[[{“value”:”

Neural networks have become foundational tools in computer vision, NLP, and many other fields, offering capabilities to model and predict complex patterns. The training process is at the center of neural network functionality, where network parameters are adjusted iteratively to minimize error through optimization techniques like gradient descent. This optimization occurs in high-dimensional parameter space, making it challenging to decipher how the initial configuration of parameters influences the final trained state.
Although progress has been made in studying these dynamics, questions about the dependency of final parameters on their initial values and the role of input data still need to be answered. Researchers seek to determine whether specific initializations lead to unique optimization pathways or if the transformations are governed predominantly by other factors like architecture and data distribution. This understanding is essential for designing more efficient training algorithms and enhancing the interpretability and robustness of neural networks.
Prior studies have offered insights into the low-dimensional nature of neural network training. Research shows that parameter updates often occupy a relatively small subspace of the overall parameter space. For example, projections of gradient updates onto randomly oriented low-dimensional subspaces tend to have minimal effects on the network’s final performance. Other studies have observed that most parameters stay close to their initial values during training, and updates are often approximately low-rank over short intervals. However, these approaches fail to fully explain the relationship between initialization and final states or how data-specific structures influence these dynamics.
Researchers from EleutherAI introduced a novel framework for analyzing neural network training through the Jacobian matrix to address the above problems. This method examines the Jacobian of trained parameters concerning their initial values, capturing how initialization shapes the final parameter states. By applying singular value decomposition to this matrix, the researchers decomposed the training process into three distinct subspaces:
- Chaotic Subspace
- Bulk Subspace
- Stable Subspace
This decomposition provides a detailed understanding of the influence of initialization and data structure on training dynamics, offering a new perspective on neural network optimization.
The methodology involves linearizing the training process around the initial parameters, allowing the Jacobian matrix to map how small perturbations to initialization propagate during training. Singular value decomposition revealed three distinct regions in the Jacobian spectrum. The chaotic region, comprising approximately 500 singular values significantly greater than one, represents directions where parameter changes are amplified during training. The bulk region, with around 3,000 singular values near one, corresponds to dimensions where parameters remain largely unchanged. The stable region, with roughly 750 singular values less than one, indicates directions where changes are dampened. This structured decomposition highlights the varying influence of parameter space directions on training progress.
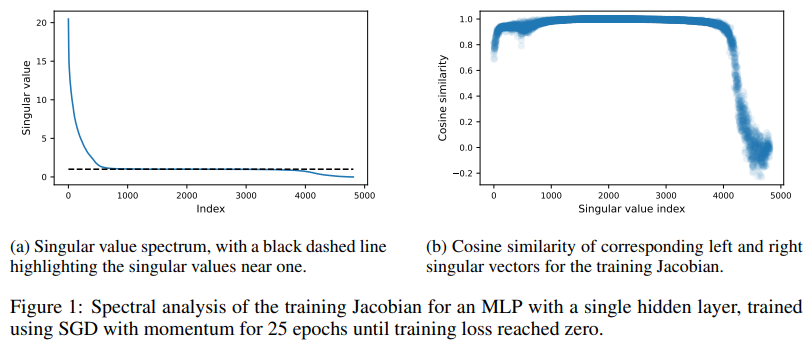
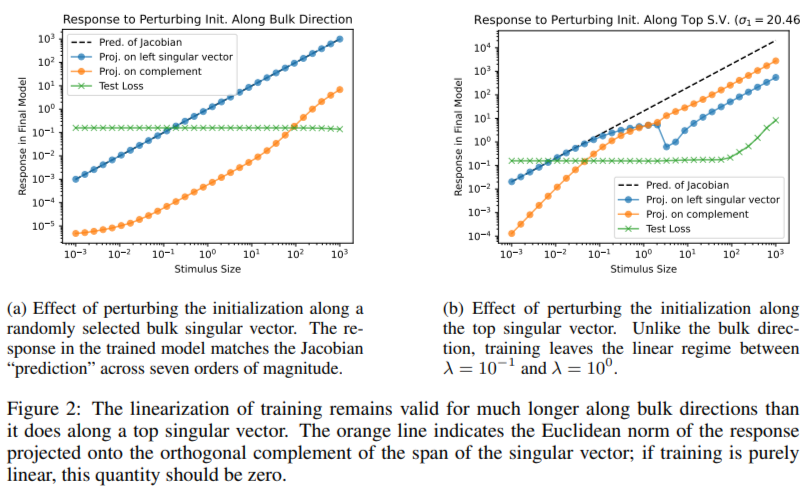
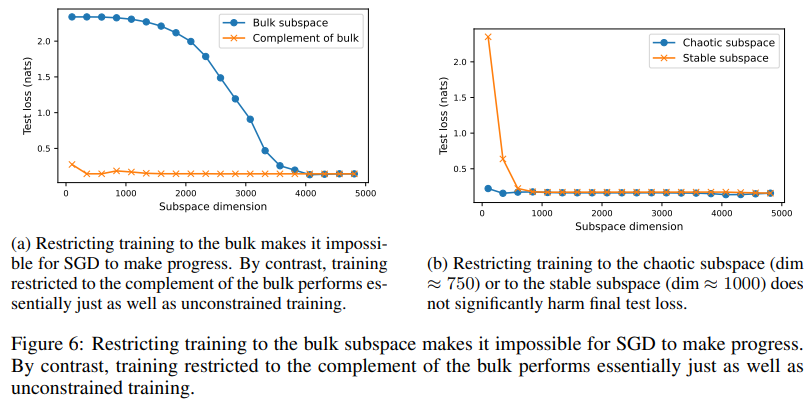
In experiments, the chaotic subspace shapes optimization dynamics and amplifies parameter perturbations. The stable subspace ensures smoother convergence by dampening changes. Interestingly, despite occupying 62% of the parameter space, the bulk subspace has minimal influence on in-distribution behavior but significantly impacts predictions for far out-of-distribution data. For example, perturbations along bulk directions leave test set predictions virtually unchanged, while those in chaotic or stable subspaces can alter outputs. Restricting training to the bulk subspace rendered gradient descent ineffective, whereas training in chaotic or stable subspaces achieved performance comparable to unconstrained training. These patterns were consistent across different initializations, loss functions, and datasets, demonstrating the robustness of the proposed framework. Experiments on a multi-layer perceptron (MLP) with one hidden layer of width 64, trained on the UCI digits dataset, confirmed these observations.
Several takeaways emerge from this study:
- The chaotic subspace, comprising approximately 500 singular values, amplifies parameter perturbations and is critical for shaping optimization dynamics.
- With around 750 singular values, the stable subspace effectively dampens perturbations, contributing to smooth and stable training convergence.
- The bulk subspace, accounting for 62% of the parameter space (approximately 3,000 singular values), remains largely unchanged during training. It has minimal impact on in-distribution behavior but significant effects on far-out-of-distribution predictions.
- Perturbations along chaotic or stable subspaces alter network outputs, whereas bulk perturbations leave test predictions virtually unaffected.
- Restricting training to the bulk subspace makes optimization ineffective, whereas training constrained to chaotic or stable subspaces performs comparably to full training.
- Experiments consistently demonstrated these patterns across different datasets and initializations, highlighting the generality of the findings.
In conclusion, this study introduces a framework for understanding neural network training dynamics by decomposing parameter updates into chaotic, stable, and bulk subspaces. It highlights the intricate interplay between initialization, data structure, and parameter evolution, providing valuable insights into how training unfolds. The results reveal that the chaotic subspace drives optimization, the stable subspace ensures convergence, and the bulk subspace, though large, has minimal impact on in-distribution behavior. This nuanced understanding challenges conventional assumptions about uniform parameter updates. It provides practical avenues for optimizing neural networks.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
 Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….
Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….The post Eleuther AI Introduces a Novel Machine Learning Framework for Analyzing Neural Network Training through the Jacobian Matrix appeared first on MarkTechPost.
“}]] [[{“value”:”Neural networks have become foundational tools in computer vision, NLP, and many other fields, offering capabilities to model and predict complex patterns. The training process is at the center of neural network functionality, where network parameters are adjusted iteratively to minimize error through optimization techniques like gradient descent. This optimization occurs in high-dimensional parameter space,
The post Eleuther AI Introduces a Novel Machine Learning Framework for Analyzing Neural Network Training through the Jacobian Matrix appeared first on MarkTechPost.”}]] Read More AI Paper Summary, AI Shorts, Applications, Artificial Intelligence, Editors Pick, Machine Learning, Staff, Tech News, Technology