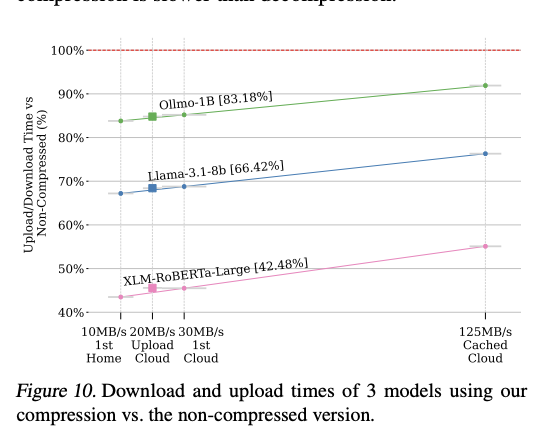
Experimental evaluations of ZipNN were conducted on an Apple M1 Max machine with 10 cores and 64GB RAM, running macOS Sonoma 14.3. Model compressibility significantly influenced performance variations, with the FP32 regular model having approximately 3/4 non-compressible content, compared to 1/2 in the BF16 model and even less in the clean model. Comparative tests with LZ4 and Snappy revealed that while these alternatives were faster, they provided zero compression savings. Download speed measurements showed interesting patterns: initial downloads ranged from 10-40 MBps, while cached downloads exhibited significantly higher speeds of 40-130 MBps, depending on the machine and network infrastructure.
The research on ZipNN highlights a critical insight into the contemporary landscape of machine learning models: despite exponential growth and overparametrization, significant inefficiencies persist in model storage and communication. The study reveals substantial redundancies in model architectures that can be systematically addressed through targeted compression techniques. While current trends favor large models, the findings suggest that considerable space and bandwidth can be saved without compromising model integrity. By tailoring compression to neural network architectures, improvements can be achieved with minimal computational overhead, offering a solution to the growing challenges of model scalability and infrastructure efficiency.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 60k+ ML SubReddit.
 [Must Attend Webinar]: ‘Transform proofs-of-concept into production-ready AI applications and agents’ (Promoted)
[Must Attend Webinar]: ‘Transform proofs-of-concept into production-ready AI applications and agents’ (Promoted)
The post ZipNN: A New Lossless Compression Method Tailored to Neural Networks appeared first on MarkTechPost.
“}]] [[{“value”:”The rapid advancement of large language models (LLMs) has exposed critical infrastructure challenges in model deployment and communication. As models scale in size and complexity, they encounter significant storage, memory, and network bandwidth bottlenecks. The exponential growth of model sizes creates computational and infrastructural strains, particularly in data transfer and storage mechanisms. Current models like
The post ZipNN: A New Lossless Compression Method Tailored to Neural Networks appeared first on MarkTechPost.”}]] Read More AI Paper Summary, AI Shorts, Applications, Artificial Intelligence, Editors Pick, Machine Learning, Staff, Tech News, Technology