
[[{“value”:”

Power distribution systems are often conceptualized as optimization models. While optimizing agents to perform tasks works well for systems with limited checkpoints, things begin to go out of hand when heuristics tackle multiple tasks and agents. Scaling dramatically increases the complexity of assignment problems, often NP-hard and nonlinear. Optimization methods become the white elephants in the room, providing suboptimality at high resource consumption. Another major issue with these methods is that their problem setup is dynamic, requiring an iterative, state-based assignment strategy. When one thinks of state in AI, reinforcement learning is the first thing that comes to mind. In the case of assignment applications, given its temporal state-dependent nature, researchers realized the attractive and massive potential of sequential decision-making reinforcement learning. This paper discusses the latest research in state-based assignment, which optimizes its solution through RL.
Researchers from the University of Washington, Seattle, introduced a novel multi-agent reinforcement learning approach for sequential satellite assignment problems. Multi-Agent RL provides solutions for large-scale, realistic scenarios that, with other methods, would have been extravagantly complex. The authors presented a meticulously designed and theoretically justified novel algorithm for solving satellite assignments that ensures specific rewards, guarantees global objectives, and avoids conflicting constraints. The approach integrates existing greedy algorithms in MARL only to improve its solution for long-term planning. The authors also provide the readers with novel insights into its working and global convergence properties through simple experimentation and comparisons.
The methodology that distinguishes it is that agents first learn an expected assignment value; this value serves as the input for an optimally distributed task assignment mechanism. This allows agents to execute joint assignments that satisfy assignment constraints while learning a near-optimal joint policy at the system level. The paper follows a generalized approach to satellite internet constellations, where satellites act as agents. This Satellite Assignment Problem is solved via an RL-enabled Distributed Assignment algorithm(REDA). In this, the authors bootstrap the policy from a non-parameterized greedy policy with which they act at the beginning of training with probability ε. Additionally, to induce further exploration, the authors add randomly distributed noise to Q . Another aspect of REDA that reduces its complexity is its learning target specification, which ensures targets satisfy the constraints.
For evaluation, the authors perform experiments on a simple SAP environment, which they later scale to a complex satellite constellation task allocation environment with hundreds of satellites and tasks. The authors steer the experiments to answer some interesting questions, such as whether REDA encourages unselfish behavior and if REDA can be applied to large problems. The authors reported that REDA immediately drove the group to an optimal joint policy, unlike other methods that encouraged selfishness. For the highly complex scaled SAP, REDA yielded low variance and consistently outperformed all other methods. Overall, the authors reported an increase of 20% to 50% over other state-of-the-art methods.
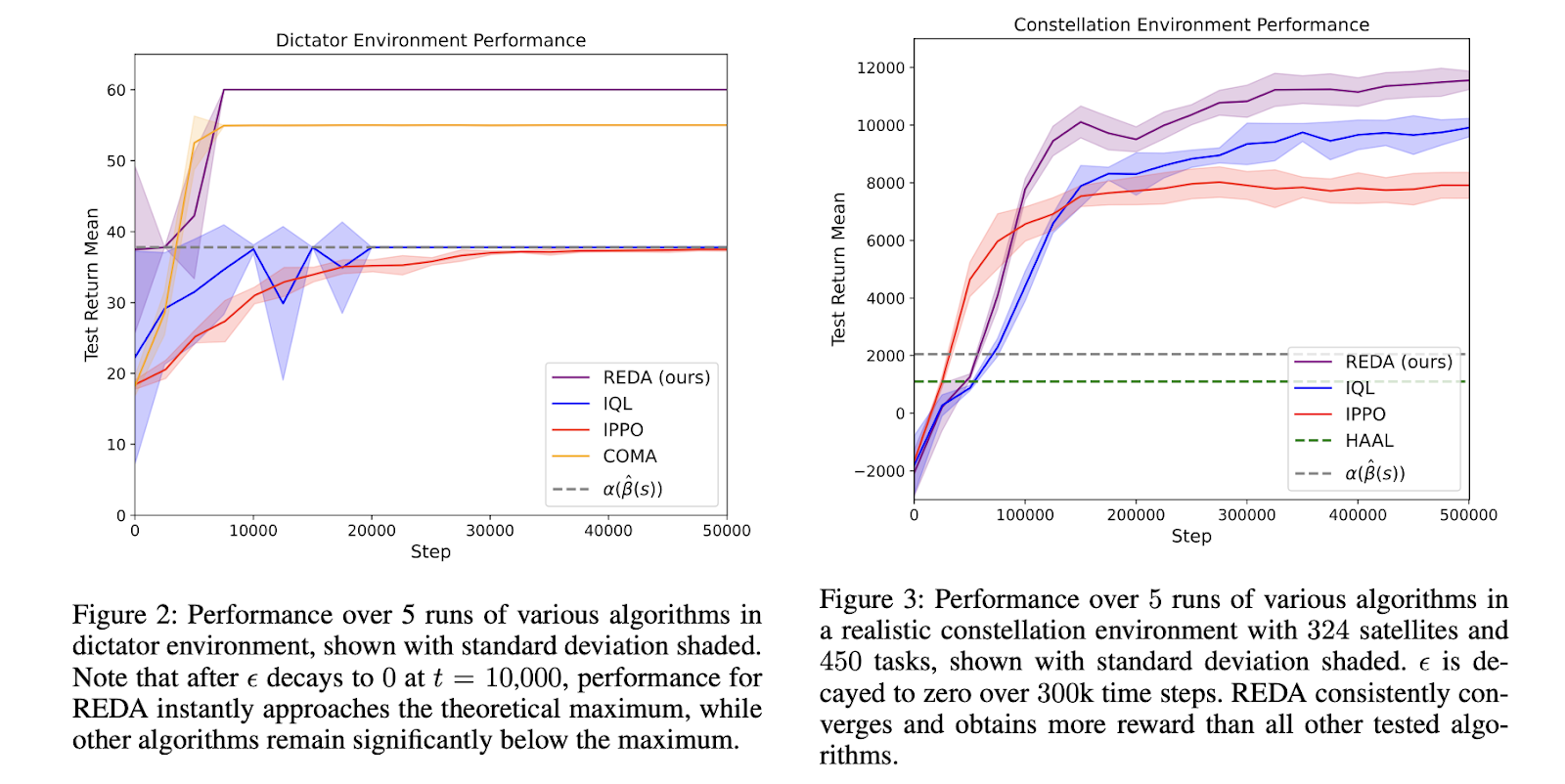
Conclusion: This paper discussed REDA, a novel Multi-Agent Reinforcement Learning approach for solving complex state-dependent assignment problems. The paper addresses satellite assignment problems and teaches agents to act unselfishly while learning efficient solutions, even in large problem settings.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
 FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
The post REDA: A Novel AI Approach to Multi-Agent Reinforcement Learning That Makes Complex Sequence-Dependent Assignment Problems Solvable appeared first on MarkTechPost.
“}]] [[{“value”:”Power distribution systems are often conceptualized as optimization models. While optimizing agents to perform tasks works well for systems with limited checkpoints, things begin to go out of hand when heuristics tackle multiple tasks and agents. Scaling dramatically increases the complexity of assignment problems, often NP-hard and nonlinear. Optimization methods become the white elephants in
The post REDA: A Novel AI Approach to Multi-Agent Reinforcement Learning That Makes Complex Sequence-Dependent Assignment Problems Solvable appeared first on MarkTechPost.”}]] Read More AI Agents, AI Paper Summary, AI Shorts, Applications, Artificial Intelligence, Editors Pick, Language Model, Reinforcement Learning, Staff, Tech News, Technology