[[{“value”:”

Retrieval Augmented Generation is an efficient solution for knowledge-intensive tasks that improves the quality of outputs and makes it more deterministic with minimal hallucinations. However, RAG outputs can still be noisy and may fail to respond appropriately to complex queries. To address this limitation, iterative retrieval updates have been introduced, which update re-retrieval results to satisfy dynamic information needs. Primarily introduced to tackle the challenge of knowledge sparsity and requirements during complex query solutions, it focuses on two W’s – When and What (to retrieve). Despite its potential, most existing methods rely heavily on human-oriented rules and prompts. This dependence demands significant human effort and limits LLMs’ decision-making capabilities, effectively spoon-feeding them instead of enabling autonomy.
To overcome these challenges, researchers from the Chinese Academy of Sciences have proposed Auto-RAG, an autonomous iterative retrieval-augmented system that prioritizes LLM decision-making capabilities. It includes a multi-turn dialogue between LLM and the retriever. In contrast to conventional results, AutoRag uses the reasoning abilities of LLMs for planning, knowledge extraction, query rewriting, and iteratively querying the retriever until the desired solution is provided to the user.Auto-RAG introduces a framework for the automatic synthesis of reasoning-based instructions, enabling LLMs to make decisions independently within the iterative RAG process. These instructions allow the automation of LLM decision-making in an iterative RAG process at a minimal cost.
The authors conceptualized the iterative process as a multi-turn interaction between LLM and retriever until the retriever is confident of information sufficiency. After each iteration, the model reasons back and adjusts the retrieval approach to seek the appropriate information. The central part of this pipeline is undeniably the reasoning part. The authors add three different reasoning points constituting a Chain of Thought for retrieval.
- Retrieval Planning: This is the first step, focusing on primary data retrieval pertinent to the query. This phase also includes assessing if the model needs more retrievals or if the acquired information is sufficient.
- Information Extraction: The second step makes the information more query-specific. In this step, LLM extracts relevant information from the retrieved document for final answer curation. It includes a summarization method of vital information to mitigate inaccuracies.
- Answer Inference: The pipeline’s final step includes LLM to formulate the final decision based on the extracted information.
Furthermore, AutoRag is highly dynamic because it automatically adjusts the number of iterations depending on the complexity of the query, saving one the hassle of computations. Another upside to this framework is that it is user-friendly and written in natural language, which provides a high degree of interpretability. Now that we have discussed what Auto-Rag does and why it is vital to improving model performance, let us look at how this pipeline performed on actual tests.
The research team fine-tune LLMs under a supervised setting to make retrieval autonomous. They synthesized 10,000 reasoning-based instructions for this case derived from two datasets-Natural Questions and 2WikiMultihopQA. The models used in this pipeline were Llama-3-8B-Instruct (for reasoning synthesis ) and Qwen1.5-32B-Chat( for rewritten queries). The data was fine-tuned on the Llama Model for its human-free retrieval efficiency.
To test the efficacy of the proposed method, authors benchmarked the Auto Rag framework on six representative benchmarks with open domain and multi-hop answering Datasets. Multi-Hop QA had various subparts and multiple queries, making applying standard RAG methods inefficient. The results validated AutoRag’s claims with excellent results in data-constrained training. A zero-shot prompting method was chosen as the baseline for RAG without the pipeline. The authors also compared Auto Rag with some multi-chain engagement and CoT-based methods, where Auto Rag surpassed the other models.
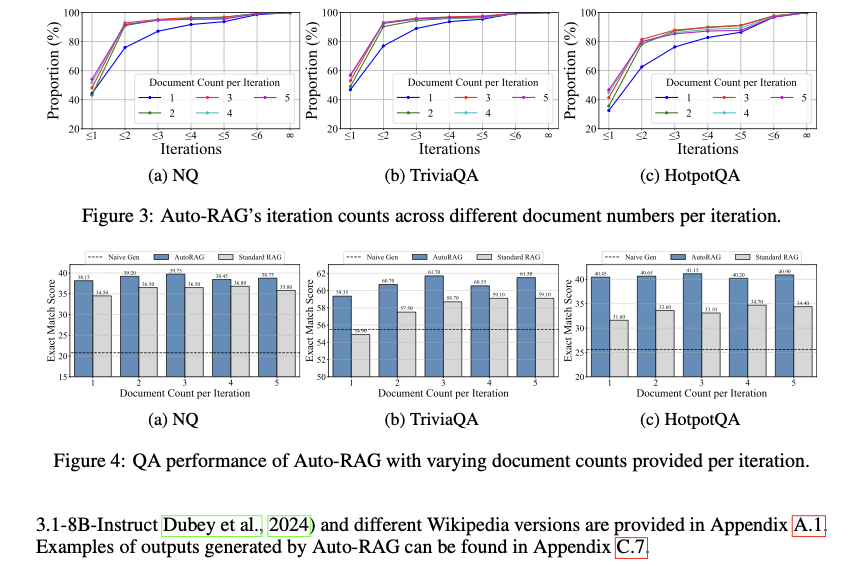
Conclusion: Auto Rag achieved superior performance on six benchmarks by automating the multi-step retrieval process task with enhanced reasoning in conventional RAG setups. Not only did it deliver better results, but it also self-adjusted the queries in the retrieval process to work only until you get the information.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 60k+ ML SubReddit.
 [Must Attend Webinar]: ‘Transform proofs-of-concept into production-ready AI applications and agents’ (Promoted)
[Must Attend Webinar]: ‘Transform proofs-of-concept into production-ready AI applications and agents’ (Promoted)
The post Auto-RAG: An Autonomous Iterative Retrieval Model Centered on the LLM’s Powerful Decision-Making Capabilities appeared first on MarkTechPost.
“}]] [[{“value”:”Retrieval Augmented Generation is an efficient solution for knowledge-intensive tasks that improves the quality of outputs and makes it more deterministic with minimal hallucinations. However, RAG outputs can still be noisy and may fail to respond appropriately to complex queries. To address this limitation, iterative retrieval updates have been introduced, which update re-retrieval results to
The post Auto-RAG: An Autonomous Iterative Retrieval Model Centered on the LLM’s Powerful Decision-Making Capabilities appeared first on MarkTechPost.”}]] Read More AI Paper Summary, AI Shorts, Applications, Artificial Intelligence, Editors Pick, Language Model, Staff, Tech News, Technology