
[[{“value”:”
Table of Contents
- What Is YOLO11?
- Key Features of YOLO11
- Supported Tasks
- Supported Modes
- Available Checkpoints
- Configuring Your Development Environment
- Setup and Imports
- How to Run Inference with YOLO11
- Object Detection
- Instance Segmentation
- Image Classification
- Pose Estimation
- Oriented Object Detection
- Multi-Object Tracking
Getting Started with YOLO11
In this tutorial, we will provide a concise overview of YOLO11 and explore its capabilities, showcasing what can be achieved with this powerful model.

To learn how to master YOLO11 and harness its capabilities for various computer vision tasks, just keep reading.
What Is YOLO11?
YOLO11 is the newest version of the popular Ultralytics YOLO (You Only Look Once) series of real-time object detection models. It takes the strengths of previous versions and pushes them even further with better accuracy, faster performance, and more efficient processing. With improvements in its design and training techniques, YOLO11 can handle a variety of computer vision tasks, making it a flexible and powerful tool for developers and researchers alike.
Though Ultralytics has not provided a formal research paper for YOLO11 yet, the focus remains on advancing the model’s capabilities and ensuring it is user-friendly.
How would you like immediate access to 3,457 images curated and labeled with hand gestures to train, explore, and experiment with … for free? Head over to Roboflow and get a free account to grab these hand gesture images.
Key Features of YOLO11
- High Speed and Efficiency
- YOLO11 is built with a refined architecture, ensuring faster processing speeds.
- Optimized training pipelines allow it to handle tasks efficiently without sacrificing accuracy.
- Improved Feature Representation
- The model incorporates an enhanced backbone for extracting richer features.
- A redesigned neck architecture ensures better performance in detecting objects and handling complex visual tasks.
- Enhanced Accuracy with Reduced Complexity
- YOLO11m achieves a higher mean Average Precision (mAP) on the COCO (Common Objects in Context) dataset.
- Despite the improved accuracy, it uses 22% fewer parameters compared to YOLOv8m, making it lightweight and efficient.
- Broad Range of Task Support
- YOLO11 is capable of handling multiple computer vision tasks:
- Object detection
- Instance segmentation
- Image classification
- Pose estimation
- Oriented object detection
- Multi-Object Tracking
- YOLO11 is capable of handling multiple computer vision tasks:
- Versatile Deployment
- YOLO11 can be seamlessly deployed on edge devices for real-time applications.
- It supports cloud platforms for scalable processing.
- Compatibility with NVIDIA GPUs ensures smooth operation on high-performance systems.
This breakdown makes YOLO11 versatile, fast, and ideal for modern computer vision challenges.
Supported Tasks
YOLO11 is designed to handle a wide range of computer vision tasks with high efficiency and accuracy. The supported tasks include:
- Object Detection: Detects and locates objects within an image.
- Instance Segmentation: Identify and segment individual objects in an image.
- Image Classification: Assign a label to the entire image based on its content.
- Pose/Keypoints Estimation: Detect key points of interest in humans or objects to estimate pose.
- Oriented Object Detection: Detect objects with orientation angles (e.g., rotated bounding boxes).
- Multi-Object Tracking: Available for Detect, Segment, and Pose models, enabling real-time tracking of objects across frames.
We will explore these tasks (Figure 1) in detail while running inference with YOLO11.

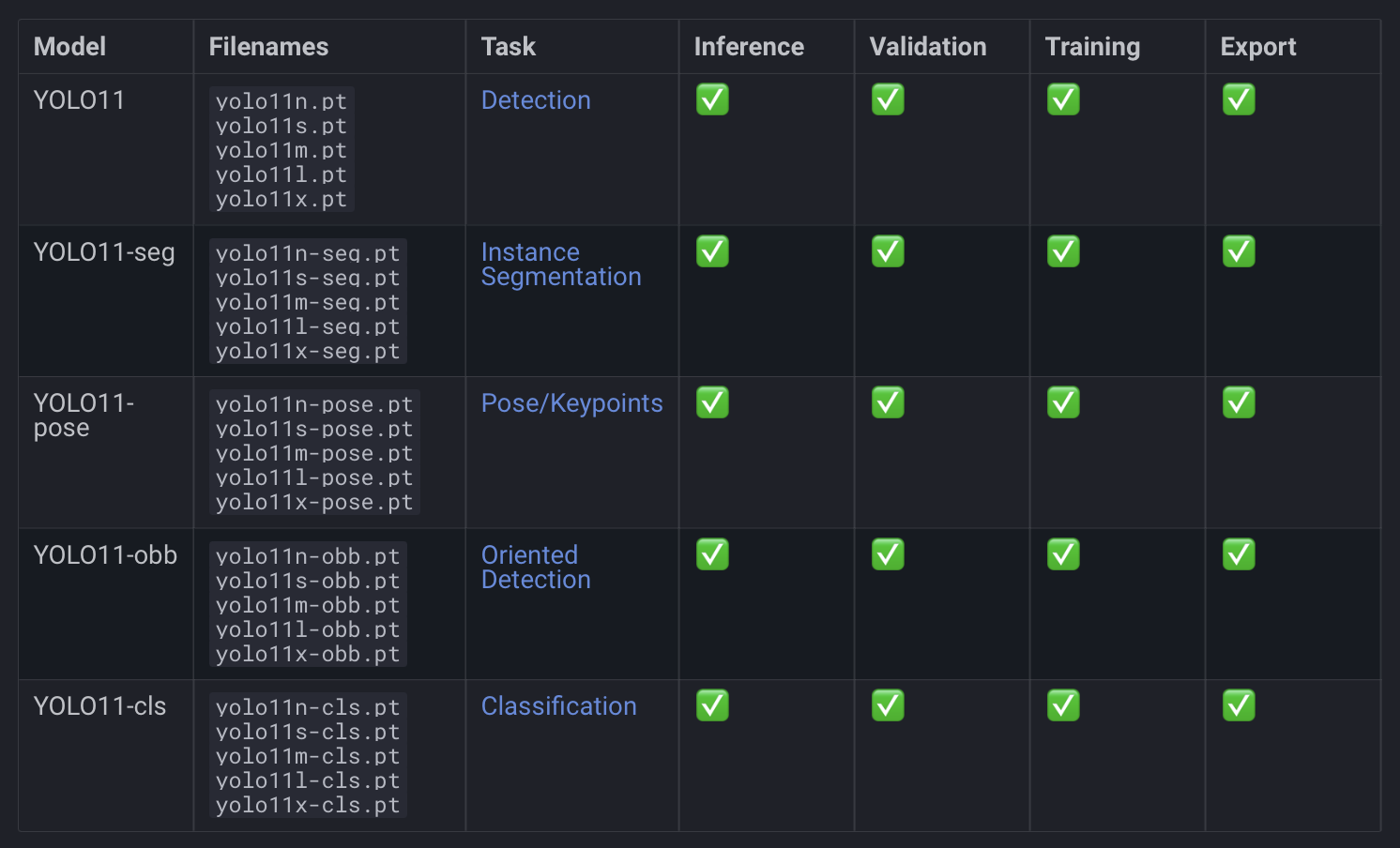
Supported Modes
In addition to its diverse task capabilities, YOLO11 supports 4 key modes:
- Inference: Perform predictions on new data.
- Validation: Evaluate model performance on a validation dataset.
- Training: Train the model on custom datasets.
- Export: Convert the model to other formats like ONNX (Open Neural Network Exchange) or TensorFlow for broader deployment.
Available Checkpoints
YOLO11 provides 5 model sizes, ensuring flexibility to balance speed, accuracy, and resource usage:
- n (Nano): Ultra-lightweight, optimized for edge devices.
- s (Small): Suitable for scenarios requiring faster inference with moderate accuracy.
- m (Medium): Balanced between accuracy and speed.
- l (Large): Designed for high-accuracy tasks.
- x (Extra-large): Maximum accuracy for resource-intensive applications.
The model sizes can be combined with specific tasks, resulting in the following checkpoints:
- Object Detection:
yolo11<size>.pt - Instance Segmentation:
yolo11<size>-seg.pt - Image Classification:
yolo11<size>-cls.pt - Pose/Keypoints Estimation:
yolo11<size>-pose.pt - Oriented Object Detection:
yolo11<size>-obb.pt
This modularity allows YOLO11 to cater to diverse application needs efficiently.
In Figure 2, we can see the Supported Tasks, Modes, and Available Checkpoints.
Configuring Your Development Environment
To get started with YOLO11 and follow along with this guide, you need to install the Ultralytics library. This library simplifies the process of using state-of-the-art YOLO models for various computer vision tasks.
Ultralytics is pip-installable:
%pip install -q ultralytics
Need Help Configuring Your Development Environment?

All that said, are you:
- Short on time?
- Learning on your employer’s administratively locked system?
- Wanting to skip the hassle of fighting with the command line, package managers, and virtual environments?
- Ready to run the code immediately on your Windows, macOS, or Linux system?
Then join PyImageSearch University today!
Gain access to Jupyter Notebooks for this tutorial and other PyImageSearch guides pre-configured to run on Google Colab’s ecosystem right in your web browser! No installation required.
And best of all, these Jupyter Notebooks will run on Windows, macOS, and Linux!
Setup and Imports
Once installed, we can verify our setup and import the necessary libraries to get started.
import ultralytics ultralytics.checks()

from ultralytics import YOLO from huggingface_hub import hf_hub_download import cv2 import matplotlib.pyplot as plt
Now, import YOLO from the Ultralytics library to load and run the YOLO11 model, hf_hub_download from huggingface_hub to download files from the hub (video file here), OpenCV (cv2) for image manipulation and preprocessing, and Matplotlib for visualizing the results.
How to Run Inference with YOLO11
Now, let’s explore how to run inference with YOLO11. In this section, we’ll walk through using YOLO11, along with a few essential libraries, to perform tasks such as object detection, pose estimation, and tracking in video frames, among others.
Object Detection
Object detection focuses on recognizing and locating objects within an image or video stream by assigning them specific categories.
The result of an object detection model is a collection of bounding boxes that outline the detected objects, accompanied by class labels and confidence scores. This technique is ideal for pinpointing objects of interest in a scene without requiring precise details about their exact location or shape.
YOLO11 object detection models are pre-trained on the COCO dataset.
Using Python
# Load a model
model = YOLO("yolo11n.pt")
# Predict with the model
results = model("https://ultralytics.com/images/bus.jpg")
First, we load the YOLO11 object detection model. Here, yolo11n.pt represents the “nano” version of the model, which is lightweight and optimized for speed.
Next, we use the model to predict objects in an image. For this example, we use an image of a bus from a URL. The model() function takes the image URL as input, processes it, and outputs the predictions.
# Visualize predictions
result_image = results[0].plot()
plt.imshow(result_image)
plt.axis('off')
plt.show()
To visualize the results, we use the plot() method on the predictions. This method overlays the detected objects and labels onto the image. Finally, we display the annotated image using Matplotlib.
Using CLI
!yolo detect predict model=yolo11n.pt source='https://ultralytics.com/images/bus.jpg'
If you prefer command-line interface (CLI) tools, YOLO11 offers a convenient way to run inference directly from the terminal. The following command uses the same yolo11n.pt model and processes the bus image. The results are saved to an output directory (runs/detect/predict/, and can be inspected visually.
We must note 2 key points:
- The Python approach gives us more flexibility to integrate the model into larger projects and customize the outputs programmatically.
- The CLI method is perfect for quick experiments and running inference without diving into code.
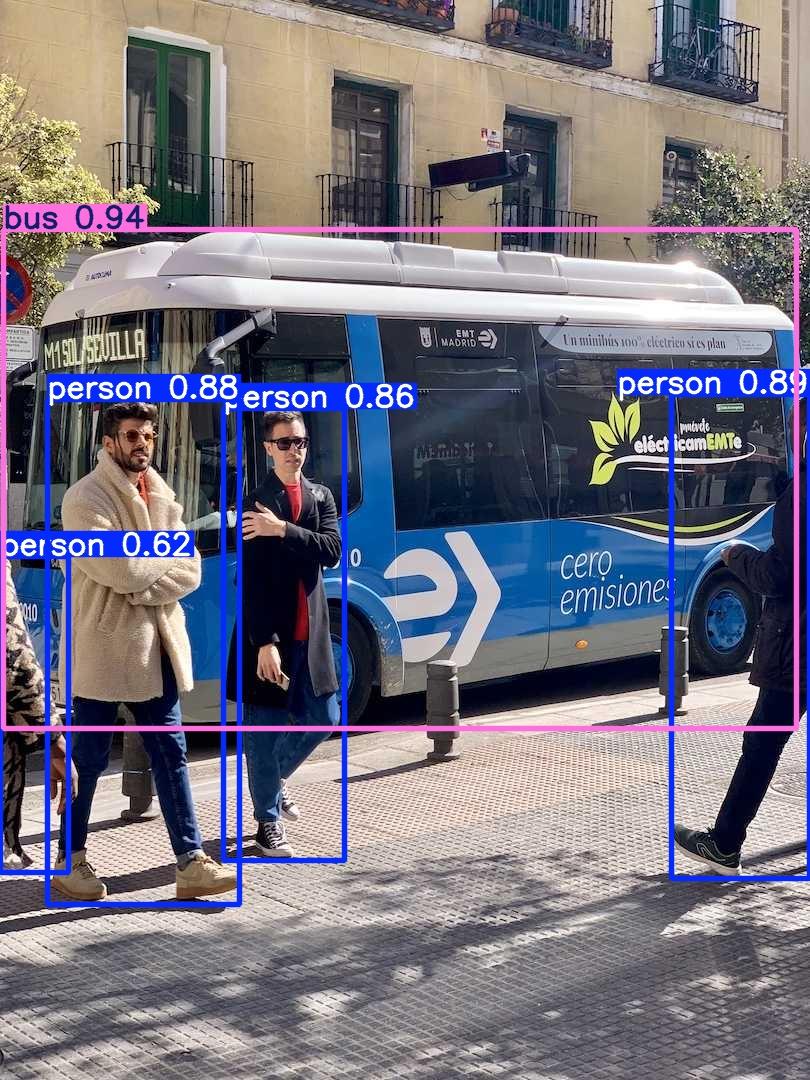
In Figure 3, we can see the object detection output generated by using either Python or CLI.
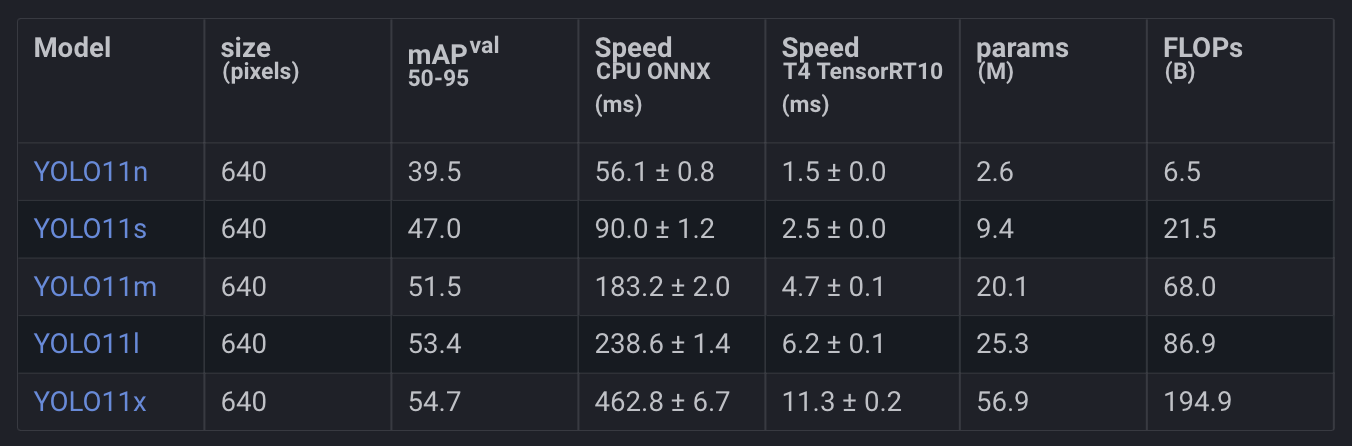
In Figure 4, we can see the YOLO11 performance on COCO Object Detection.
Instance Segmentation
Instance segmentation builds upon object detection by not only identifying individual objects in an image but also segmenting them into precise regions.
Unlike object detection, which provides bounding boxes around objects, instance segmentation generates detailed masks or contours that trace the exact shape of each object. Alongside these masks, it also outputs class labels and confidence scores for every detected object. This makes instance segmentation ideal for scenarios where understanding the precise shape and boundaries of objects is critical.
YOLO11 instance segmentation models are pre-trained on the COCO dataset.
Using Python
# Load a model
model = YOLO("yolo11n-seg.pt")
# Predict with the model
results = model("https://ultralytics.com/images/bus.jpg")
The Python code remains the same as above. The only difference is the use of the segmentation model represented by seg in yolo11n-seg.pt.
# Visualize predictions
result_image = results[0].plot()
plt.imshow(result_image)
plt.axis('off')
plt.show()
The visualization code remains the same as above.
Using CLI
!yolo segment predict model=yolo11n-seg.pt source='https://ultralytics.com/images/bus.jpg'
The command for segmentation remains the same as above. The only difference is the use of the segment command. The results are saved to an output directory (runs/segment/predict/), and can be inspected visually.
In Figure 5, we can see the instance segmentation output generated by using either Python or CLI.

In Figure 6, we can see the YOLO11 performance on COCO Instance Segmentation.
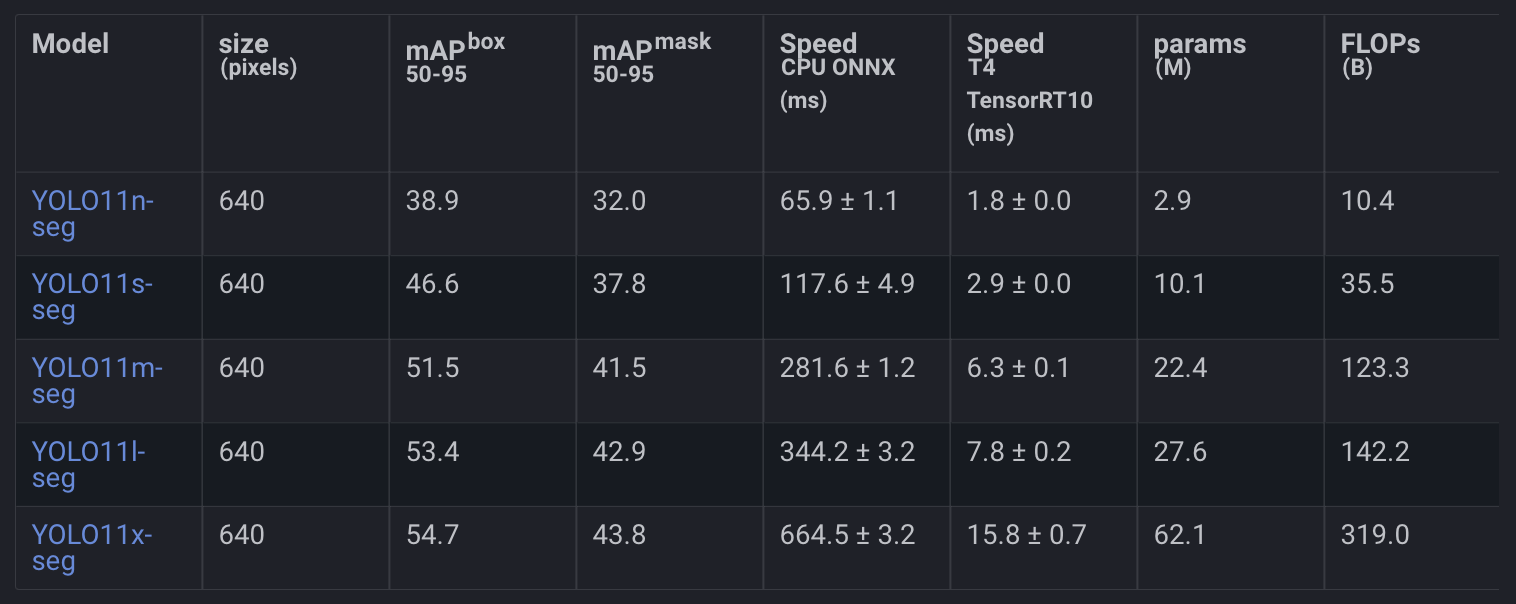
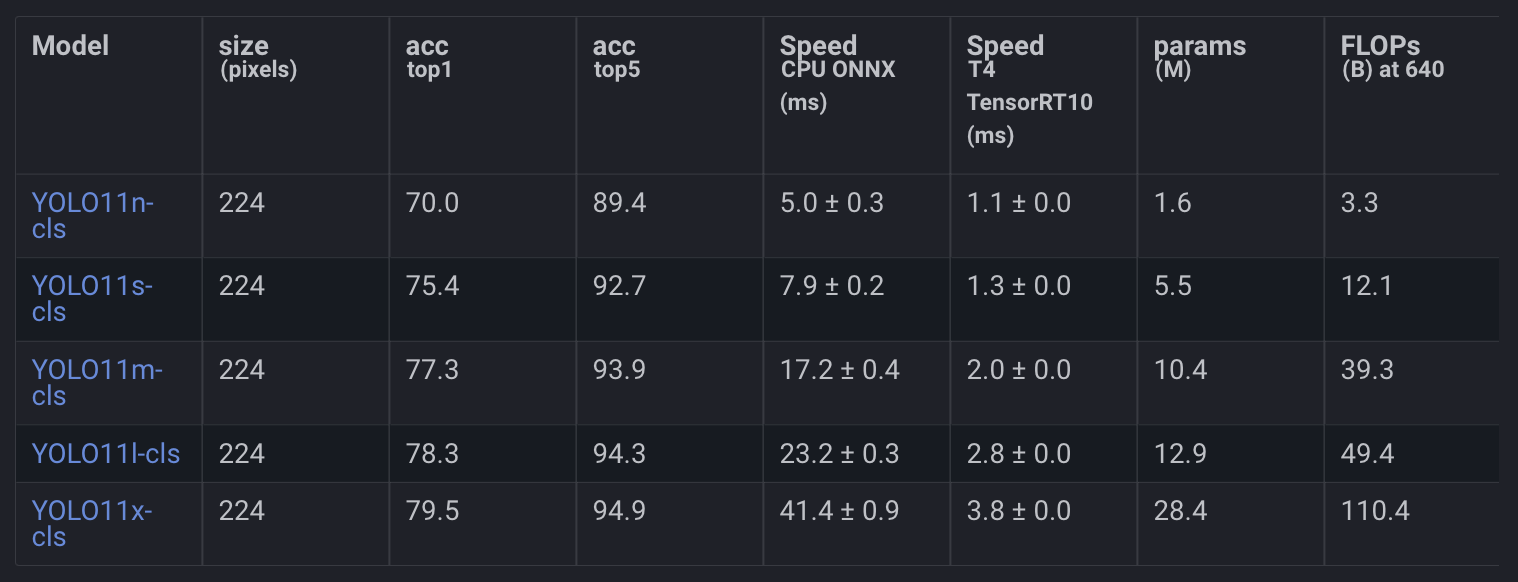
Image Classification
Image classification is one of the fundamental tasks in computer vision, focusing on assigning a class to an image.
The result of an image classification model is a class label paired with a confidence score, indicating the likelihood of the image belonging to that class. This task is particularly useful when the goal is to identify the category of an image without needing information about the location or shape of specific objects within it.
YOLO11 image classification models are pre-trained on the ImageNet dataset.
Using Python
# Load a model
model = YOLO("yolo11n-cls.pt")
# Predict with the model
results = model("https://ultralytics.com/images/bus.jpg")
The Python code remains the same as above. The only difference is the use of the classification model represented by cls in yolo11n-cls.pt.
# Visualize predictions
result_image = results[0].plot()
plt.imshow(result_image)
plt.axis('off')
plt.show()
The visualization code remains the same as above.
Using CLI
!yolo classify predict model=yolo11n-cls.pt source='https://ultralytics.com/images/bus.jpg'
The command for classification remains the same as above. The only difference is the use of the classify command. The results are saved to an output directory (runs/classify/predict/), and can be inspected visually.
In Figure 7, we can see the image classification output generated by using either Python or CLI.

In Figure 8, we can see the YOLO11 performance on ImageNet Image Classification.
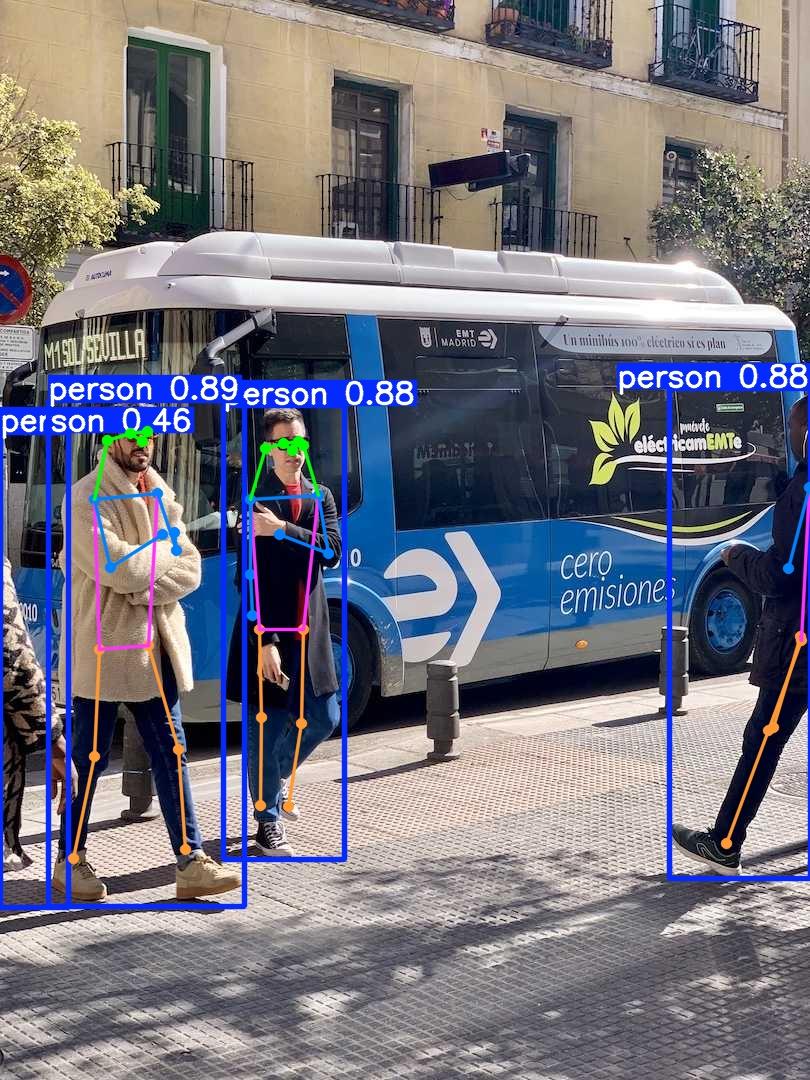
Pose Estimation
Pose estimation focuses on pinpointing specific locations in an image, commonly referred to as keypoints. These keypoints often correspond to notable features such as joints, landmarks, or other distinct parts of an object. The positions are typically expressed as a set of 2D [x, y] coordinates or 3D [x, y, visible] coordinates.
The output of a pose estimation model is a collection of keypoints that outline the object in the image, accompanied by confidence scores for each point. This task is ideal for scenarios where understanding the precise location and spatial arrangement of specific parts of an object is essential.
YOLO11 pose estimation models are pre-trained on the COCO Keypoints dataset.
Using Python
# Load a model
model = YOLO("yolo11n-pose.pt")
# Predict with the model
results = model("https://ultralytics.com/images/bus.jpg")
The Python code remains the same as above. The only difference is the use of the pose estimation model represented by pose in yolo11n-pose.pt.
# Visualize predictions
result_image = results[0].plot()
plt.imshow(result_image)
plt.axis('off')
plt.show()
The visualization code remains the same as above.
Using CLI
!yolo pose predict model=yolo11n-pose.pt source='https://ultralytics.com/images/bus.jpg'
The command for pose estimation remains the same as above. The only difference is the use of the pose command. The results are saved to an output directory (runs/pose/predict/), and can be inspected visually.
In Figure 9, we can see the pose estimation output generated by using either Python or CLI.
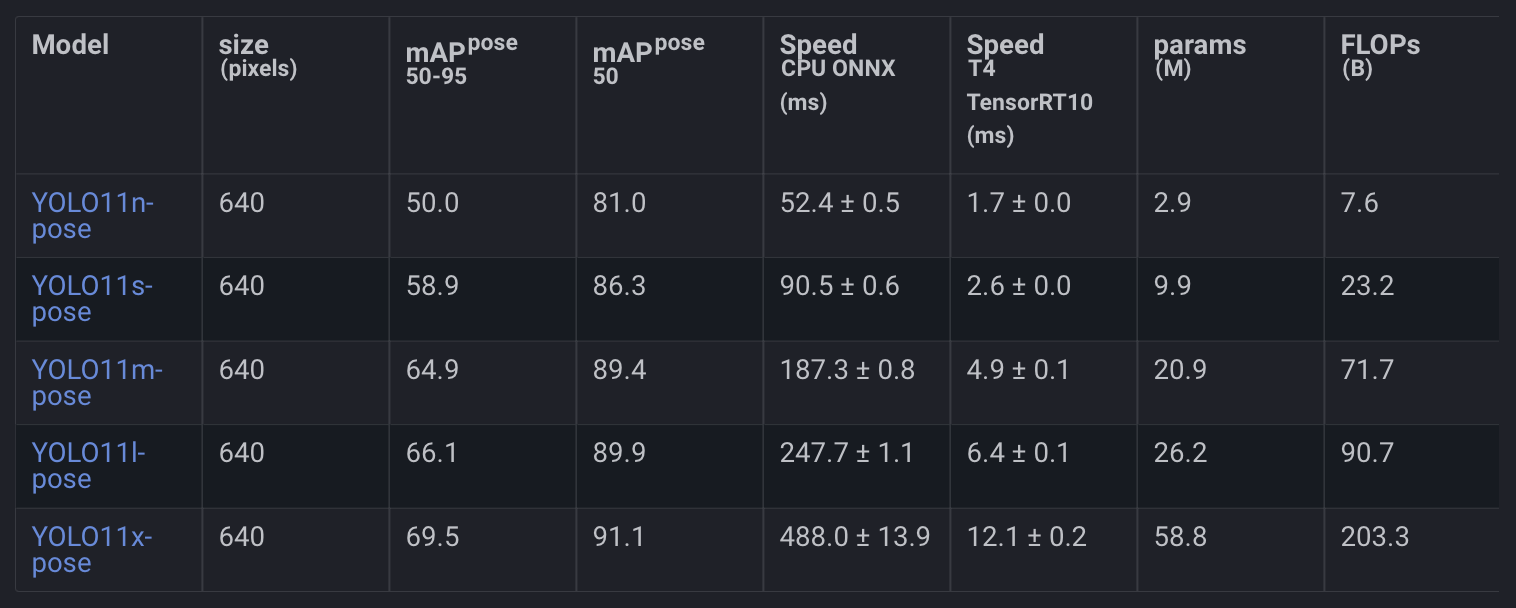
In Figure 10, we can see the YOLO11 performance on COCO Pose Estimation.
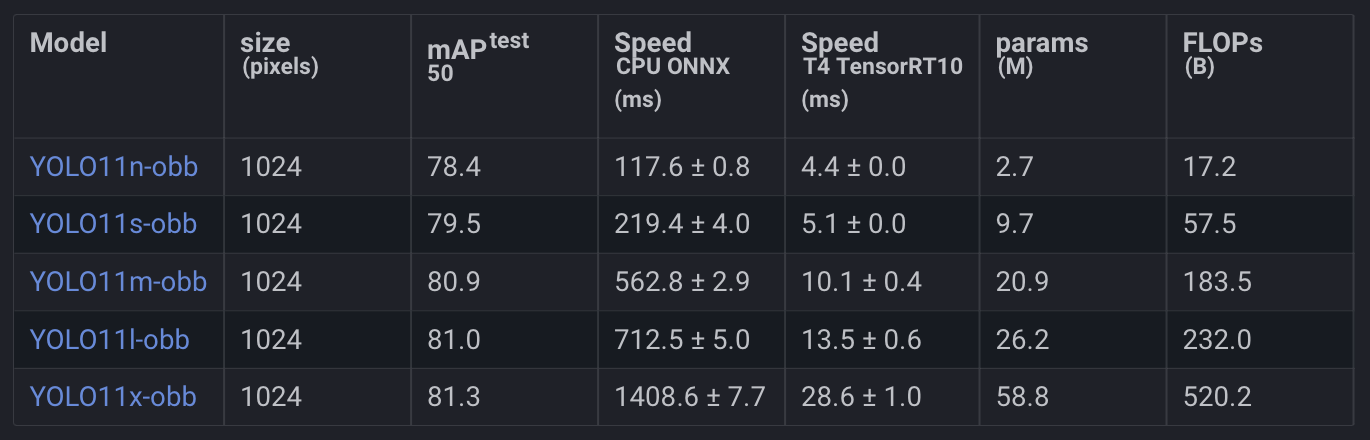
Oriented Object Detection
Oriented object detection enhances standard object detection by incorporating an additional angle parameter, allowing for more precise localization of objects within an image.
The output from an oriented object detection model consists of rotated bounding boxes that tightly fit the objects, along with class labels and confidence scores for each box. This approach is particularly effective in scenarios where standard rectangular bounding boxes may not suffice, and the exact shape of the object is required.
YOLO11 oriented object detection models are pre-trained on the DOTAv1 dataset.
Using Python
# Load a model
model = YOLO("yolo11n-obb.pt")
# Predict with the model
results = model("https://ultralytics.com/images/boats.jpg")
The Python code remains the same as above. The only difference is the use of the oriented object detection model represented by obb in yolo11n-obb.pt.
# Visualize predictions
result_image = results[0].plot()
plt.imshow(result_image)
plt.axis('off')
plt.show()
The visualization code remains the same as above.
Using CLI
!yolo obb predict model=yolo11n-obb.pt source='https://ultralytics.com/images/boats.jpg'
The command for oriented object detection remains the same as above. The only difference is the use of the obb command. The results are saved to an output directory (runs/obb/predict/), and can be inspected visually.
In Figure 11, we can see the oriented object detection output generated by using either Python or CLI.

In Figure 12, we can see the YOLO11 performance on DOTAv1 Oriented Object Detection.
Multi-Object Tracking
Multi-object tracking is an essential technique in computer vision, where we track and analyze multiple objects across a series of video frames. Using advanced models like Detect, Segment, and Pose, we can identify and follow objects, people, or keypoints in dynamic scenes. Track mode, available for all of these models, allows us to seamlessly monitor these objects, even as they move and change positions within the video. Whether you’re working on tracking athletes in sports videos or monitoring poses in complex environments, this approach provides a robust solution for real-time or batch-processing tasks.
# Load the YOLO11 pose estimation model
model = YOLO("yolo11n-pose.pt")
To get started with multi-object tracking using the YOLO11 pose estimation model, we first load the model by using the YOLO class and the corresponding model file, yolo11n-pose.pt. This is the foundation for performing pose detection with tracking capabilities across frames.
# Load a video for tracking input_video_path = hf_hub_download( repo_id="pyimagesearch/images-and-videos", repo_type="dataset", filename="sport-007.mp4" ) cap = cv2.VideoCapture(input_video_path)
Next, we download the input video from the pyimagesearch/images-and-videos repository using the hf_hub_download() function. This makes it easy to retrieve the video file directly from the Hugging Face hub. Once the download is complete, we load the video using the cv2.VideoCapture() function, which allows us to read and process the video frame by frame.
# Check if the video file is loaded successfully
if not cap.isOpened():
print("Error: Cannot open video file.")
exit()
Once the video is loaded, we ensure it has been opened successfully by checking the cap.isOpened() method. If, for any reason, the video can’t be opened, we print an error message and exit the program.
# Get video properties frame_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)) frame_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)) fps = int(cap.get(cv2.CAP_PROP_FPS)) fourcc = cv2.VideoWriter_fourcc(*'mp4v') # Codec for output video
After that, we extract the essential properties of the video: the frame width and height (to match the resolution in the output), the frame rate (fps), and the codec type (mp4v). These properties will help us maintain the video’s original quality during processing and save it in the correct format.
# Define the output video writer output_path = "output_video.mp4" # Path to save the processed video out = cv2.VideoWriter(output_path, fourcc, fps, (frame_width, frame_height))
Now, we define an output path for the processed video and initialize the video writer using cv2.VideoWriter(). This step ensures that the processed frames are saved correctly in the desired video format (MP4 in our case) with the same frame rate and resolution as the original video.
# Process video frames
while True:
ret, frame = cap.read()
if not ret:
break # Exit the loop if no frames are left to process
# Run pose estimation with tracking enabled
results = model.track(frame, task="pose")
# Visualize the tracked poses on the frame
result_frame = results[0].plot() # Draw keypoints and bounding boxes
# Write the frame to the output video
out.write(result_frame)
# Release resources
cap.release()
out.release()
print(f"Pose estimation video saved as {output_path}")
Inside the loop, for each frame, we pass it to the YOLO11 model for pose estimation with the model.track() function. The argument task="pose" specifies that we are detecting poses in the video. This method not only estimates poses but also tracks them across multiple frames, providing keypoints and bounding boxes for each pose. After that, we use the results[0].plot() function to overlay these detected poses onto the current frame, creating a visual representation of the tracked poses.
We then write the annotated frame to the output video file using the out.write() function. This process continues for every frame in the video. When all frames have been processed, we release the video capture and writer objects using cap.release() and out.release(), freeing up system resources. Finally, a message is displayed to confirm that the pose-estimated video has been saved successfully. This gives us a smooth, tracked output video with poses estimated in each frame.
In Figure 13, we can see the output video generated for multi-object tracking for pose estimation.

How to Train with YOLO11
Training a deep learning model is a crucial step in building a solution for tasks like object detection. It involves adjusting the model’s parameters based on data to improve its prediction accuracy. YOLO11 offers a powerful and user-friendly Train mode, designed to leverage modern hardware for efficient training.
YOLO11’s Train mode stands out for its efficiency, flexibility, and ease of use. Here are some reasons to choose YOLO11 for training:
- Optimized to make full use of single-GPU or multi-GPU setups, enabling faster and more efficient training.
- Train on standard datasets like COCO, VOC (Visual Object Classes), and ImageNet, or use custom datasets tailored to your specific needs.
- Intuitive CLI and Python APIs make it easy to set up and execute training tasks.
- Customize a wide range of hyperparameters to fine-tune your model’s performance.
Using Python
To train a model using Python, follow these steps:
# Load a model
model = YOLO("yolo11n.yaml") # build a new model from YAML
model = YOLO("yolo11n.pt") # load a pretrained model (recommended for training)
model = YOLO("yolo11n.yaml").load("yolo11n.pt") # build from YAML and transfer weights
# Train the model
results = model.train(data="coco8.yaml", epochs=100, imgsz=640)
To train a YOLO11 model, we begin by loading it. There are several ways to initialize the model, depending on your use case. First, we can build a new model from a YAML configuration file using YOLO("yolo11n.yaml"). This approach is useful if you want to customize the architecture or start from scratch. Alternatively, we can load a pretrained model with YOLO("yolo11n.pt"), which is the recommended approach for training as it provides a strong starting point based on prior knowledge. Finally, we can combine both approaches by building the model from YAML and transferring pretrained weights using YOLO("yolo11n.yaml").load("yolo11n.pt").
Once the model is loaded, we train it using the model.train() function. Here, we specify the dataset configuration file (coco8.yaml) as the data parameter. We also set the number of training epochs to 100 and the image size (imgsz) to 640 pixels, ensuring the model is trained efficiently on the dataset. During training, YOLO11 will fine-tune its parameters to optimize performance on the specified dataset.
Using CLI
If you prefer the command-line interface, YOLO11 provides a straightforward way to initiate training:
# Build a new model from YAML and start training from scratch !yolo detect train data=coco8.yaml model=yolo11n.yaml epochs=100 imgsz=640 # Start training from a pretrained *.pt model !yolo detect train data=coco8.yaml model=yolo11n.pt epochs=100 imgsz=640 # Build a new model from YAML, transfer pretrained weights to it and start training !yolo detect train data=coco8.yaml model=yolo11n.yaml pretrained=yolo11n.pt epochs=100 imgsz=640
In these commands:
- Training from Scratch: Starts training from an initial state using a YAML file.
- Fine-Tuning: Loads a pretrained model for further training.
- Transfer Learning: Combines pretrained weights with a new model configuration for customized training.
How to Validate with YOLO11
Validation is an essential step in the machine learning workflow that helps assess the performance of trained models. YOLO11 makes this process easy with its Validation mode, which offers a comprehensive set of tools to evaluate the model’s quality. By validating the model, one can ensure that it is accurate, reliable, and ready for deployment in real-world scenarios.
Validation provides critical insights into how well the YOLO11 model performs across various metrics. Here are some key reasons why the YOLO11 Validation mode is advantageous:
- YOLO11 computes metrics (e.g.,
mAP50,mAP75, andmAP50-95) to give a detailed evaluation of the model’s performance. - Models retain their training settings, simplifying the validation process by using the same configurations for evaluation.
- Validate the model with the same dataset used for training or try it with different datasets to test its generalization.
- Use validation results to adjust hyperparameters and fine-tune the model for better results.
Using Python
Here’s how to validate the YOLO11 model using Python:
!wget https://github.com/ultralytics/ultralytics/raw/main/ultralytics/cfg/datasets/coco8.yaml
To evaluate the performance of our YOLO11 model, we start by downloading the dataset configuration file, coco8.yaml. We use the wget command to fetch it from the Ultralytics repository. This file contains the necessary information about the dataset (e.g., class labels, file paths, and splits), which are essential for validating the model.
# Load a model
model = YOLO("yolo11n.pt")
# Validate the model
metrics = model.val(data="/content/coco8.yaml")
Once we have the configuration file, we load the YOLO11 model by initializing it with YOLO("yolo11n.pt"). This step sets up the model for inference and validation tasks. Next, we use the model.val() function to validate the model’s performance on the dataset defined in the coco8.yaml file. The validation process evaluates the model’s ability to detect objects accurately, and the resulting metrics help us understand its performance.
metrics.box.map # map50-95 metrics.box.map50 # map50 metrics.box.map75 # map75 metrics.box.maps # a list contains map50-95 of each category
After validation, we can explore the metrics object to gain deeper insights. For example, metrics.box.map gives us the mean average precision (mAP) across all IoU thresholds (50-95%), while metrics.box.map50 focuses specifically on IoU at 50%. Similarly, metrics.box.map75 evaluates mAP at 75% IoU. For a more detailed breakdown, see metrics.box.maps for a list of mAP scores of each category in the dataset.
Using CLI
If you prefer using the command-line interface, YOLO11 makes it equally straightforward:
!yolo detect val model=yolo11n.pt data=coco8.yaml
This command validates the model against the specified dataset (coco8.yaml) and computes all key performance metrics. The CLI is ideal for quick evaluations or when integrating into automated workflows.
How to Export with YOLO11
Exporting a trained model is a crucial step in deploying it for practical use. YOLO11 makes this process seamless by offering an Export mode that supports a variety of formats for deployment on different platforms and devices. Whether you’re aiming to use your model on edge devices, mobile applications, or high-performance servers, the YOLO11 Export mode ensures flexibility and compatibility for a wide range of environments.
When exporting, we can choose from formats like ONNX, TensorRT, Core ML, and more. These formats are optimized for specific hardware or software, enabling faster inference speeds and broader usability. Additionally, YOLO11 simplifies the exporting process with both a Python API and a command-line interface (CLI).
Exporting our trained YOLO11 model provides several advantages:
- We can deploy our model in multiple formats, making it compatible with a range of platforms (e.g., mobile apps, edge devices, or cloud services).
- Formats like TensorRT can provide up to 5x GPU speed improvements, while ONNX or OpenVINO offer 3x speedups on CPUs.
- With a straightforward export process using Python or CLI, we can save time and effort during deployment.
Using Python
Here’s how to export the YOLO11 model using the Python API:
# Load a model
model = YOLO("yolo11n.pt")
# Export the model
model.export(format="onnx")
In this example, we first load the YOLO11 model and then use the export function to convert it to the ONNX format. This format is widely supported and optimized for faster inference on various platforms.
Using CLI
Alternatively, we can use the CLI for a quick export process:
!yolo export model=yolo11n.pt format=tflite
In this command, the model is exported in TensorFlow Lite (TFLite) format, which is particularly useful for deploying on mobile and embedded systems.
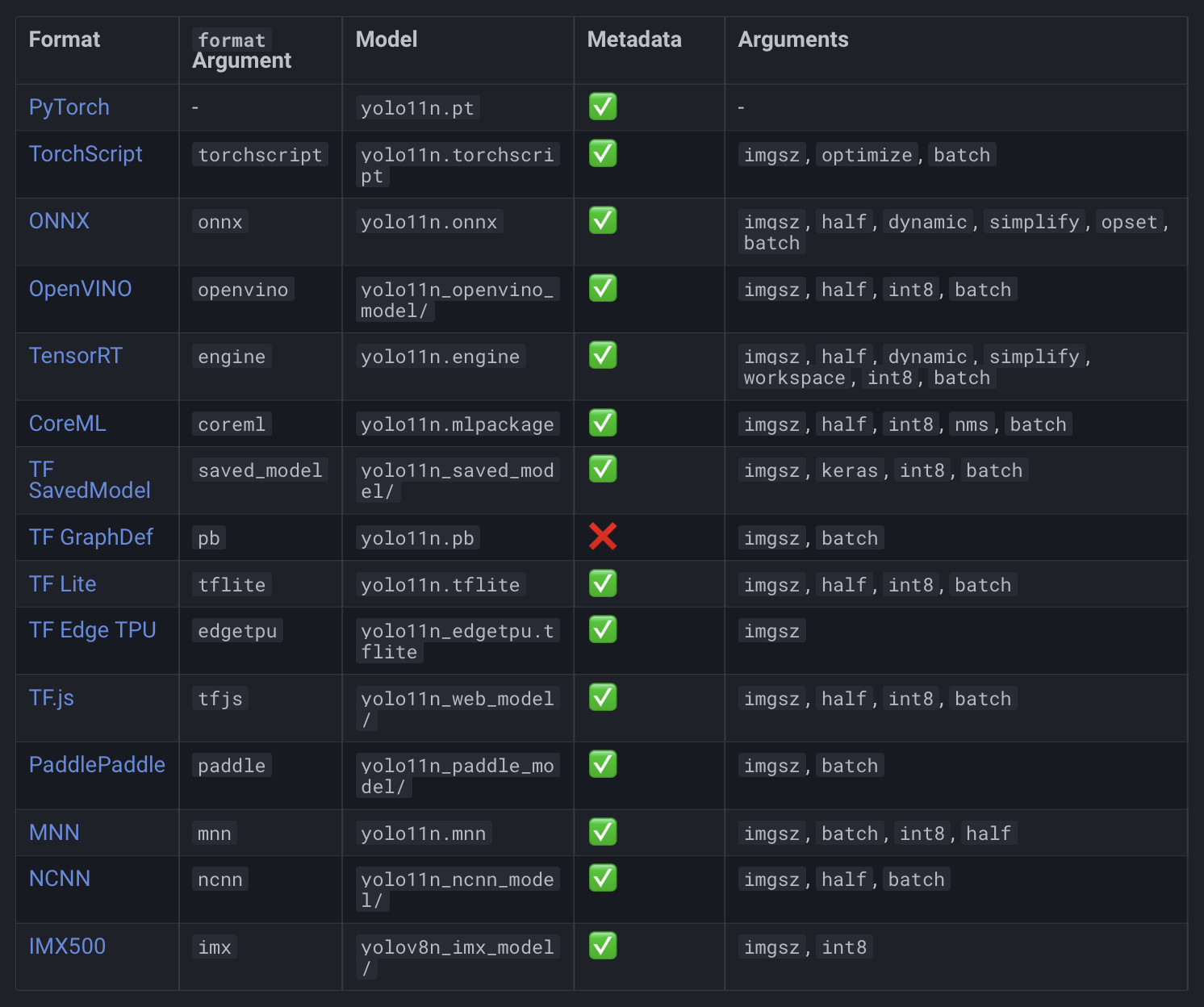
In Figure 14, we can see all the available YOLO11 export formats.
What’s next? We recommend PyImageSearch University.
86 total classes • 115+ hours of on-demand code walkthrough videos • Last updated: October 2024
★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you’re serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you’ll find:
- ✓ 86 courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 86 Certificates of Completion
- ✓ 115+ hours of on-demand video
- ✓ Brand new courses released regularly, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 540+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
YOLO11 is a versatile deep learning framework for computer vision tasks, including object detection, instance segmentation, pose estimation, and tracking. It offers streamlined workflows for inference, training, validation, and exporting, making it suitable for both beginners and experts.
Key Highlights
- Multi-Task Support: Perform object detection, instance segmentation, image classification, pose estimation, oriented object detection, and multi-object tracking.
- Multi-Mode Support: Enables seamless inference, training, validation, and model export for diverse workflows.
- Ease of Use: Simple Python and CLI interfaces for quick integration.
- Customization: Supports custom datasets, hyperparameters, and flexible configurations.
- Deployment Ready: Export trained models in formats like ONNX and TensorRT for cross-platform compatibility.
YOLO11 simplifies complex workflows while ensuring high performance, making it a go-to tool for real-time computer vision applications.
Citation Information
Thakur, P. “Getting Started with YOLO11,” PyImageSearch, P. Chugh, S. Huot, and G. Kudriavtsev, eds., 2025, https://pyimg.co/jbrnw
@incollection{Thakur_2025_getting-started-with-yolo11,
author = {Piyush Thakur},
title = {{Getting Started with YOLO11}},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Susan Huot and Georgii Kudriavtsev},
year = {2025},
url = {https://pyimg.co/jbrnw},
}
To download the source code to this post (and be notified when future tutorials are published here on PyImageSearch), simply enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you’ll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!
The post Getting Started with YOLO11 appeared first on PyImageSearch.
“}]] [[{“value”:”Table of Contents Getting Started with YOLO11 What Is YOLO11? Key Features of YOLO11 Supported Tasks Supported Modes Available Checkpoints Configuring Your Development Environment Setup and Imports How to Run Inference with YOLO11 Object Detection Instance Segmentation Image Classification Pose…
The post Getting Started with YOLO11 appeared first on PyImageSearch.”}]] Read More Classify, Computer Vision, Detect, Export, Pose, Segment, Track, Train, Tutorial, Validate, YOLO11, ai models, computer vision, deep learning, image classification, instance segmentation, model export, model training, model validation, multi-object tracking, object detection, oriented object detection, pose estimation, real-time ai, tutorial, yolo11