[[{“value”:”

Language Agents (LAs) have recently become the focal point of research and development because of the significant advancement in large language models (LLMs). LLMs have demonstrated significant advancements in understanding and producing human-like text. LLMs perform various tasks with great performance and accuracy. Through well-designed prompts and carefully selected in-context demonstrations, LLM-based agents, such as Language Agents, can be endowed with different environmental interaction and task-solving mechanisms.
Current agents typically use fixed mechanisms or a list of mechanisms activated in some predetermined order, greatly limiting their adaptability to the many different potential structures of solutions to tasks. Existing Language Agents (LAs) use other mechanisms, such as Reflexion with its Reflection mechanism for refinement and ReAct with External-Augmentation for evidence-based solutions. However, these approaches depend on manual mechanism activation, restricting adaptability in dynamic environments. ReAct, Reflexion, and Multi-Agent Debate have been developed to improve autonomous task-solving. Still, they require labor-intensive prompt designs and rely on proprietary, opaque foundation models, which hinder research into intrinsic mechanisms. Open-source LLMs have been adapted into LAs through imitation fine-tuning, using high-reward trajectories from golden rationales or distilled outputs from ChatGPT. This adaptation allowed smaller models to develop skills such as reasoning and planning. While these LAs are promising, they don’t support interactive self-improvement, so exploration fine-tuning to enhance adaptability is highly sought after.
To mitigate this, researchers from the University of Chinese Academy of Sciences and the Institute of Automation proposed Adaptive Language Agent Mechanism Activation Learning with Self-Exploration (ALAMA), which optimized mechanism activation adaptability without relying on expert models.
ALAMA introduced a unified agent framework (UniAct) to integrate diverse mechanisms as specific actions within a shared action space, enabling adaptive mechanism activation. The method leveraged self-exploration to generate diverse training trajectories, reducing reliance on manual annotation and expensive proprietary models.
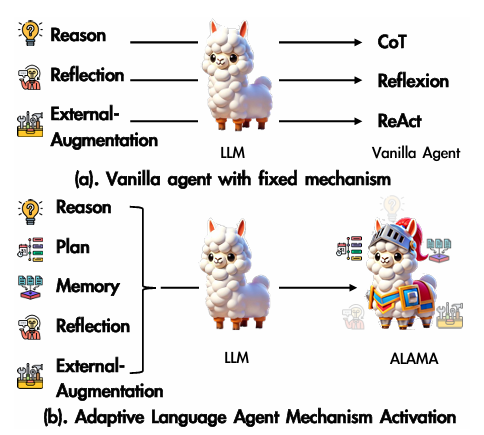
The study focused on equipping an agent with five essential mechanisms—Reason, Plan, Memory, Reflection, and External-Augmentation—each enhancing task-solving performance through various prompts and demonstrations. ALAMA utilized the UniAct framework to unify diverse mechanisms into a shared action space. By leveraging self-exploration, the agent generated diverse solution trajectories, reducing the reliance on manual annotation. Through Implicit Mechanism Activation Optimization (IMAO) and Mechanism Activation Adaptability Optimization (MAAO), the agent was fine-tuned to adaptively activate appropriate mechanisms based on task characteristics, enhancing its ability to solve tasks with mechanism sensitivity.

The experiment used GPT-3.5-turbo0125 as the baseline and MetaLlama3-8B-Instruct for ALAMA. Datasets included GSM8K and HotpotQA for training and testing, with NumGLUE, SVAMP, TriviaQA, and Bamboogle for evaluating generalization. Several baselines were selected for comparison: (1) Fixed single mechanisms, with manually constructed in-context demonstrations to activate different mechanisms; (2) Average performance across mechanisms; (3) Majority Voting, which selected the most consistent answer; and (4) Self-Adapt Consistency, applying the self-consistency technique to ALAMA.
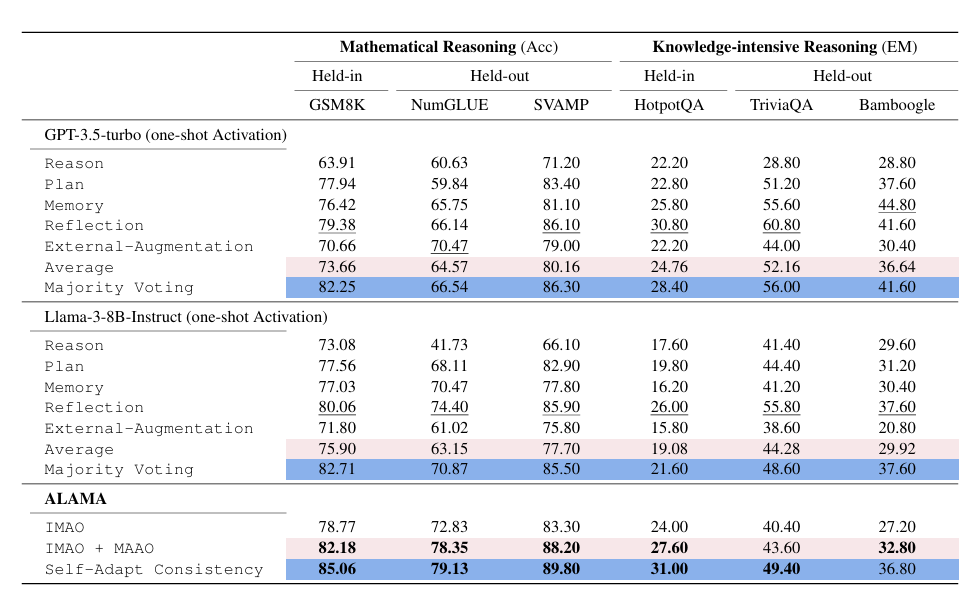
The method showed notable improvements over traditional fixed manual mechanisms, particularly when combined with supervised learning (IMAO) and preference learning (MAAO), leading to better performance on tasks like GSM8K and HotpotQA. ALAMA’s adaptability was driven by behavior contrastive learning, enabling the model to choose the most suitable mechanism for each task. It was also less demanding regarding training data than prior methods but still delivered state-of-the-art results, making it more data-efficient. ALAMA performed very well on held-out tasks and showed better zero-shot performance than previous models, including majority voting-based ones. The method showed better results when more than one mechanism was used instead of a single mechanism.
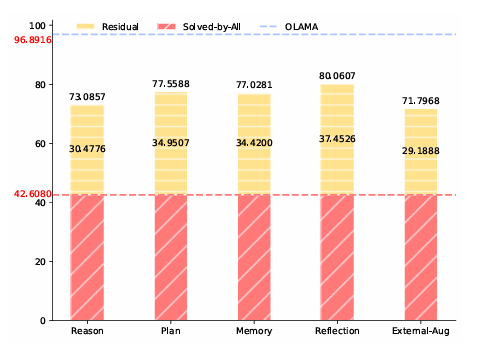
In conclusion, the proposed method greatly improved agent performance through mechanism sensitivity optimization and self-exploration. Despite its limitations, such as not addressing multi-mechanism activation and restricted data evaluation, the proposed method laid a foundation for future research to explore complex mechanism combinations and integrate diverse data to enhance adaptive learning capabilities!
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 60k+ ML SubReddit.
 [Partner with us]: ‘Next Magazine/Report- Open Source AI in Production’
[Partner with us]: ‘Next Magazine/Report- Open Source AI in Production’
The post Exploring Adaptivity in AI: A Deep Dive into ALAMA’s Mechanisms appeared first on MarkTechPost.
“}]] [[{“value”:”Language Agents (LAs) have recently become the focal point of research and development because of the significant advancement in large language models (LLMs). LLMs have demonstrated significant advancements in understanding and producing human-like text. LLMs perform various tasks with great performance and accuracy. Through well-designed prompts and carefully selected in-context demonstrations, LLM-based agents, such as
The post Exploring Adaptivity in AI: A Deep Dive into ALAMA’s Mechanisms appeared first on MarkTechPost.”}]] Read More AI Paper Summary, AI Shorts, Applications, Artificial Intelligence, Editors Pick, Staff, Tech News, Technology