[[{“value”:”
Table of contents
- Hardware Generation without Templates
- Input IR: Affine, Relation-Centric Semantics (Deconstruct)
- Front End: FU Graph + Memory Co-Design (Architect)
- Back End: Compile & Optimize to RTL (Compile & Optimize)
- Outcome
- Importance for each segment
- How the “Compiler for AI Chips” Works—Step-by-Step ?
- Where It Lands in the Ecosystem?
- Summary
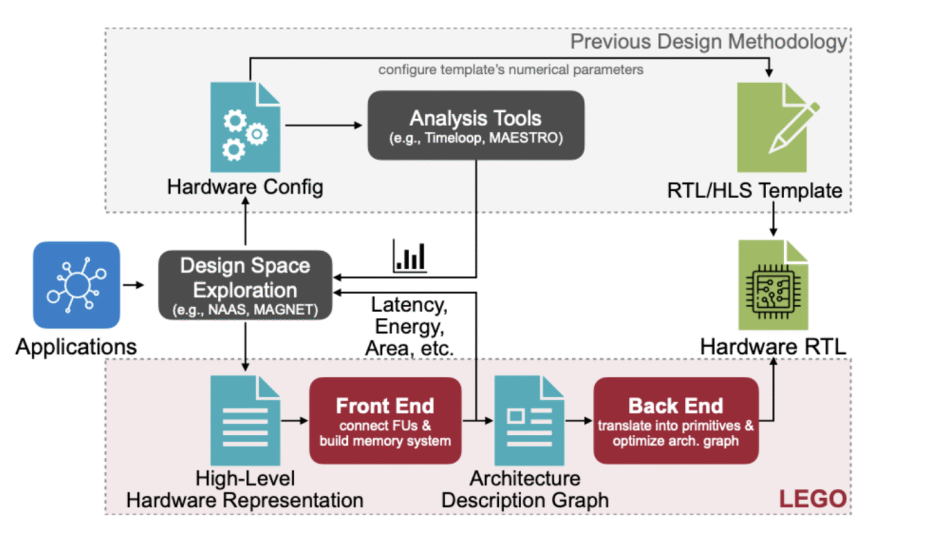
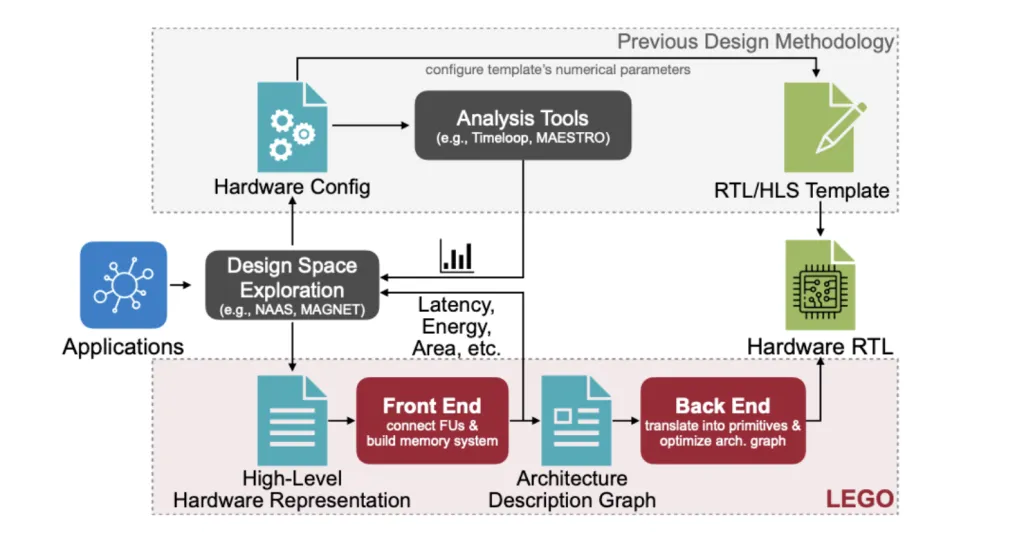
MIT researchers (Han Lab) introduced LEGO, a compiler-like framework that takes tensor workloads (e.g., GEMM, Conv2D, attention, MTTKRP) and automatically generates synthesizable RTL for spatial accelerators—no handwritten templates. LEGO’s front end expresses workloads and dataflows in a relation-centric affine representation, builds FU (functional unit) interconnects and on-chip memory layouts for reuse, and supports fusing multiple spatial dataflows in a single design. The back end lowers to a primitive-level graph and uses linear programming and graph transforms to insert pipeline registers, rewire broadcasts, extract reduction trees, and shrink area and power. Evaluated across foundation models and classic CNNs/Transformers, LEGO’s generated hardware shows 3.2× speedup and 2.4× energy efficiency over Gemmini under matched resources.
Hardware Generation without Templates
Existing flows either: (1) analyze dataflows without generating hardware, or (2) generate RTL from hand-tuned templates with fixed topologies. These approaches restrict the architecture space and struggle with modern workloads that need to switch dataflows dynamically across layers/ops (e.g., conv vs. depthwise vs. attention). LEGO directly targets any dataflow and combinations, generating both architecture and RTL from a high-level description rather than configuring a few numeric parameters in a template.
Input IR: Affine, Relation-Centric Semantics (Deconstruct)
LEGO models tensor programs as loop nests with three index classes: temporal (for-loops), spatial (par-for FUs), and computation (pre-tiling iteration domain). Two affine relations drive the compiler:
- Data mapping fI→Df_{I→D}: maps computation indices to tensor indices.
- Dataflow mapping fTS→If_{TS→I}: maps temporal/spatial indices to computation indices.
This affine-only representation eliminates modulo/division in the core analysis, making reuse detection and address generation a linear-algebra problem. LEGO also decouples control flow from dataflow (a vector c encodes control signal propagation/delay), enabling shared control across FUs and substantially reducing control logic overhead.
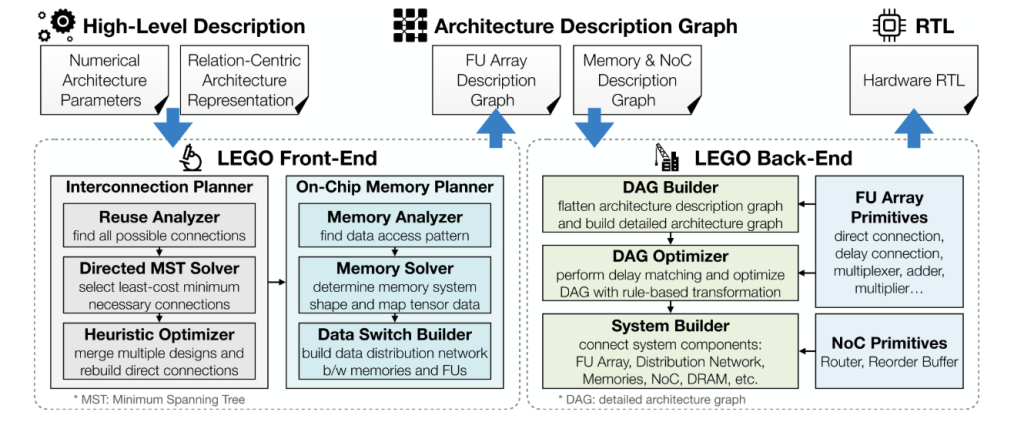
Front End: FU Graph + Memory Co-Design (Architect)
The main objectives is to maximize reuse and on-chip bandwidth while minimizing interconnect/mux overhead.
- Interconnection synthesis. LEGO formulates reuse as solving linear systems over the affine relations to discover direct and delay (FIFO) connections between FUs. It then computes minimum-spanning arborescences (Chu-Liu/Edmonds) to keep only necessary edges (cost = FIFO depth). A BFS-based heuristic rewrites direct interconnects when multiple dataflows must co-exist, prioritizing chain reuse and nodes already fed by delay connections to cut muxes and data nodes.
- Banked memory synthesis. Given the set of FUs that must read/write a tensor in the same cycle, LEGO computes bank counts per tensor dimension from the maximum index deltas (optionally dividing by GCD to reduce banks). It then instantiates data-distribution switches to route between banks and FUs, leaving FU-to-FU reuse to the interconnect.
- Dataflow fusion. Interconnects for different spatial dataflows are combined into a single FU-level Architecture Description Graph (ADG); careful planning avoids naïve mux-heavy merges and yields up to ~20% energy gains compared to naïve fusion.
Back End: Compile & Optimize to RTL (Compile & Optimize)
The ADG is lowered to a Detailed Architecture Graph (DAG) of primitives (FIFOs, muxes, adders, address generators). LEGO applies several LP/graph passes:
- Delay matching via LP. A linear program chooses output delays DvD_v to minimize inserted pipeline registers ∑(Dv−Du−Lv)⋅bitwidthsum (D_v-D_u-L_v)cdot text{bitwidth} across edges—meeting timing alignment with minimal storage.
- Broadcast pin rewiring. A two-stage optimization (virtual cost shaping + MST-based rewiring among destinations) converts expensive broadcasts into forward chains, enabling register sharing and lower latency; a final LP re-balances delays.
- Reduction tree extraction + pin reuse. Sequential adder chains become balanced trees; a 0-1 ILP remaps reducer inputs across dataflows so fewer physical pins are required (mux instead of add). This reduces both logic depth and register count.
These passes focus on the datapath, which dominates resources (e.g., FU-array registers ≈ 40% area, 60% power), and produce ~35% area savings versus naïve generation.
Outcome
Setup. LEGO is implemented in C++ with HiGHS as the LP solver and emits SpinalHDL→Verilog. Evaluation covers tensor kernels and end-to-end models (AlexNet, MobileNetV2, ResNet-50, EfficientNetV2, BERT, GPT-2, CoAtNet, DDPM, Stable Diffusion, LLaMA-7B). A single LEGO-MNICOC accelerator instance is used across models; a mapper picks per-layer tiling/dataflow. Gemmini is the main baseline under matched resources (256 MACs, 256 KB on-chip buffer, 128-bit bus @ 16 GB/s).
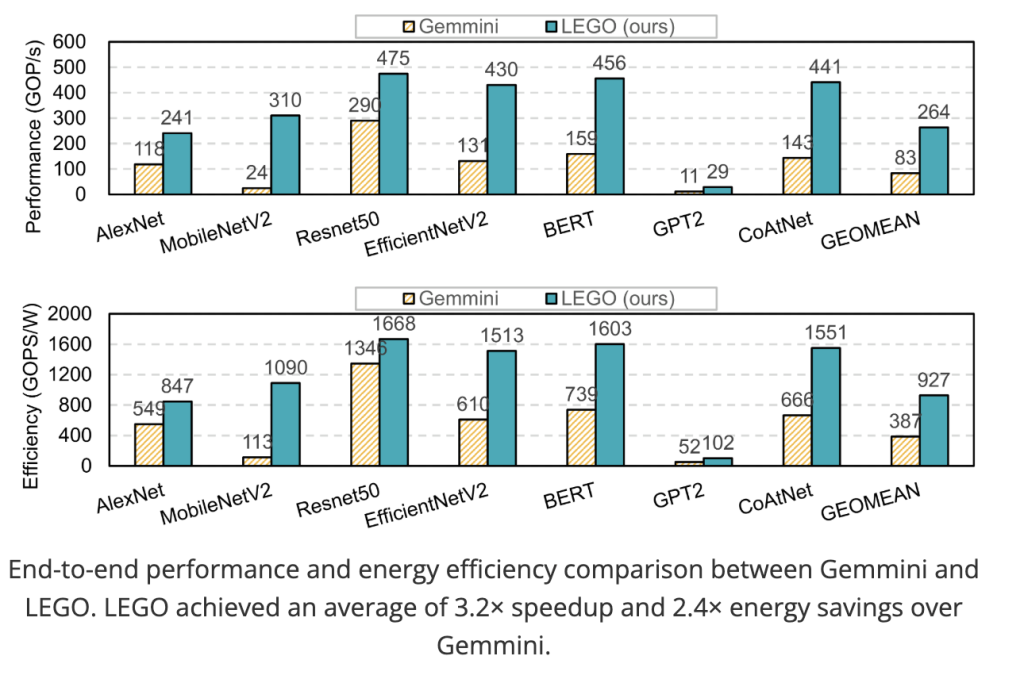
End-to-end speed/efficiency. LEGO achieves 3.2× speedup and 2.4× energy efficiency on average vs. Gemmini. Gains stem from: (i) a fast, accurate performance model guiding mapping; (ii) dynamic spatial dataflow switching enabled by generated interconnects (e.g., depthwise conv layers choose OH–OW–IC–OC). Both designs are bandwidth-bound on GPT-2.
Resource breakdown. Example SoC-style configuration shows FU array and NoC dominate area/power, with PPUs contributing ~2–5%. This supports the decision to aggressively optimize datapaths and control reuse.
Generative models. On a larger 1024-FU configuration, LEGO sustains >80% utilization for DDPM/Stable Diffusion; LLaMA-7B remains bandwidth-limited (expected for low operational intensity).
Importance for each segment
- For researchers: LEGO provides a mathematically grounded path from loop-nest specifications to spatial hardware with provable LP-based optimizations. It abstracts away low-level RTL and exposes meaningful levers (tiling, spatialization, reuse patterns) for systematic exploration.
- For practitioners: It is effectively hardware-as-code. You can target arbitrary dataflows and fuse them in one accelerator, letting a compiler derive interconnects, buffers, and controllers while shrinking mux/FIFO overheads. This improves energy and supports multi-op pipelines without manual template redesign.
- For product leaders: By lowering the barrier to custom silicon, LEGO enables task-tuned, power-efficient edge accelerators (wearables, IoT) that keep pace with fast-moving AI stacks—the silicon adapts to the model, not the other way around. End-to-end results against a state-of-the-art generator (Gemmini) quantify the upside.
How the “Compiler for AI Chips” Works—Step-by-Step?
- Deconstruct (Affine IR). Write the tensor op as loop nests; supply affine f_{I→D} (data mapping), f_{TS→I} (dataflow), and control flow vector c. This specifies what to compute and how it is spatialized, without templates.
- Architect (Graph Synthesis). Solve reuse equations → FU interconnects (direct/delay) → MST/heuristics for minimal edges and fused dataflows; compute banked memory and distribution switches to satisfy concurrent accesses without conflicts.
- Compile & Optimize (LP + Graph Transforms). Lower to a primitive DAG; run delay-matching LP, broadcast rewiring (MST), reduction-tree extraction, and pin-reuse ILP; perform bit-width inference and optional power gating. These passes jointly deliver ~35% area and ~28% energy savings vs. naïve codegen.
Where It Lands in the Ecosystem?
Compared with analysis tools (Timeloop/MAESTRO) and template-bound generators (Gemmini, DNA, MAGNET), LEGO is template-free, supports any dataflow and their combinations, and emits synthesizable RTL. Results show comparable or better area/power versus expert handwritten accelerators under similar dataflows and technologies, while offering one-architecture-for-many-models deployment.
Summary
LEGO operationalizes hardware generation as compilation for tensor programs: an affine front end for reuse-aware interconnect/memory synthesis and an LP-powered back end for datapath minimization. The framework’s measured 3.2× performance and 2.4× energy gains over a leading open generator, plus ~35% area reductions from back-end optimizations, position it as a practical path to application-specific AI accelerators at the edge and beyond.
Check out the Paper and Project Page. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
The post MIT’s LEGO: A Compiler for AI Chips that Auto-Generates Fast, Efficient Spatial Accelerators appeared first on MarkTechPost.
“}]] [[{“value”:”MIT researchers (Han Lab) introduced LEGO, a compiler-like framework that takes tensor workloads (e.g., GEMM, Conv2D, attention, MTTKRP) and automatically generates synthesizable RTL for spatial accelerators—no handwritten templates. LEGO’s front end expresses workloads and dataflows in a relation-centric affine representation, builds FU (functional unit) interconnects and on-chip memory layouts for reuse, and supports fusing multiple
The post MIT’s LEGO: A Compiler for AI Chips that Auto-Generates Fast, Efficient Spatial Accelerators appeared first on MarkTechPost.”}]] Read More AI Infrastructure, Artificial Intelligence, Editors Pick, Hardware, Staff, Technology