
[[{“value”:”
TwinMind, a California-based Voice AI startup, unveiled Ear-3 speech-recognition model, claiming state-of-the-art performance on several key metrics and expanded multilingual support. The release positions Ear-3 as a competitive offering against existing ASR (Automatic Speech Recognition) solutions from providers like Deepgram, AssemblyAI, Eleven Labs, Otter, Speechmatics, and OpenAI.
Key Metrics
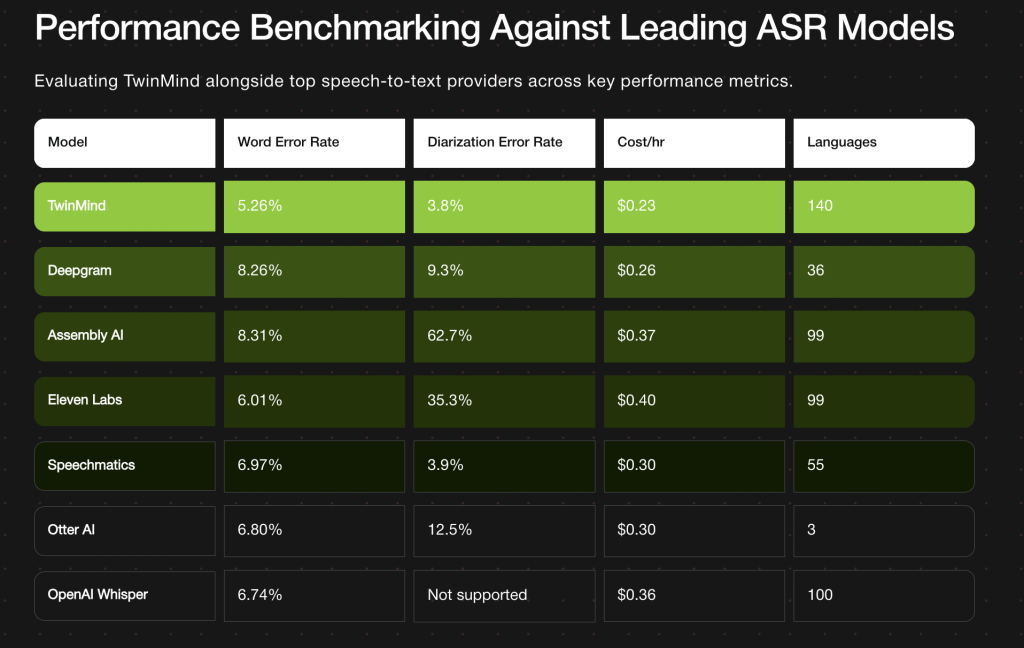
| Metric | TwinMind Ear-3 Result | Comparisons / Notes |
|---|---|---|
| Word Error Rate (WER) | 5.26 % | Significantly lower than many competitors: Deepgram ~8.26 %, AssemblyAI ~8.31 %. |
| Speaker Diarization Error Rate (DER) | 3.8 % | Slight improvement over previous best from Speechmatics (~3.9 %). |
| Language Support | 140+ languages | Over 40 more languages than many leading models; aims for “true global coverage.” |
| Cost per Hour of Transcription | US$ 0.23/hr | Positioned as lowest among major services. |
Technical Approach & Positioning
- TwinMind indicates Ear-3 is a “fine-tuned blend of several open-source models,” trained on a curated dataset containing human-annotated audio sources such as podcasts, videos, and films.
- Diarization and speaker labeling are improved via a pipeline that includes audio cleaning and enhancement before diarization, plus “precise alignment checks” to refine speaker boundary detections.
- The model handles code-switching and mixed scripts, which are typically difficult for ASR systems due to varied phonetics, accent variance, and linguistic overlap.
Trade-offs & Operational Details
- Ear-3 requires cloud deployment. Because of its model size and compute load, it cannot be fully offline. TwinMind’s Ear-2 (its earlier model) remains the fallback when connectivity is lost.
- Privacy: TwinMind claims audio is not stored long-term; only transcripts are stored locally, with optional encrypted backups. Audio recordings are deleted “on the fly.”
- Platform integration: API access for the model is planned in the coming weeks for developers/enterprises. For end users, Ear-3 functionality will be rolled out to TwinMind’s iPhone, Android, and Chrome apps over the next month for Pro users.

Comparative Analysis & Implications
Ear-3’s WER and DER metrics put it ahead of many established models. Lower WER translates to fewer transcription errors (mis-recognitions, dropped words, etc.), which is critical for domains like legal, medical, lecture transcription, or archival of sensitive content. Similarly, lower DER (i.e. better speaker separation + labeling) matters for meetings, interviews, podcasts — anything with multiple participants.
The price point of US$0.23/hr makes high-accuracy transcription more economically feasible for long-form audio (e.g. hours of meetings, lectures, recordings). Combined with support for over 140 languages, there is a clear push to make this usable in global settings, not just English-centric or well-resourced language contexts.
However, cloud dependency could be a limitation for users needing offline or edge-device capabilities, or where data privacy / latency concerns are stringent. Implementation complexity for supporting 140+ languages (accent drift, dialects, code-switching) may reveal weaker zones under adverse acoustic conditions. Real-world performance may vary compared to controlled benchmarking.
Conclusion
TwinMind’s Ear-3 model represents a strong technical claim: high accuracy, speaker diarization precision, extensive language coverage, and aggressive cost reduction. If benchmarks hold in real usage, this could shift expectations for what “premium” transcription services should deliver.
Check out the Project Page. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
The post TwinMind Introduces Ear-3 Model: A New Voice AI Model that Sets New Industry Records in Accuracy, Speaker Labeling, Languages and Price appeared first on MarkTechPost.
“}]] [[{“value”:”TwinMind, a California-based Voice AI startup, unveiled Ear-3 speech-recognition model, claiming state-of-the-art performance on several key metrics and expanded multilingual support. The release positions Ear-3 as a competitive offering against existing ASR (Automatic Speech Recognition) solutions from providers like Deepgram, AssemblyAI, Eleven Labs, Otter, Speechmatics, and OpenAI. Key Metrics Metric TwinMind Ear-3 Result Comparisons /
The post TwinMind Introduces Ear-3 Model: A New Voice AI Model that Sets New Industry Records in Accuracy, Speaker Labeling, Languages and Price appeared first on MarkTechPost.”}]]  Read More Artificial Intelligence, Audio Language Model, Editors Pick, Enterprise AI, Language Model, New Releases, Staff, Technology, Voice AI
Read More Artificial Intelligence, Audio Language Model, Editors Pick, Enterprise AI, Language Model, New Releases, Staff, Technology, Voice AI