
[[{“value”:”

The rapid advancement and widespread adoption of generative AI systems across various domains have increased the critical importance of AI red teaming for evaluating technology safety and security. While AI red teaming aims to evaluate end-to-end systems by simulating real-world attacks, current methodologies face significant challenges in effectiveness and implementation. The complexity of modern AI systems, with their expanding capabilities across multiple modalities including vision and audio, has created an unprecedented array of potential vulnerabilities and attack vectors. Moreover, integrating agentic systems that grant AI models higher privileges and access to external tools has substantially increased the attack surface and potential impact of security breaches.
Current approaches to AI security have revealed significant limitations in addressing both traditional and emerging vulnerabilities. Traditional security assessment methods mainly focus on model-level risks while overlooking critical system-level vulnerabilities that often prove more exploitable. Moreover, AI systems utilizing retrieval augmented generation (RAG) architectures have shown susceptibility to cross-prompt injection attacks, where malicious instructions hidden in documents can manipulate model behavior and facilitate data exfiltration. While some defensive techniques like input sanitization and instruction hierarchies offer partial solutions, they cannot eliminate security risks due to the fundamental limitations of language models.
Researchers from Microsoft have proposed a comprehensive framework for AI red teaming based on their extensive experience testing over 100 generative AI products. Their approach introduces a structured threat model ontology designed to systematically identify and evaluate traditional and emerging security risks in AI systems. The framework encompasses eight key lessons from real-world operations, ranging from fundamental system understanding to integrating automation in security testing. This methodology addresses the growing complexity of AI security by combining systematic threat modeling with practical insights derived from actual red teaming operations. The approach emphasizes the importance of considering both system-level and model-level vulnerabilities.
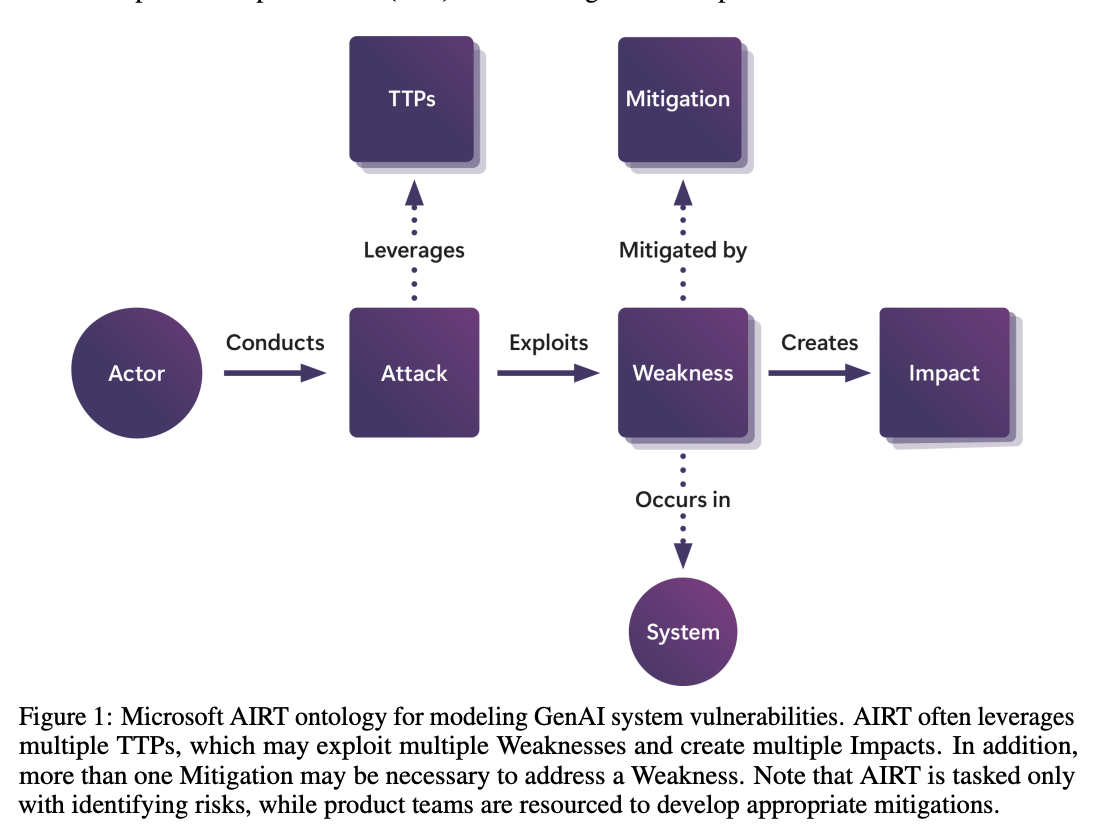
The operational architecture of Microsoft’s AI red teaming framework uses a dual-focus approach targeting both standalone AI models and integrated systems. The framework distinguishes between cloud-hosted models and complex systems that incorporate these models into various applications like copilots and plugins. Their methodology has evolved significantly since 2021 expanding from security-focused assessments to include comprehensive responsible AI (RAI) impact evaluations. The testing protocol maintains a rigorous coverage, of traditional security concerns, including data exfiltration, credential leaking, and remote code execution, while simultaneously addressing AI-specific vulnerabilities.
The effectiveness of Microsoft’s red teaming framework has been shown through a comparative analysis of attack methodologies. Their findings challenge conventional assumptions about the necessity of complex techniques, revealing that simpler approaches often match or exceed the effectiveness of complex gradient-based methods. The research highlights the superiority of system-level attack approaches over model-specific tactics. This conclusion is supported by real-world evidence showing that attackers typically exploit combinations of simple vulnerabilities across system components rather than focusing on complex model-level attacks. These results emphasize the importance of adopting a holistic security perspective, that considers both AI-specific and traditional system vulnerabilities.
In conclusion, researchers from Microsoft have proposed a comprehensive framework for AI red teaming. The framework developed through testing over 100 GenAI products provides valuable insights into effective risk evaluation methodologies. The combination of a structured threat model ontology with practical lessons learned offers a robust foundation for organizations developing their own AI security assessment protocols. These insights and methodologies provide essential guidance for addressing real-world vulnerabilities. The framework’s emphasis on practical, implementable solutions positions it as a valuable resource for organizations, research institutions, and governments working to establish effective AI risk assessment protocols.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 65k+ ML SubReddit.
 Recommend Open-Source Platform: Parlant is a framework that transforms how AI agents make decisions in customer-facing scenarios. (Promoted)
Recommend Open-Source Platform: Parlant is a framework that transforms how AI agents make decisions in customer-facing scenarios. (Promoted)
The post Microsoft Presents a Comprehensive Framework for Securing Generative AI Systems Using Lessons from Red Teaming 100 Generative AI Products appeared first on MarkTechPost.
“}]] [[{“value”:”The rapid advancement and widespread adoption of generative AI systems across various domains have increased the critical importance of AI red teaming for evaluating technology safety and security. While AI red teaming aims to evaluate end-to-end systems by simulating real-world attacks, current methodologies face significant challenges in effectiveness and implementation. The complexity of modern AI
The post Microsoft Presents a Comprehensive Framework for Securing Generative AI Systems Using Lessons from Red Teaming 100 Generative AI Products appeared first on MarkTechPost.”}]] Read More AI Paper Summary, AI Shorts, Applications, Artificial Intelligence, Editors Pick, Staff, Tech News, Technology