[[{“value”:”

Text-to-image generative models have transformed how AI interprets textual inputs to produce compelling visual outputs. These models are used across industries for applications like content creation, design automation, and accessibility tools. Despite their capabilities, ensuring these models perform reliably remains a challenge. Assessing quality, diversity, and alignment with textual prompts is vital to understanding their limitations and advancing their development. However, traditional evaluation methods need frameworks that provide comprehensive, scalable, and actionable insights.
The key challenge in evaluating these models lies in the fragmentation of existing benchmarking tools and methods. Current evaluation metrics such as Fréchet Inception Distance (FID), which measures quality and diversity, or CLIPScore, which evaluates image-text alignment, are widely used but often exist in isolation. This lack of integration results in inefficient and incomplete assessments of model performance. Also, these metrics fail to address disparities in how models perform across diverse data subsets, such as geographic regions or prompt styles. Another limitation is the rigidity of existing frameworks, which struggle to accommodate new datasets or adapt to emerging metrics, ultimately constraining the ability to perform nuanced and forward-looking evaluations.
Researchers from FAIR at Meta, Mila Quebec AI Institute, Univ. Grenoble Alpes Inria CNRS Grenoble INP, LJK France, McGill University, and Canada CIFAR AI chair have introduced EvalGIM, a state-of-the-art library designed to unify and streamline the evaluation of text-to-image generative models to address these gaps. EvalGIM supports various metrics, datasets, and visualizations, enabling researchers to conduct robust and flexible assessments. The library introduces a unique feature called “Evaluation Exercises,” which synthesizes performance insights to answer specific research questions, such as the trade-offs between quality and diversity or the representation gaps across demographic groups. Designed with modularity, EvalGIM allows users to seamlessly integrate new evaluation components, ensuring its relevance as the field evolves.
EvalGIM’s design supports real-image datasets like MS-COCO and GeoDE, offering insights into performance across geographic regions. Prompt-only datasets, such as PartiPrompts and T2I-Compbench, are also included to test models across diverse text input scenarios. The library is compatible with popular tools like HuggingFace diffusers, enabling researchers to benchmark models from early training to advanced iterations. EvalGIM introduces distributed evaluations, allowing faster analysis across compute resources, and facilitates hyperparameter sweeps to explore model behavior under various conditions. Its modular structure enables the addition of custom datasets and metrics.

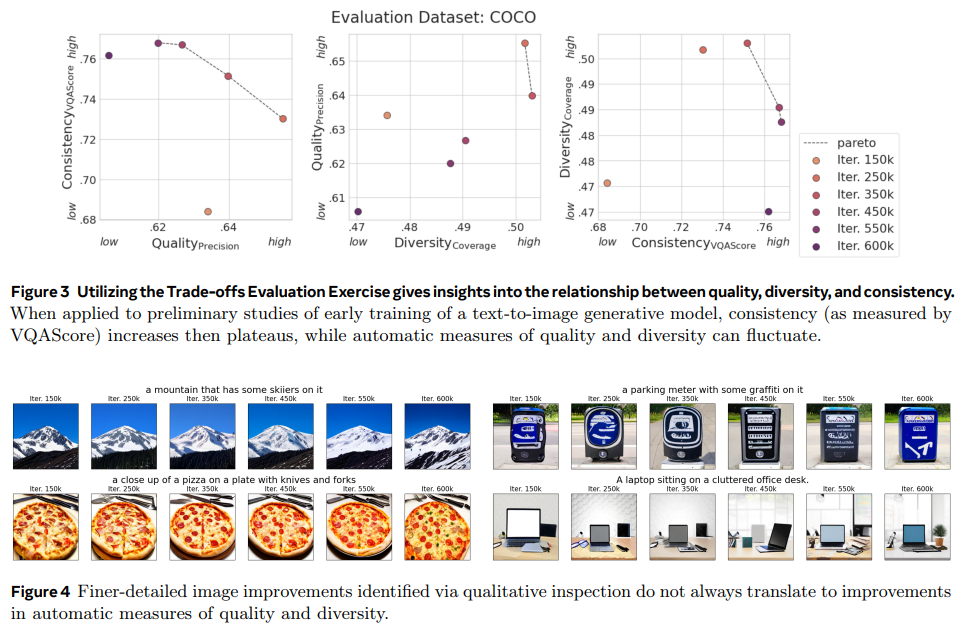
A core feature of EvalGIM is its Evaluation Exercises, which structure the evaluation process to address critical questions about model performance. For example, the Trade-offs Exercise explores how models balance quality, diversity, and consistency over time. Preliminary studies revealed that while consistency metrics such as VQAScore showed steady improvements during early training stages, they plateaued after approximately 450,000 iterations. Meanwhile, diversity (as measured by coverage) exhibited minor fluctuations, underscoring the inherent trade-offs between these dimensions. Another exercise, Group Representation, examined geographic performance disparities using the GeoDE dataset. Southeast Asia and Europe benefited most from advancements in latent diffusion models, while Africa showed lagging improvements, particularly in diversity metrics.
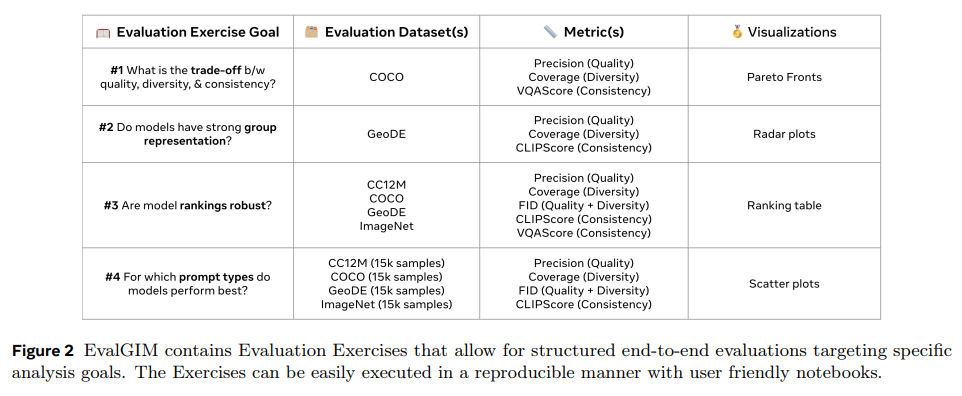
In a study comparing latent diffusion models, the Rankings Robustness Exercise demonstrated how performance rankings varied depending on the metric and dataset. For instance, LDM-3 ranked lowest on FID but highest in precision, highlighting its superior quality despite overall diversity shortcomings. Similarly, the Prompt Types Exercise revealed that combining original and recaptioned training data enhanced performance across datasets, with notable gains in precision and coverage for ImageNet and CC12M prompts. This nuanced approach underscores the importance of comprehensively using diverse metrics and datasets to evaluate generative models.
Several key takeaways from the Research on EvalGIM:
- Early training improvements in consistency plateaued at approximately 450,000 iterations, while quality (measured by precision) showed minor declines during advanced stages. This highlights the non-linear relationship between consistency and other performance dimensions.
- Advancements in latent diffusion models led to more improvements in Southeast Asia and Europe than in Africa, with coverage metrics for African data showing notable lags.
- FID rankings can obscure underlying strengths and weaknesses. For instance, LDM-3 performed best in precision but ranked lowest in FID, demonstrating that quality and diversity trade-offs should be analyzed separately.
- Combining original and recaptioned training data improved performance across datasets. Models trained exclusively with recaptioned data risk undesirable artifacts when exposed to original-style prompts.
- EvalGIM’s modular design facilitates the addition of new metrics and datasets, making it adaptable to evolving research needs and ensuring its long-term utility.
In conclusion, EvalGIM sets a new standard for evaluating text-to-image generative models by addressing the limitations of fragmented and outdated benchmarking tools. It enables comprehensive and actionable assessments by unifying metrics, datasets, and visualizations. Its Evaluation Exercises reveal critical insights, such as performance trade-offs, geographic disparities, and the influence of prompt styles. With the flexibility to integrate new datasets and metrics, EvalGIM remains adaptable to evolving research needs. This library bridges gaps in evaluation, fostering more inclusive and robust AI systems.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
 Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….
Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….The post Meta AI Releases EvalGIM: A Machine Learning Library for Evaluating Generative Image Models appeared first on MarkTechPost.
“}]] [[{“value”:”Text-to-image generative models have transformed how AI interprets textual inputs to produce compelling visual outputs. These models are used across industries for applications like content creation, design automation, and accessibility tools. Despite their capabilities, ensuring these models perform reliably remains a challenge. Assessing quality, diversity, and alignment with textual prompts is vital to understanding their
The post Meta AI Releases EvalGIM: A Machine Learning Library for Evaluating Generative Image Models appeared first on MarkTechPost.”}]] Read More AI Paper Summary, AI Shorts, Applications, Artificial Intelligence, Deep Learning, Editors Pick, Language Model, Large Language Model, Machine Learning, New Releases, Python, Staff, Tech News, Technology