[[{“value”:”

Large Language Models (LLMs) are the backbone of numerous applications, such as conversational agents, automated content creation, and natural language understanding tasks. Their effectiveness lies in their ability to model and predict complex language patterns from vast datasets. However, developing LLMs presents a major challenge due to the immense computational cost of training. This involves optimizing models with billions of parameters over massive corpora, requiring extensive hardware and time. Consequently, there is a need for innovative training methodologies that can mitigate these challenges while maintaining or enhancing the quality of LLMs.
In developing LLMs, traditional training approaches are inefficient, as they treat all data equally, regardless of complexity. These methods do not prioritize specific subsets of data that could expedite learning, nor do they leverage existing models to assist in training. This often results in unnecessary computational effort, as simpler instances are processed alongside complex ones without differentiation. Also, standard self-supervised learning, where models predict the next token in a sequence, fails to utilize the potential of smaller, less computationally expensive models that can inform and guide the training of larger models.
Knowledge distillation (KD) is commonly employed to transfer knowledge from larger, well-trained models to smaller, more efficient ones. However, this process has rarely been reversed, where smaller models assist in training larger ones. This gap represents a missed opportunity, as smaller models, despite their limited capacity, can provide valuable insights into specific regions of the data distribution. They can efficiently identify “easy” and “hard” instances, which can significantly influence the training dynamics of LLMs.
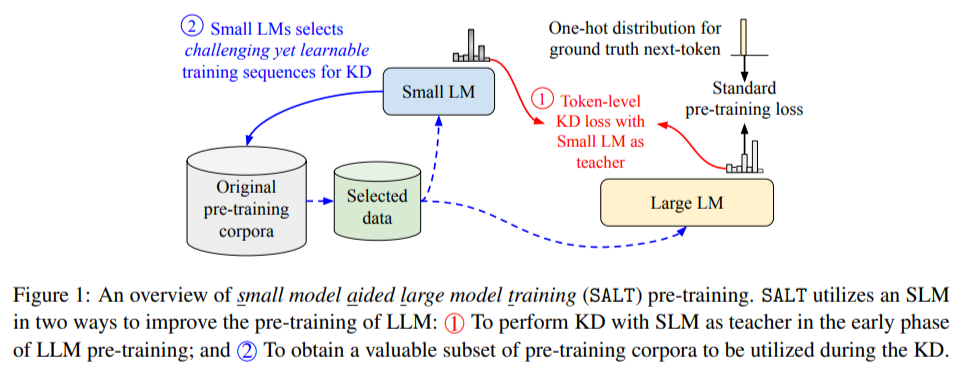
Google Research and Google DeepMind researchers introduced a novel approach called Small model Aided Large model Training (SALT) to address the above challenges. This method innovatively employs smaller language models (SLMs) to improve the efficiency of LLM training. SALT leverages SLMs in two ways: providing soft labels as an additional source of supervision during the initial training phase and selecting subsets of data that are particularly valuable for learning. The approach ensures that LLMs are guided by SLMs in prioritizing informative and challenging data sequences, thereby reducing computational requirements while improving the overall quality of the trained model.
SALT operates through a two-phase methodology:
- In the first phase, SLMs act as teachers, transferring their predictive distributions to the LLMs via knowledge distillation. This process focuses on aligning the LLM’s predictions with those of the SLM in areas where the latter excels. Also, SLMs identify subsets of data that are both challenging and learnable, enabling the LLM to concentrate on these critical examples early in training.
- The second phase transitions to traditional self-supervised learning, allowing the LLM to independently refine its understanding of more complex data distributions.
This two-stage process balances leveraging the strengths of SLMs and maximizing the inherent capabilities of LLMs.
In experimental results, a 2.8-billion-parameter LLM trained with SALT on the Pile dataset outperformed a baseline model trained using conventional methods. Notably, the SALT-trained model achieved better results on benchmarks such as reading comprehension, commonsense reasoning, and natural language inference while utilizing only 70% of the training steps. This translated to a reduction of approximately 28% in wall-clock training time. Also, the LLM pre-trained using SALT demonstrated a 58.99% accuracy in next-token prediction compared to 57.7% for the baseline and exhibited a lower log-perplexity of 1.868 versus 1.951 for the baseline, indicating enhanced model quality.

Key takeaways from the research include the following:
- SALT reduced the computational requirements for training LLMs by almost 28%, primarily by utilizing smaller models to guide initial training phases.
- The method consistently produced better-performing LLMs across various tasks, including summarization, arithmetic reasoning, and natural language inference.
- By enabling smaller models to select challenging yet learnable data, SALT ensured that LLMs focused on high-value data points, expediting learning without compromising quality.
- The method is particularly promising for institutions with limited computational resources. It leverages smaller, less costly models to assist in developing large-scale LLMs.
- After supervised fine-tuning, the SALT-trained models showcased better generalization capabilities in few-shot evaluations and downstream tasks.

In conclusion, SALT effectively redefines the paradigm of LLM training by transforming smaller models into valuable training aids. Its innovative two-stage process achieves a rare balance of efficiency and effectiveness, making it a pioneering approach in machine learning. SALT will be instrumental in overcoming resource constraints, enhancing model performance, and democratizing access to cutting-edge AI technologies. This research underscores the importance of rethinking traditional practices and leveraging existing tools to achieve more with less.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
 Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….
Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….The post Google DeepMind Introduces ‘SALT’: A Machine Learning Approach to Efficiently Train High-Performing Large Language Models using SLMs appeared first on MarkTechPost.
“}]] [[{“value”:”Large Language Models (LLMs) are the backbone of numerous applications, such as conversational agents, automated content creation, and natural language understanding tasks. Their effectiveness lies in their ability to model and predict complex language patterns from vast datasets. However, developing LLMs presents a major challenge due to the immense computational cost of training. This involves
The post Google DeepMind Introduces ‘SALT’: A Machine Learning Approach to Efficiently Train High-Performing Large Language Models using SLMs appeared first on MarkTechPost.”}]] Read More AI Paper Summary, AI Shorts, Applications, Artificial Intelligence, Editors Pick, Language Model, Large Language Model, Machine Learning, Small Language Model, Staff, Tech News, Technology