
[[{“value”:”

Large Language Models (LLMs) and Vision Language Models (VLMs) have revolutionized the automation of mobile device control through natural language commands, offering solutions for complex user tasks. The conventional approach, “Step-wise GUI agents,” operates by querying the LLM at each GUI state for dynamic decision-making and reflection, continuously processing the user’s task, and observing the GUI state until completion. However, this method faces significant challenges as it relies heavily on powerful cloud-based models like GPT-4 and Claude. This raises critical concerns about privacy and security risks when sharing personal GUI pages, substantial user-side traffic consumption, and high server-side centralized serving costs, making large-scale deployment of GUI agents problematic.
Earlier attempts to automate mobile tasks relied heavily on template-based methods like Siri, Google Assistant, and Cortana, which used predefined templates to process user inputs. More advanced GUI-based automation emerged to handle complex tasks without depending on third-party APIs or extensive programming. While some researchers focused on enhancing Small Language Models (SLMs) through GUI-specific training and exploration-based knowledge acquisition, these approaches faced significant limitations. Script-based GUI agents particularly struggled with the dynamic nature of mobile apps, where UI states and elements frequently change, making knowledge extraction and script execution challenging.
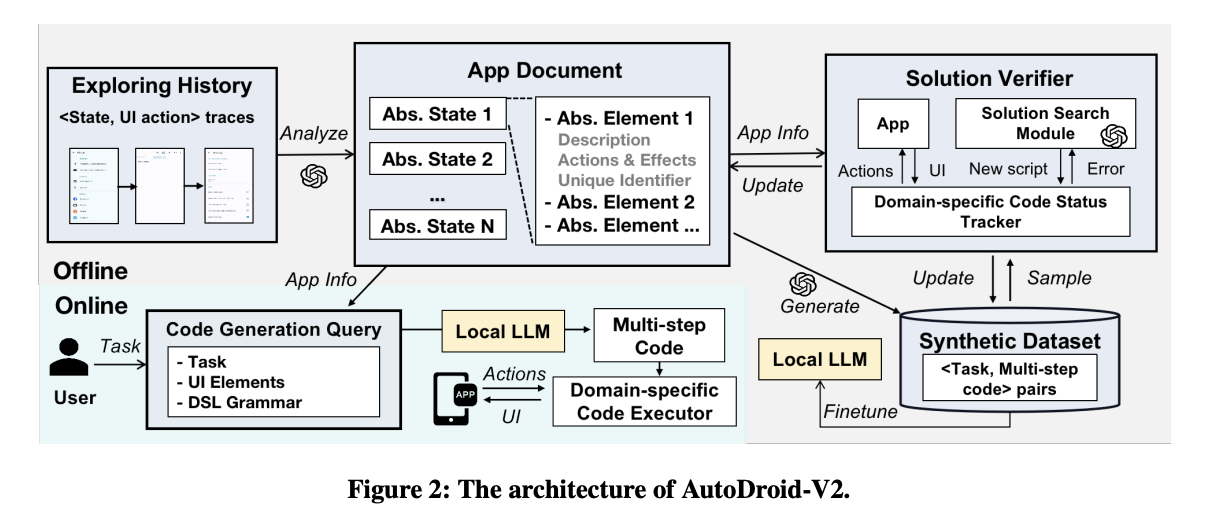
Researchers from the Institute for AI Industry Research (AIR), Tsinghua University have proposed AutoDroid-V2 to investigate how to build a powerful GUI agent upon the coding capabilities of SLMs. Unlike traditional step-wise GUI agents that make decisions one action at a time, AutoDroid-V2 uses a script-based approach that generates and executes multi-step scripts based on user instructions. Moreover, it addresses two critical limitations of conventional approaches:
- Efficiency: Agents can generate a single script for a series of GUI actions to complete a task based on the user task, significantly reducing query frequency and consumption.
- Capability: Script-based GUI agents depend on the coding ability of SLMs, which have been proven effective by numerous existing studies on lightweight coding assistants.
AutoDroid-V2’s architecture consists of two distinct stages: offline and online processing. In the offline stage, the system begins by constructing an app document through a comprehensive analysis of the app exploration history. This document serves as a foundation for script generation, incorporating AI-guided GUI state compression, element XPath auto-generation, and GUI dependency analysis to ensure both conciseness and precision. During the online stage, when a user submits a task request, the customized local LLM generates a multi-step script, which is then executed by a domain-specific interpreter designed to handle runtime execution reliably and efficiently.
AutoDroid-V2’s performance is evaluated across two benchmarks, testing 226 tasks on 23 mobile apps against leading baselines including AutoDroid, SeeClick, CogAgent, and Mind2Web. It shows significant improvements, achieving a 10.5%-51.7% higher task completion rate while reducing computational demands with 43.5x and 5.8x reductions in input and output token consumption respectively, and 5.7-13.4× lower LLM inference latency compared to baselines. Testing across different LLMs (Llama3.2-3B, Qwen2.5-7B, and Llama3.1-8B) AutoDroid-V2, shows consistent performance with success rates ranging from 44.6% to 54.4%, maintaining a stable reversed redundancy ratio between 90.5% and 93.0%.
In conclusion, researchers introduced AutoDroid-V2 which represents a significant advancement in mobile task automation through its innovative document-guided, script-based approach utilizing on-device SLMs. The experimental results demonstrate that this script-based methodology substantially improves the efficiency and performance of GUI agents, achieving accuracy levels comparable to cloud-based solutions while maintaining device-level privacy and security. Despite these achievements, the system faces limitations when dealing with apps lacking structured text representations of their GUIs, such as Unity-based and Web-based applications. However, this challenge could be addressed by integrating VLMs) to recover structured GUI representations based on visual features.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
 FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
The post AutoDroid-V2: Leveraging Small Language Models for Automated Mobile GUI Control appeared first on MarkTechPost.
“}]] [[{“value”:”Large Language Models (LLMs) and Vision Language Models (VLMs) have revolutionized the automation of mobile device control through natural language commands, offering solutions for complex user tasks. The conventional approach, “Step-wise GUI agents,” operates by querying the LLM at each GUI state for dynamic decision-making and reflection, continuously processing the user’s task, and observing the
The post AutoDroid-V2: Leveraging Small Language Models for Automated Mobile GUI Control appeared first on MarkTechPost.”}]] Read More AI Paper Summary, AI Shorts, Applications, Artificial Intelligence, Editors Pick, Machine Learning, Staff, Tech News, Technology