[[{“value”:”

Hypernetworks have gained attention for their ability to efficiently adapt large models or train generative models of neural representations. Despite their effectiveness, training hyper networks are often labor-intensive, requiring precomputed optimized weights for each data sample. This reliance on ground truth weights necessitates significant computational resources, as seen in methods like HyperDreamBooth, where preparing training data can take extensive GPU time. Additionally, current approaches assume a one-to-one mapping between input samples and their corresponding optimized weights, overlooking the stochastic nature of neural network optimization. This oversimplification can constrain the expressiveness of hypernetworks. To address these challenges, researchers aim to amortize per-sample optimizations into hypernetworks, bypassing the need for exhaustive precomputation and enabling faster, more scalable training without compromising performance.
Recent advancements integrate gradient-based supervision into hypernetwork training, eliminating the dependency on precomputed weights while maintaining stability and scalability. Unlike traditional methods that rely on pre-computed task-specific weights, this approach supervises hypernetworks through gradients along the convergence path, enabling efficient learning of weight space transitions. This idea draws inspiration from generative models like diffusion models, consistency models, and flow-matching frameworks, which navigate high-dimensional latent spaces through gradient-guided pathways. Additionally, derivative-based supervision, used in Physics-Informed Neural Networks (PINNs) and Energy-Based Models (EBMs), informs the network through gradient directions, avoiding explicit output supervision. By adopting gradient-driven supervision, the proposed method ensures robust and stable training across diverse datasets, streamlining hypernetwork training while eliminating the computational bottlenecks of prior techniques.
Researchers from the University of British Columbia and Qualcomm AI Research propose a novel method for training hypernetworks without relying on precomputed, per-sample optimized weights. Their approach introduces a “Hypernetwork Field” that models the entire optimization trajectory of task-specific networks rather than focusing on final converged weights. The hypernetwork estimates weights at any point along the training path by incorporating the convergence state as an additional input. This process is guided by matching the gradients of estimated weights with the original task gradients, eliminating the need for precomputed targets. Their method significantly reduces training costs and achieves competitive results in tasks like personalized image generation and 3D shape reconstruction.
The Hypernetwork Field framework introduces a method to model the entire training process of task-specific neural networks, such as DreamBooth, without needing precomputed weights. It uses a hypernetwork, which predicts the parameters of the task-specific network at any given optimization step based on an input condition. The training relies on matching the gradients of the task-specific network to the hypernetwork’s trajectory, removing the need for repetitive optimization for each sample. This method enables accurate prediction of network weights at any stage by capturing the full training dynamics. It is computationally efficient and achieves strong results in tasks like personalized image generation.
The experiments demonstrate the versatility of the Hypernetwork Field framework in two tasks: personalized image generation and 3D shape reconstruction. The method employs DreamBooth as the task network for image generation, personalizing images from CelebA-HQ and AFHQ datasets using conditioning tokens. It achieves faster training and inference than baselines, offering comparable or superior performance in metrics like CLIP-I and DINO. For 3D shape reconstruction, the framework predicts occupancy network weights using rendered images or 3D point clouds as inputs, effectively replicating the entire optimization trajectory. The approach reduces compute costs significantly while maintaining high-quality outputs across both tasks.
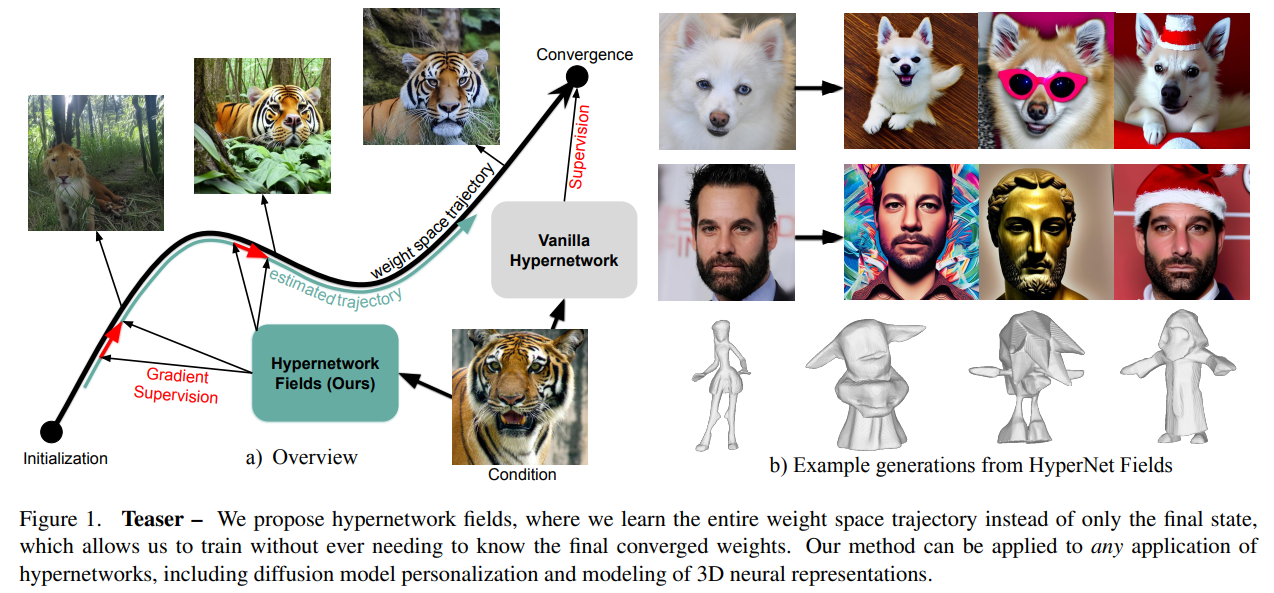
In conclusion, Hypernetwork Fields presents an approach to training hypernetworks efficiently. Unlike traditional methods that require precomputed ground truth weights for each sample, this framework learns to model the entire optimization trajectory of task-specific networks. By introducing the convergence state as an additional input, Hypernetwork Fieldsestimatese the training pathway instead of only the final weights. A key feature is using gradient supervision to align the estimated and task network gradients, eliminating the need for pre-sample weights while maintaining competitive performance. This method is generalizable, reduces computational overhead, and holds the potential for scaling hypernetworks to diverse tasks and larger datasets.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
 Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….
Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….The post Hypernetwork Fields: Efficient Gradient-Driven Training for Scalable Neural Network Optimization appeared first on MarkTechPost.
“}]] [[{“value”:”Hypernetworks have gained attention for their ability to efficiently adapt large models or train generative models of neural representations. Despite their effectiveness, training hyper networks are often labor-intensive, requiring precomputed optimized weights for each data sample. This reliance on ground truth weights necessitates significant computational resources, as seen in methods like HyperDreamBooth, where preparing training
The post Hypernetwork Fields: Efficient Gradient-Driven Training for Scalable Neural Network Optimization appeared first on MarkTechPost.”}]] Read More AI Paper Summary, AI Shorts, Applications, Artificial Intelligence, Editors Pick, Machine Learning, Staff, Tech News, Technology