[[{“value”:”

LLMs have revolutionized software development by automating coding tasks and bridging the natural language and programming gap. While highly effective for general-purpose programming, they struggle with specialized domains like High-Performance Computing (HPC), particularly in generating parallel code. This limitation arises from the scarcity of high-quality parallel code data in pre-training datasets and the inherent complexity of parallel programming. Addressing these challenges is critical, as creating HPC-specific LLMs can significantly enhance developer productivity and accelerate scientific discoveries. To overcome these hurdles, researchers emphasize the need for curated datasets with better-quality parallel code and improved training methodologies that go beyond simply increasing data volume.
Efforts to adapt LLMs for HPC have included fine-tuning specialized models such as HPC-Coder and OMPGPT. While these models demonstrate promise, many rely on outdated architectures or narrow applications, limiting their effectiveness. Recent advancements like HPC-Coder-V2 leverage state-of-the-art techniques to improve performance, achieving comparable or superior results to larger models while maintaining efficiency. Studies highlight the importance of data quality over quantity and advocate for targeted approaches to enhance parallel code generation. Future research aims to develop robust HPC-specific LLMs that bridge the gap between serial and parallel programming capabilities by integrating insights from synthetic data generation and focusing on high-quality datasets.
Researchers from the University of Maryland conducted a detailed study to fine-tune a specialized HPC LLM for parallel code generation. They developed a synthetic dataset, HPC-INSTRUCT, containing high-quality instruction-answer pairs derived from parallel code samples. Using this dataset, they fine-tuned HPC-Coder-V2, which emerged as the best open-source code LLM for parallel code generation, performing near GPT-4 levels. Their study explored how data representation, training parameters, and model size influence performance, addressing key questions about data quality, fine-tuning strategies, and scalability to guide future advancements in HPC-specific LLMs.
Enhancing Code LLMs for parallel programming involves creating HPC-INSTRUCT, a large synthetic dataset of 120k instruction-response pairs derived from open-source parallel code snippets and LLM outputs. This dataset includes programming, translation, optimization, and parallelization tasks across languages like C, Fortran, and CUDA. We fine-tune three pre-trained Code LLMs—1.3B, 6.7B, and 16B parameter models—on HPC-INSTRUCT and other datasets using the AxoNN framework. Through ablation studies, we examine the impact of data quality, model size, and prompt formatting on performance, optimizing the models for the ParEval benchmark to assess their ability to generate parallel code effectively.
To evaluate Code LLMs for parallel code generation, the ParEval benchmark was used, featuring 420 diverse problems across 12 categories and seven execution models like MPI, CUDA, and Kokkos. Performance was assessed using the pass@k metric, which measures the probability of generating at least one correct solution within k attempts. Ablation studies analyzed the impact of base models, instruction masking, data quality, and model size. Results revealed that fine-tuning base models yielded better performance than instruct variants, high-quality data improved outcomes, and larger models showed diminishing returns, with a notable gain from 1.3B to 6.7B parameters.
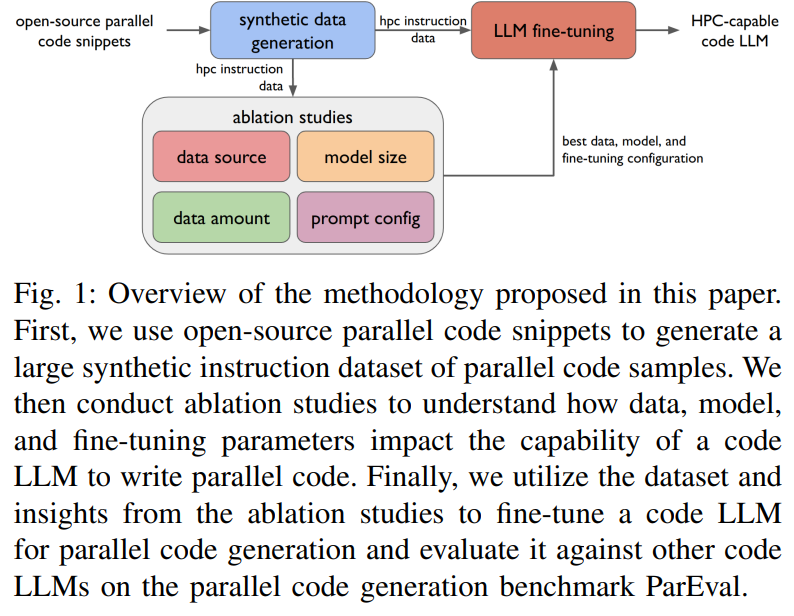
In conclusion, the study presents HPC-INSTRUCT, an HPC instruction dataset created using synthetic data from LLMs and open-source parallel code. An in-depth analysis was conducted across data, model, and prompt configurations to identify factors influencing code LLM performance in generating parallel code. Key findings include the minimal impact of instruction masking, the advantage of fine-tuning base models over instruction-tuned variants, and diminishing returns from increased training data or model size. Using these insights, three state-of-the-art HPC-specific LLMs—HPC-Coder-V2 models—were fine-tuned, achieving superior performance on the ParEval benchmark. These models are efficient, outperforming others in parallel code generation for high-performance computing.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
 Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….
Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….The post Advancing Parallel Programming with HPC-INSTRUCT: Optimizing Code LLMs for High-Performance Computing appeared first on MarkTechPost.
“}]] [[{“value”:”LLMs have revolutionized software development by automating coding tasks and bridging the natural language and programming gap. While highly effective for general-purpose programming, they struggle with specialized domains like High-Performance Computing (HPC), particularly in generating parallel code. This limitation arises from the scarcity of high-quality parallel code data in pre-training datasets and the inherent complexity
The post Advancing Parallel Programming with HPC-INSTRUCT: Optimizing Code LLMs for High-Performance Computing appeared first on MarkTechPost.”}]] Read More AI Paper Summary, AI Shorts, Applications, Artificial Intelligence, Editors Pick, Machine Learning, Staff, Tech News, Technology