[[{“value”:”
Table of Contents
- Vision-Language Model: PaliGemma for Image Description Generator and More
- Configuring Your Development Environment
- Setup and Imports
- Loading the PaliGemma Model and Processor
- Visual Question Answering
- Document Understanding
- Image Caption and Description Generator
- Video Caption and Description Generator
- Summary
Vision-Language Model: PaliGemma for Image Description Generator and More
In this tutorial, we will demonstrate a few use cases of PaliGemma, a vision-language model, using Gradio apps.

We will use our fine-tuned model for the visual question answering task, which was fine-tuned in our blog on Fine Tune PaliGemma with QLoRA for Visual Question Answering. For the other use cases, we will utilize the mixed PaliGemma checkpoint.
The mixed PaliGemma model from Google was trained on various tasks, making it versatile for a range of use cases.
The four use cases we will demonstrate are:
- Visual Question Answering
- Document Understanding
- Image Caption and Description Generator
- Video Caption and Description Generator
This lesson is the 2nd of a 4-part series on Vision-Language Models:
- Fine Tune PaliGemma with QLoRA for Visual Question Answering
- Vision-Language Model: PaliGemma for Image Description Generator and More (this tutorial)
- Deploy Gradio Applications on Hugging Face Spaces
- Object Detection with PaliGemma
To learn how to create cool PaliGemma apps using Gradio, just keep reading.
Configuring Your Development Environment
To follow this guide, you need to have the following libraries installed on your system.
transformerspeftbitsandbytesgradio
!pip install -q -U transformers peft bitsandbytes gradio
We will install transformers to use pre-trained models. The peft and bitsandbytes libraries are required as the fine-tuned model depends on these libraries. Additionally, we will use gradio to create an interactive interface for our applications.
from huggingface_hub import notebook_login
notebook_login()
To access Hugging Face models, we import notebook_login from the huggingface_hub library and run notebook_login(), which prompts us to enter a Hugging Face API token for authentication. You can create one here if you do not have a Hugging Face API token.
Need Help Configuring Your Development Environment?

All that said, are you:
- Short on time?
- Learning on your employer’s administratively locked system?
- Wanting to skip the hassle of fighting with the command line, package managers, and virtual environments?
- Ready to run the code immediately on your Windows, macOS, or Linux system?
Then join PyImageSearch University today!
Gain access to Jupyter Notebooks for this tutorial and other PyImageSearch guides pre-configured to run on Google Colab’s ecosystem right in your web browser! No installation required.
And best of all, these Jupyter Notebooks will run on Windows, macOS, and Linux!
Setup and Imports
Now, we import the required libraries.
import torch import cv2 from PIL import Image from transformers import AutoProcessor, PaliGemmaForConditionalGeneration import gradio as gr
We import torch to compute tensors, cv2 for image processing, and PIL for handling image files. transformers provide the necessary tools to work with the PaliGemma model and its processor, while gradio creates an interactive user interface for our applications.
Loading the PaliGemma Model and Processor
We will now load the PaliGemma model and processor.
But What Is PaliGemma?
PaliGemma is an open-source Vision-Language model developed to understand and interpret images alongside text. It has been trained on diverse datasets that contain both visual and textual elements, making it versatile for tasks such as visual question answering, document understanding, image captioning, etc.
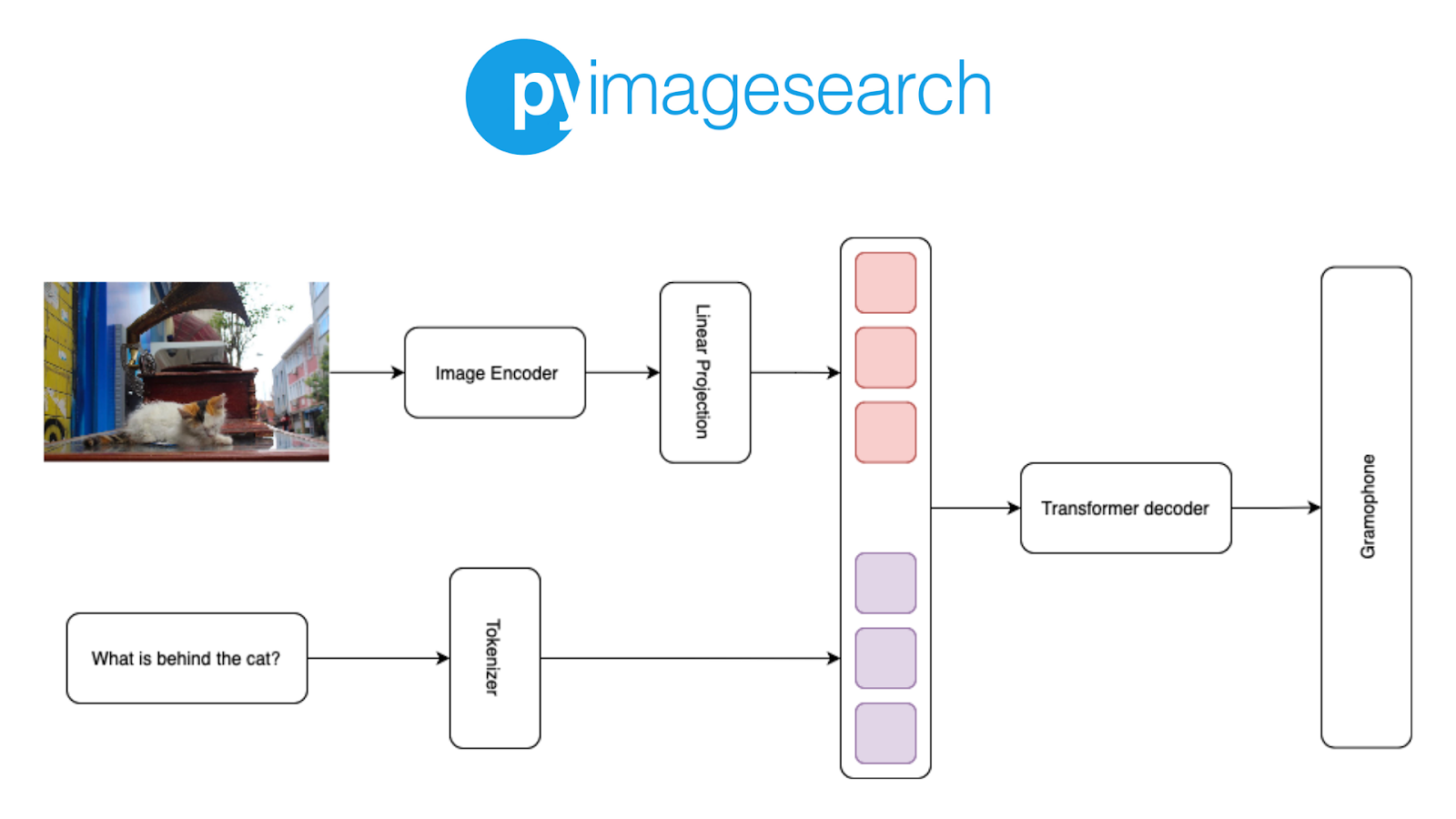
In Figure 1, we can see the architecture of PaliGemma. For more information, head over to Fine Tune PaliGemma with QLoRA for Visual Question Answering.
pretrained_model_id = "google/paligemma-3b-pt-224" pis_finetuned_model_id = "pyimagesearch/finetuned_paligemma_vqav2_small" mix_model_id = "google/paligemma-3b-mix-224"
We define the model IDs for the PaliGemma pre-trained model (3B, 224×224 px), our fine-tuned model, and the mixed model.
pis_finetuned_model = PaliGemmaForConditionalGeneration.from_pretrained(pis_finetuned_model_id) mix_model = PaliGemmaForConditionalGeneration.from_pretrained(mix_model_id) pretrained_processor = AutoProcessor.from_pretrained(pretrained_model_id) mix_processor = AutoProcessor.from_pretrained(mix_model_id)
Next, we load the models and processors using the defined model IDs.
The PaliGemmaForConditionalGeneration class instantiates the fine-tuned and mixed models, while AutoProcessor prepares the corresponding processors for each model.
Visual Question Answering
In the blog Fine Tune PaliGemma with QLoRA for Visual Question Answering, we discussed how the base pre-trained PaliGemma model was fine-tuned for the visual question answering (VQA) task.
Here, we will demonstrate how to use this fine-tuned model for VQA by integrating it into a Gradio app.
But What Is Visual Question Answering?
Visual Question Answering is a task in which a model is provided with an image and a related question. The model generates a relevant answer based on the image’s content. To provide an accurate response, the model must effectively understand both the visual elements of the image and the natural language of the question.
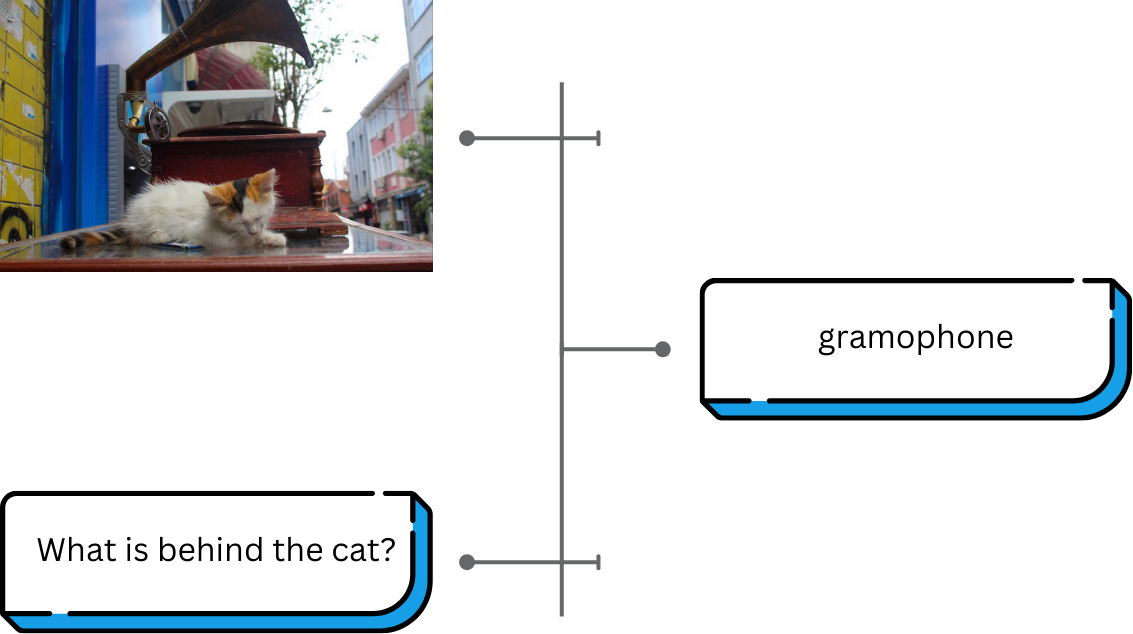
In Figure 2, we illustrate this with an example: given an image and a prompt, the model generates an accurate answer.
def process_image(image, prompt):
inputs = pretrained_processor(image.convert("RGB"), prompt, return_tensors="pt")
try:
output = pis_finetuned_model.generate(**inputs, max_new_tokens=20)
decoded_output = pretrained_processor.decode(output[0], skip_special_tokens=True)
return decoded_output[len(prompt):]
except IndexError as e:
print(f"IndexError: {e}")
return "An error occurred during processing."
The code is straightforward. We need to run inference with the fine-tuned PaliGemma model.
To keep things organized, we’ve wrapped this inference functionality in a function called process_image.
The process_image function accepts two parameters: an image and a prompt (the question provided by the user). Inside the function:
- We first process the image and prompt with the model’s processor, converting the image to RGB format and creating a tensor with both inputs.
- The model then generates a response based on the inputs, limited to 20 tokens, to keep responses concise.
- Finally, we decode the generated output and return it as the answer, omitting the prompt portion so the output only contains the answer text. We also skip any special tokens (e.g., padding) to keep the final output clean.
- To ensure smooth processing, we also handle any potential
IndexErrorthat may occur due to tensor-related issues.
inputs = [ gr.Image(type="pil"), gr.Textbox(label="Prompt", placeholder="Enter your question") ] outputs = gr.Textbox(label="Answer") demo = gr.Interface(fn=process_image, inputs=inputs, outputs=outputs, title="Visual Question Answering with Fine-tuned PaliGemma Model", description="Upload an image and ask questions to get answers.") demo.launch(debug=True)
Let’s set up a user interface to make the inference interactive with Gradio.
First, we define the inputs and outputs for the Gradio app.
- We use
gr.Image(type="pil")to allow users to upload an image in PIL format. - A
gr.Textboxlabeled"Prompt"is created for users to enter their questions, with a placeholder text to guide them. - We define another
gr.Textboxlabeled"Answer"where the model’s response will be displayed.
Next, we create an interface using gr.Interface, where we specify:
fn=process_image: This is the inference function defined above that will process the inputs and generate outputs.inputs=inputsandoutputs=outputs: These parameters link our previously defined inputs and outputs to the interface.- A
titleanddescriptionto provide context for the user.
Finally, we call demo.launch(debug=True) to run the Gradio app. The debug=True option enables debugging information, which can be helpful for troubleshooting.
Once everything is set up, we will be able to upload images and ask questions, receiving answers from our fine-tuned PaliGemma model.
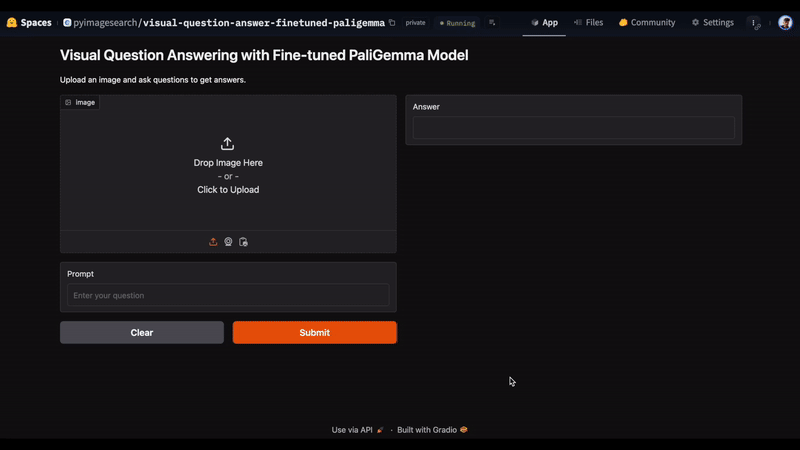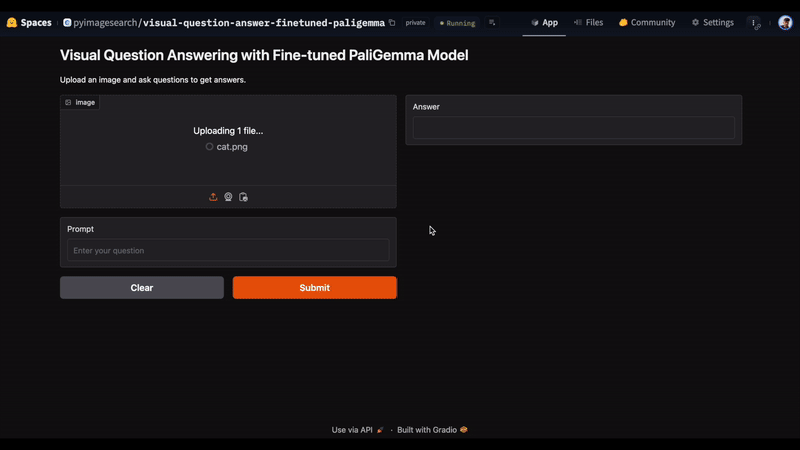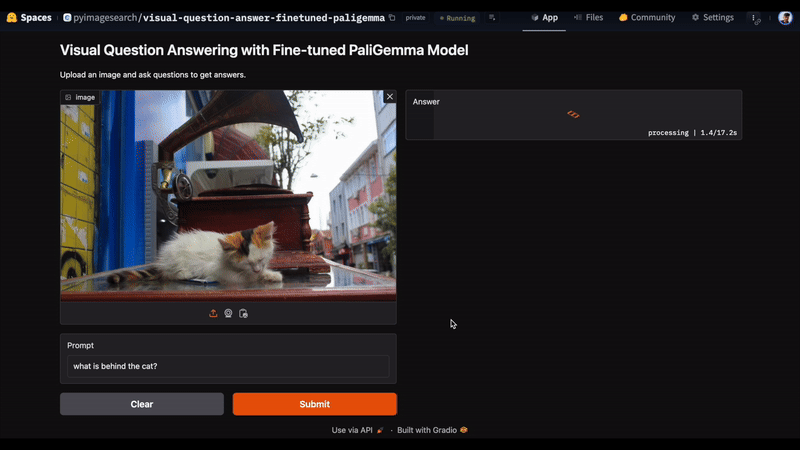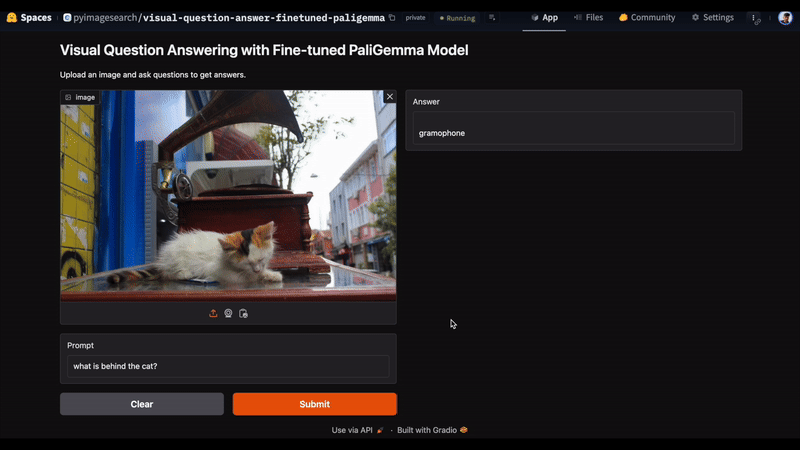
In Figure 3, we uploaded an image and entered the prompt, “What is behind the cat?” The model accurately responds with “gramophone” as the answer.
Document Understanding
Since our fine-tuned model was specifically trained for the visual question answering task, it will not perform well on other tasks.
For the remaining use cases, we will use the mixed PaliGemma model, which has been trained on a variety of tasks.
But What Is Document Understanding?
Document Understanding involves analyzing images that contain both visual elements and textual information. The model interprets this content to extract relevant details and answer questions based on the extracted content.
def process_image(image, prompt):
inputs = mix_processor(image.convert("RGB"), prompt, return_tensors="pt")
try:
output = mix_model.generate(**inputs, max_new_tokens=20)
decoded_output = mix_processor.decode(output[0], skip_special_tokens=True)
return decoded_output[len(prompt):]
except IndexError as e:
print(f"IndexError: {e}")
return "An error occurred during processing."
This inference function is similar to the one we wrote earlier. The only difference is that we use the mix model released by Google instead of the fine-tuned model.
inputs = [ gr.Image(type="pil"), gr.Textbox(label="Prompt", placeholder="Enter your question") ] outputs = gr.Textbox(label="Answer") demo = gr.Interface(fn=process_image, inputs=inputs, outputs=outputs, title="Document Understanding with Mix PaliGemma Model", description="Upload a document and get answers based on your prompt") demo.launch(debug=True)
The Gradio interface code is again similar to the one we wrote earlier. The only difference is the title and description to provide context for the user.
In Figure 4, we uploaded an image and entered the prompt, “What does this image show?” The model accurately responds with “training and validation accuracy for the proposed model” as the answer.
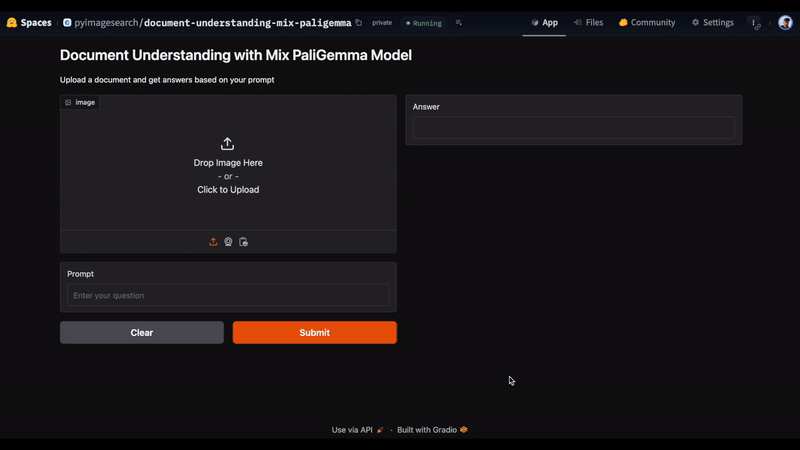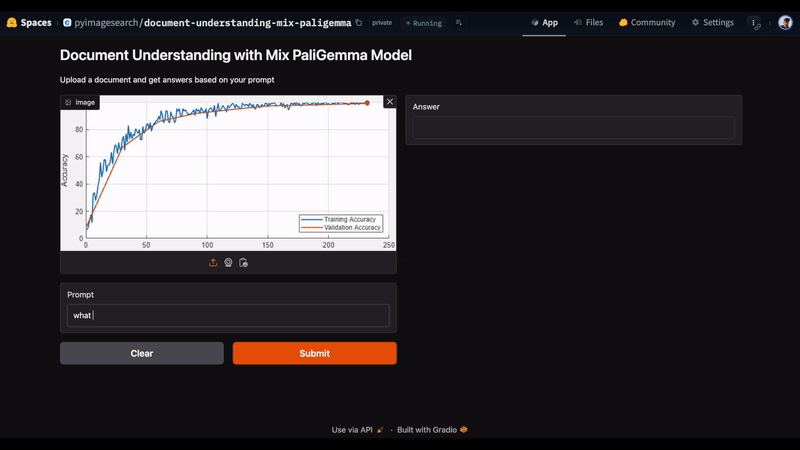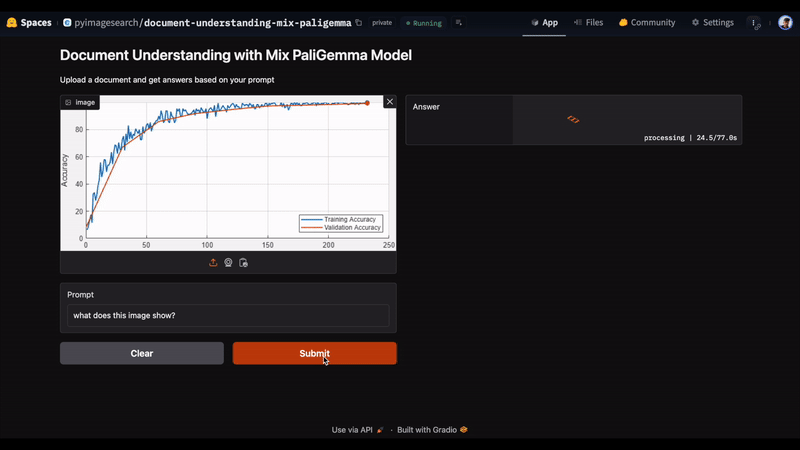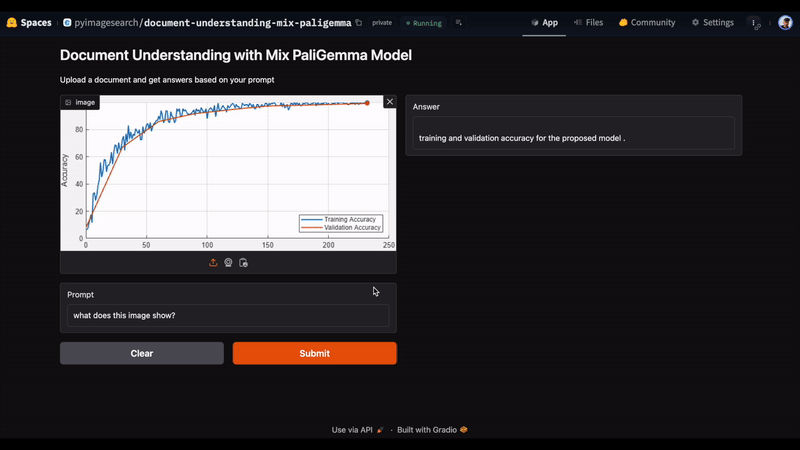
Image Caption and Description Generator
Here, we will again use Google’s mix PaliGemma model for the Image Caption and Description Generation task.
But What Is Image Captioning?
Image Captioning is the process of generating a textual description for a given image. It involves analyzing the visual content and creating descriptive sentences that capture the image’s key elements and context.
def process_image(image, prompt):
inputs = mix_processor(image.convert("RGB"), prompt, return_tensors="pt")
try:
output = mix_model.generate(**inputs, max_new_tokens=20)
decoded_output = mix_processor.decode(output[0], skip_special_tokens=True)
return decoded_output[len(prompt):]
except IndexError as e:
print(f"IndexError: {e}")
return "An error occurred during processing."
The inference function remains the same as the Document Understanding task.
inputs = [ gr.Image(type="pil"), gr.Textbox(label="Prompt", placeholder="Enter your question") ] outputs = gr.Textbox(label="Answer") demo = gr.Interface(fn=process_image, inputs=inputs, outputs=outputs, title="Image Captioning with Mix PaliGemma Model", description="Upload an image and get captions based on your prompt.") demo.launch(debug=True)
The Gradio interface code remains the same as well. The only difference is the title and description to provide context for the user.
In Figure 5, we uploaded an image and entered the prompt, “caption en”. This is a pre-defined prefix set for the mix PaliGemma model to indicate that the model should generate an English caption for an image. The model accurately responds with “A cat wearing a suit and tie standing on a sidewalk.” as the answer.
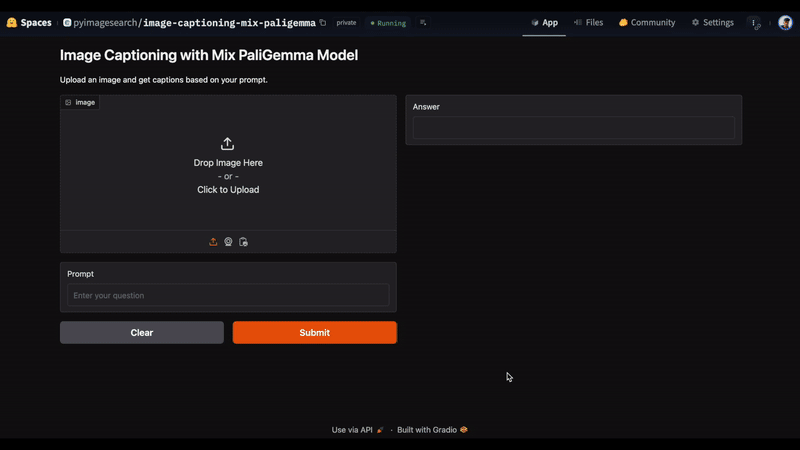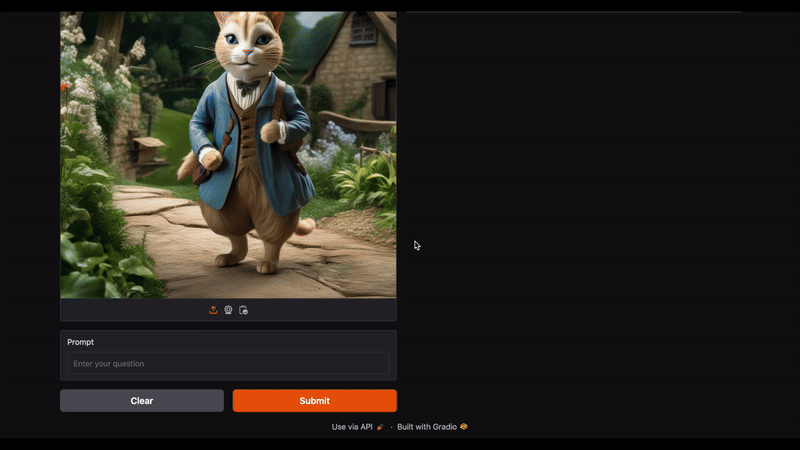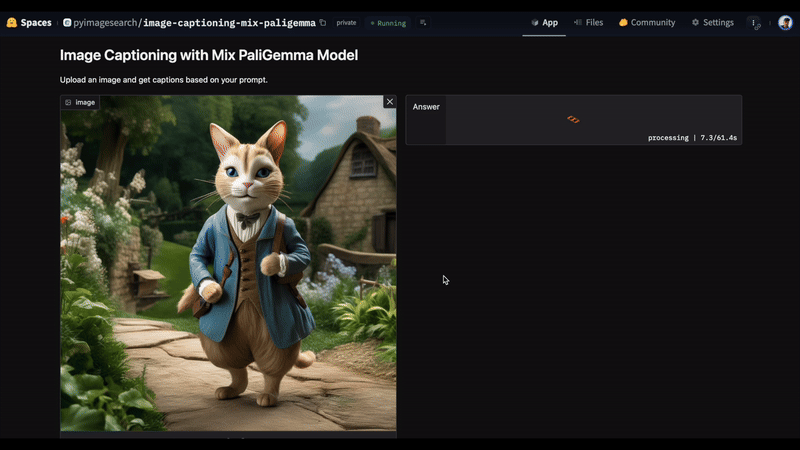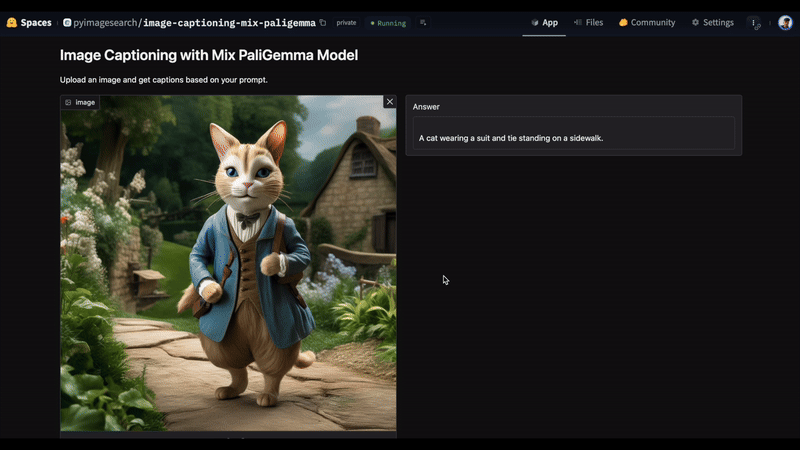
Video Caption and Description Generator
Here, we will again use Google’s mix PaliGemma model for the Video Caption and Description Generation task.
But What Is Video Captioning?
Video Captioning extends the principles of Image Captioning by generating descriptive text for an entire video rather than a single image. Since a video is made up of multiple frames, Video Captioning involves understanding and processing the sequence of frames to capture the changing context, actions, and interactions over time. This task requires both visual and temporal analysis to create coherent descriptions that summarize the content and progression of the video accurately.
def extract_frames(video_path, frame_interval=1):
vidcap = cv2.VideoCapture(video_path)
frames = []
success, image = vidcap.read()
count = 0
while success:
if count % frame_interval == 0:
frames.append(image)
success, image = vidcap.read()
count += 1
vidcap.release()
return frames
Since we are working with video, we need a sequence of frames.
The extract_frames function is designed to capture frames from a video file (video_path) at a specified interval (frame_interval).
We begin by using cv2.VideoCapture(video_path), where cv2 is OpenCV’s computer vision library. This method opens the video file at the specified path (video_path), allowing access to each frame.
Once the video file is opened, we initialize an empty list called frames, which will store the extracted frames. We also read the first frame using success, image = vidcap.read(), where success indicates whether the frame was read successfully, and image contains the frame itself. We initialize a counter variable, count, to keep track of the number of frames processed.
Next, we enter a while loop that continues as long as success is True, meaning there are frames left to read from the video. Inside the loop, we check if the current frame number (tracked by count) is a multiple of the frame_interval. If it is, we append the current frame (image) to the frames list.
The line success, image = vidcap.read() reads the next frame, updating the success and image variables. After reading each frame, we increment the count by 1 to track how many frames have been processed.
Once all the frames have been read and the loop has finished executing, we call vidcap.release() to free up system resources associated with the video file. Finally, the function returns the list of captured frames.
def process_video(video, prompt):
frames = extract_frames(video, frame_interval=10)
captions = []
for frame in frames:
image = Image.fromarray(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))
inputs = mix_processor(image.convert("RGB"), prompt, return_tensors="pt")
try:
output = mix_model.generate(**inputs, max_new_tokens=20)
decoded_output = mix_processor.decode(output[0], skip_special_tokens=True)
captions.append(decoded_output[len(prompt):])
except IndexError as e:
print(f"IndexError: {e}")
captions.append("Error processing frame")
return " ".join(captions)
The process_video function extends the previous process_image function, which is designed to handle video input. This function captures frames from the video, processes each frame to generate captions based on the provided prompt, and returns a concatenated string of all generated captions.
We begin by calling extract_frames(video, frame_interval=10), which retrieves frames from the input video at specified intervals (in this case, every 10 frames). This helps reduce computational load while still capturing essential visual information from the video.
We create an empty list named captions to store the generated captions for each frame processed.
Next, the function iterates over each extracted frame:
- The current
frameis converted to RGB format using OpenCV’scv2.cvtColor, then transformed into a PIL image withImage.fromarray(). - The image and prompt are processed using the
mix_processor, similar to how it was done in theprocess_imagefunction. Thereturn_tensors="pt"argument creates the necessary tensor format for the model.
Within a try block, the model generates a response for each frame using mix_model.generate(), constrained to a maximum of 20 tokens to ensure concise output.
The generated output is then decoded with mix_processor.decode(), and any prompt portion is omitted from the final caption. The resulting caption is appended to the captions list.
Similar to the previous implementation, an except block catches any potential IndexError, which may occur during tensor processing. If an error arises, a placeholder caption ("Error processing frame") is added to the captions list for that specific frame.
Finally, the function returns a single string created by joining all captions in the captions list with a space. Based on the prompt, this concatenated output provides a comprehensive narrative of the video’s content.
inputs = [ gr.Image(label="Upload Video"), gr.Textbox(label="Prompt", placeholder="Enter your question") ] outputs = gr.Textbox(label="Answer") demo = gr.Interface(fn=process_image, inputs=inputs, outputs=outputs, title="Video Captioning with Mix PaliGemma Model", description="Upload a video and get captions based on your prompt.") demo.launch(debug=True)
The Gradio interface code remains largely the same, with a few updates:
- Previously, only PIL images were supported using
gr.Image(type="pil"). Now, it has been updated togr.Image(label="Upload Video"), which can handle various media types, including videos. - Additionally, the
titleanddescriptionhave been adjusted to provide a clearer context for users.
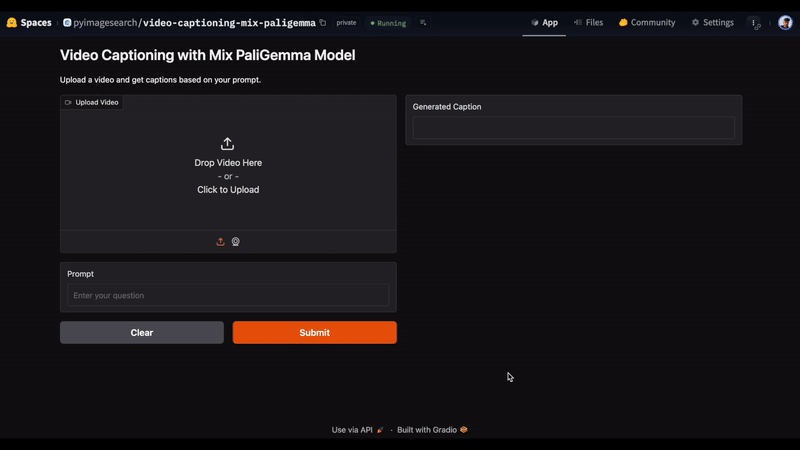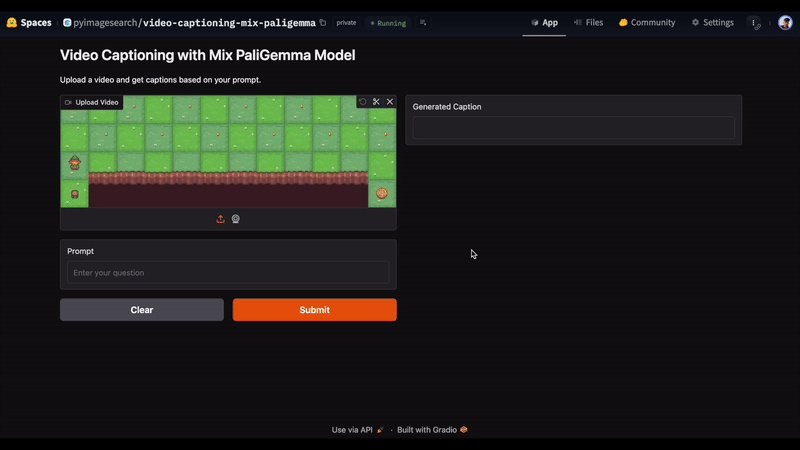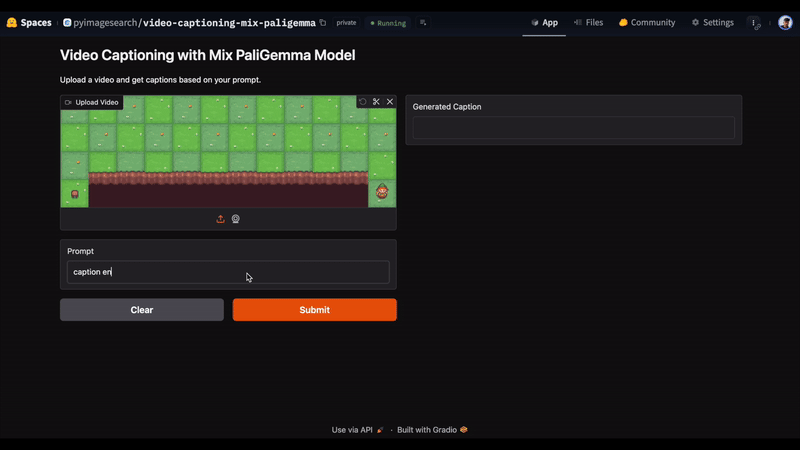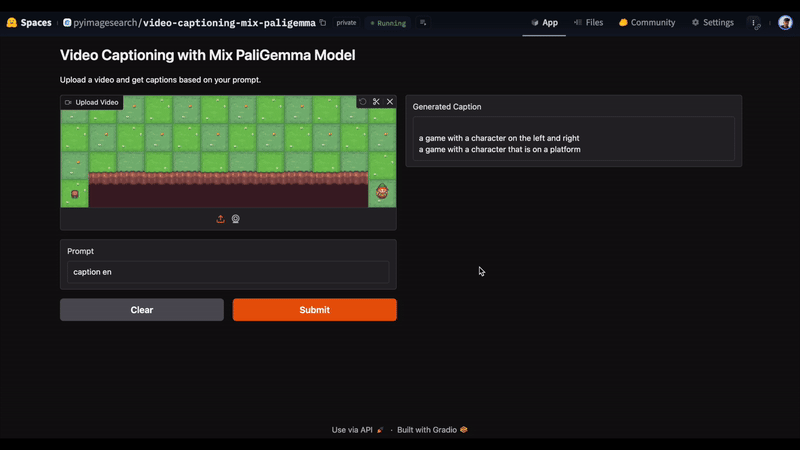
In Figure 6, we uploaded a video and entered the prompt, “caption en”. This is a pre-defined prefix set for mix PaliGemma model to indicate that the model should generate an English caption for an image. The model accurately responds with “a game with a character on the left and right. a game with a character that is on a platform.” as the answer.
What’s next? We recommend PyImageSearch University.
86 total classes • 115+ hours of on-demand code walkthrough videos • Last updated: October 2024
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you’re serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you’ll find:
- ✓ 86 courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this tutorial, we explored four exciting use cases of the PaliGemma model, brought to life through interactive Gradio apps:
- Visual Question Answering
- Document Understanding
- Image Captioning and Description Generation
- Video Captioning and Description Generation
You can try these tasks yourself by running the Colab notebook or directly interacting with the Gradio apps hosted on Hugging Face Spaces:
- Visual Question Answering on Hugging Face Spaces
- Document Understanding on Hugging Face Spaces
- Image Captioning and Description Generator on Hugging Face Spaces
- Video Captioning and Description Generator on Hugging Face Spaces
Stay tuned for an upcoming blog, where we’ll guide you through the steps to deploy your own applications on Hugging Face Spaces!
Citation Information
Thakur, P. “Vision-Language Model: PaliGemma for Image Description Generator and More,” PyImageSearch, P. Chugh, S. Huot, G. Kudriavtsev, and R. Raha, eds., 2024, https://pyimg.co/l7cx1
@incollection{Thakur_2024_vision-language-model-paligemma-image-description-generator,
author = {Piyush Thakur},
title = {{Vision-Language Model: PaliGemma for Image Description Generator and More}},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Susan Huot and Georgii Kudriavtsev and Ritwik Raha},
year = {2024},
url = {https://pyimg.co/l7cx1},
}
To download the source code to this post (and be notified when future tutorials are published here on PyImageSearch), simply enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you’ll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!
The post Vision-Language Model: PaliGemma for Image Description Generator and More appeared first on PyImageSearch.
“}]] [[{“value”:”Table of Contents Vision-Language Model: PaliGemma for Image Description Generator and More Configuring Your Development Environment Setup and Imports Loading the PaliGemma Model and Processor Visual Question Answering Document Understanding Image Caption and Description Generator Video Caption and Description Generator…
The post Vision-Language Model: PaliGemma for Image Description Generator and More appeared first on PyImageSearch.”}]]  Read More Computer Vision, Document Understanding, Gradio, Image and Video Captioning, Tutorial, Visual QA, VLM, clip, cross-attention, document understanding, fine-tuned models, gemma, gradio, huggingface, huggingface spaces, image description generator, inference, machine-learning, multimodal, paligemma, siglip, transformers, tutorial, video description generator, vision models, vision-language model, visual question answering, vlm
Read More Computer Vision, Document Understanding, Gradio, Image and Video Captioning, Tutorial, Visual QA, VLM, clip, cross-attention, document understanding, fine-tuned models, gemma, gradio, huggingface, huggingface spaces, image description generator, inference, machine-learning, multimodal, paligemma, siglip, transformers, tutorial, video description generator, vision models, vision-language model, visual question answering, vlm