
[[{“value”:”

Large Language Models (LLMs) have revolutionized text generation capabilities, but they face the critical challenge of hallucination, generating factually incorrect information, particularly in long-form content. Researchers have developed Retrieved-Augmented Generation (RAG) to address this issue, which enhances factual accuracy by incorporating relevant documents from reliable sources into the input prompt. While RAG has shown promise, various iterative prompting methods like FLARE and Self-RAG have emerged to improve accuracy further. However, these approaches remain limited by their reliance on traditional RAG architecture, where retrieved context is the only form of online feedback integrated into the input string.
Traditional text generation approaches have evolved through several key methodologies to improve factual accuracy and contextual relevance. The iterative retrieval methods generate responses in segments with each segment utilizing newly retrieved information. ITER-RETGEN exemplifies this approach by using previous outputs to formulate queries for subsequent knowledge retrieval. Adaptive retrieval systems like FLARE and DRAGIN have refined this process by implementing sentence-by-sentence generation with confidence-based verification. Moreover, long-context LLMs have explored memory-based approaches like Memory3, which encode knowledge chunks using KV caches as memories. Other systems like Memorizing Transformers and LongMem have experimented with memory retrieval mechanisms.
A team of researchers from Meta FAIR has proposed EWE (Explicit Working Memory), an innovative AI approach that enhances factual accuracy in long-form text generation by implementing a dynamic working memory system. This system uniquely incorporates real-time feedback from external resources and employs online fact-checking mechanisms to refresh its memory continuously. The key innovation lies in its ability to detect and correct false claims during the generation process itself, rather than relying only on pre-retrieved information. Moreover, the effectiveness of EWE has been shown through comprehensive testing on four fact-seeking long-form generation datasets, showing significant improvements in factuality metrics while maintaining response quality.
The architecture of EWE represents a versatile framework that can adapt to various configurations while maintaining efficiency. At its core, EWE utilizes a multi-unit memory module that can be dynamically updated during generation. This design allows EWE to operate in different modes from simple RAG when using a single memory unit without stopping, to FLARE-like functionality when implementing sentence-level verification. Unlike similar approaches such as Memory3, EWE doesn’t require pre-encoding of all passages and uniquely features dynamic memory updates during the generation process. This flexibility enables parallel processing of different forms of external feedback through distinct memory units.
The experimental results demonstrate significant improvements in factual accuracy across multiple datasets. Using the Llama-3.1 70B base model, retrieval augmentation consistently enhances factuality metrics. While competing approaches show mixed results with Nest performing well only on Biography datasets and DRAGIN showing similar performance to basic retrieval augmentation, EWE achieves the highest VeriScore F1 across all datasets. CoVe, despite high precision, produces shorter responses resulting in lower recall performance. EWE maintains comparable performance to the base model with approximately 50% win rates in helpfulness, measured through AlpacaEval.
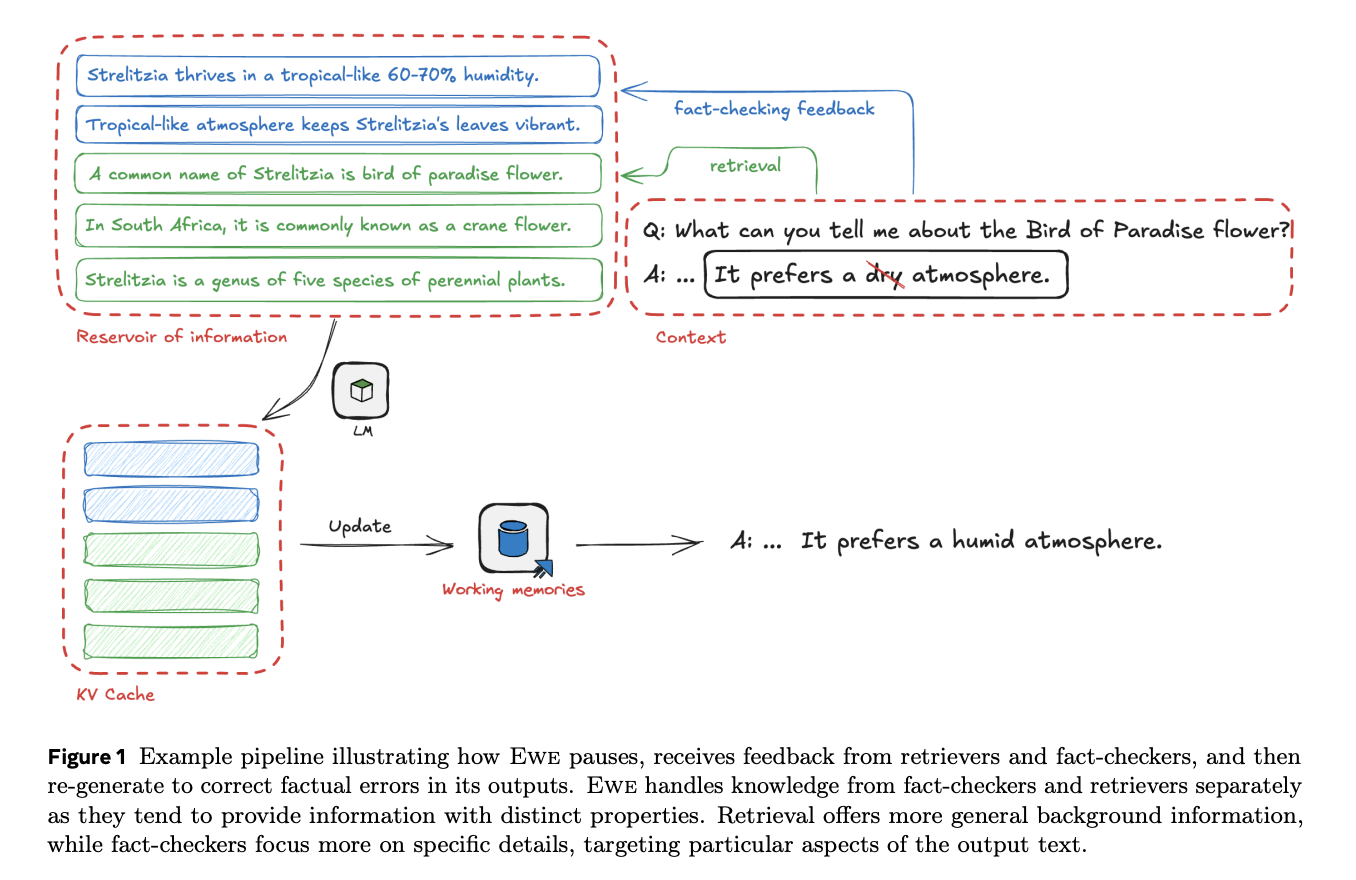
In conclusion, a team from Meta FAIR has introduced EWE (Explicit Working Memory) which represents a significant advancement in addressing the challenge of factual accuracy in long-form text generation. The system’s innovative working memory mechanism, which operates through periodic pauses and memory refreshes based on retrieval and fact-checking feedback, demonstrates the potential for more reliable AI-generated content. This research has identified critical success factors including timely memory updates, focused attention mechanisms, and high-quality retrieval data stores, paving the way for future developments in factual text generation systems.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
 FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
The post Meta AI Introduces EWE (Explicit Working Memory): A Novel Approach that Enhances Factuality in Long-Form Text Generation by Integrating a Working Memory appeared first on MarkTechPost.
“}]] [[{“value”:”Large Language Models (LLMs) have revolutionized text generation capabilities, but they face the critical challenge of hallucination, generating factually incorrect information, particularly in long-form content. Researchers have developed Retrieved-Augmented Generation (RAG) to address this issue, which enhances factual accuracy by incorporating relevant documents from reliable sources into the input prompt. While RAG has shown promise,
The post Meta AI Introduces EWE (Explicit Working Memory): A Novel Approach that Enhances Factuality in Long-Form Text Generation by Integrating a Working Memory appeared first on MarkTechPost.”}]] Read More AI Paper Summary, AI Shorts, Applications, Artificial Intelligence, Editors Pick, Language Model, Large Language Model, Machine Learning, Staff, Tech News, Technology