
[[{“value”:”

Owing to the advent of Artificial Intelligence (AI), the software industry has been leveraging Large Language Models (LLMs) for code completion, debugging, and generating test cases. However, LLMs follow a generic approach when developing test cases for a different software, which prevents them from considering the software’s unique architecture, user requirements and potential edge cases. Moreover, different outputs are obtained from the same prompt when using other software, which raises the question of the prompt’s reliability. Due to these issues, critical bugs can go undetected, which increases the overall expenditure and ultimately hinders the software’s practical deployment in sensitive industries like healthcare. A team of researchers from the Chinese University of Hong Kong, Harbin Institute of Technology, School of Information Technology, and some independent researchers have introduced MAPS, the prompt alchemist for tailored optimizations and contextual understanding.
Traditional test case generation approaches rely on rule-based systems or manual engineering of prompts for Large Language Models (LLMs). These methods have been foundational in software testing but exhibit several limitations. Most researchers use manual methods to optimize prompt engineering for test case generation, which requires significant time investment. These methods are also difficult to scale due to the increase in complexity. Other methods are often generic in nature, producing bugs. Therefore, a new approach is needed for test case generation that can prevent labor-intensive manual optimization and does not lead to suboptimal outcomes.
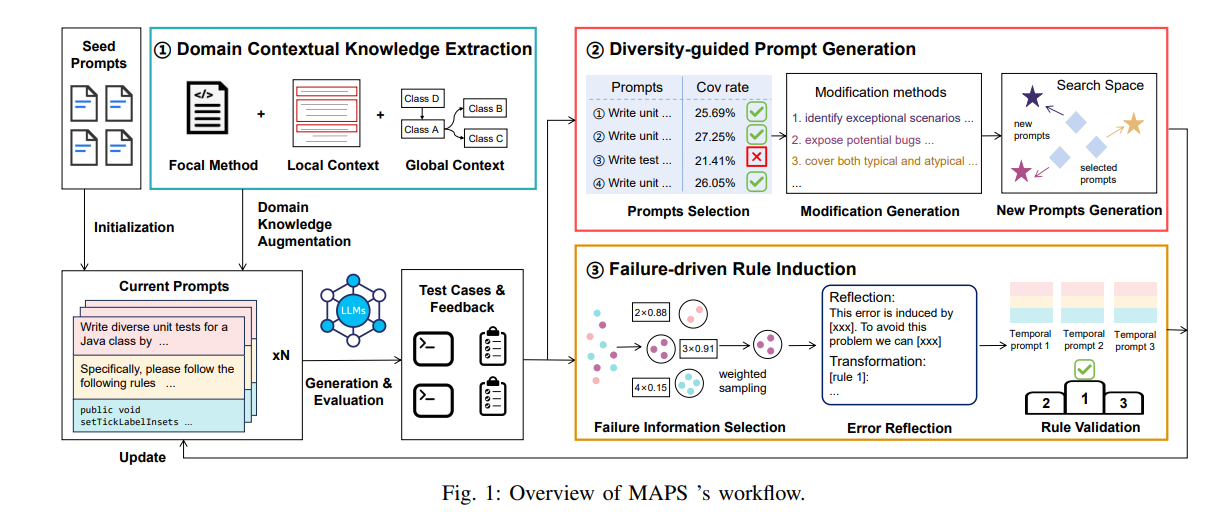
The proposed method, MAPS, automates the prompt optimization process, aligning the test cases with real-world requirements significantly reducing human intervention. The core framework of MAPS includes:
- Baseline Prompt Evaluation: LLMs are assessed on their performance on test cases generated using basic prompts. This assessment is foundational to further optimization efforts needed.
- Feedback Loop: Based on the evaluation results, suboptimally performing test cases are set aside and tweaked to better align with software requirements. This information is fed back into the LLM, allowing for continuous improvement in a feedback loop.
- LLM-Specific Tuning: The reinforcement learning techniques are used for dynamic prompt optimization. This opens a space for customizations in the prompt by taking into account the strengths and weaknesses of the LLMs.
The results showed that MAPS significantly outperformed the traditional prompt engineering techniques. Its optimized prompts had a 6.19% higher line coverage rate than static prompts. The framework identified more bugs than the baseline methods, exhibiting its ability to effectively generate edge case scenarios. Test cases generated with optimized prompts exhibited improvement in semantic correctness, which reduced the need for manual adjustments.
In a nutshell, MAPS is a state-of-the-art optimization technique for prompt generation, particularly targeted to LLMs used in the software testing domain. Some of the weaknesses of the available test case generation techniques have been addressed through multi-pipeline-stage architectures that incorporate baseline evaluations, iterative feedback loops, and model-specific tuning. These new characteristics of the framework not only automate prompt optimization but enhance the quality and reliability of outputs in automated testing workflows, thus making it an indispensable tool for software development teams looking for efficiency and effectiveness in their testing processes.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
 FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
FREE UPCOMING AI WEBINAR (JAN 15, 2025): Boost LLM Accuracy with Synthetic Data and Evaluation Intelligence–Join this webinar to gain actionable insights into boosting LLM model performance and accuracy while safeguarding data privacy.
The post The Prompt Alchemist: Automated LLM-Tailored Prompt Optimization for Test Case Generation appeared first on MarkTechPost.
“}]] [[{“value”:”Owing to the advent of Artificial Intelligence (AI), the software industry has been leveraging Large Language Models (LLMs) for code completion, debugging, and generating test cases. However, LLMs follow a generic approach when developing test cases for a different software, which prevents them from considering the software’s unique architecture, user requirements and potential edge cases.
The post The Prompt Alchemist: Automated LLM-Tailored Prompt Optimization for Test Case Generation appeared first on MarkTechPost.”}]] Read More AI Paper Summary, AI Shorts, Applications, Artificial Intelligence, Editors Pick, Staff, Tech News, Technology