[[{“value”:”
Table of contents
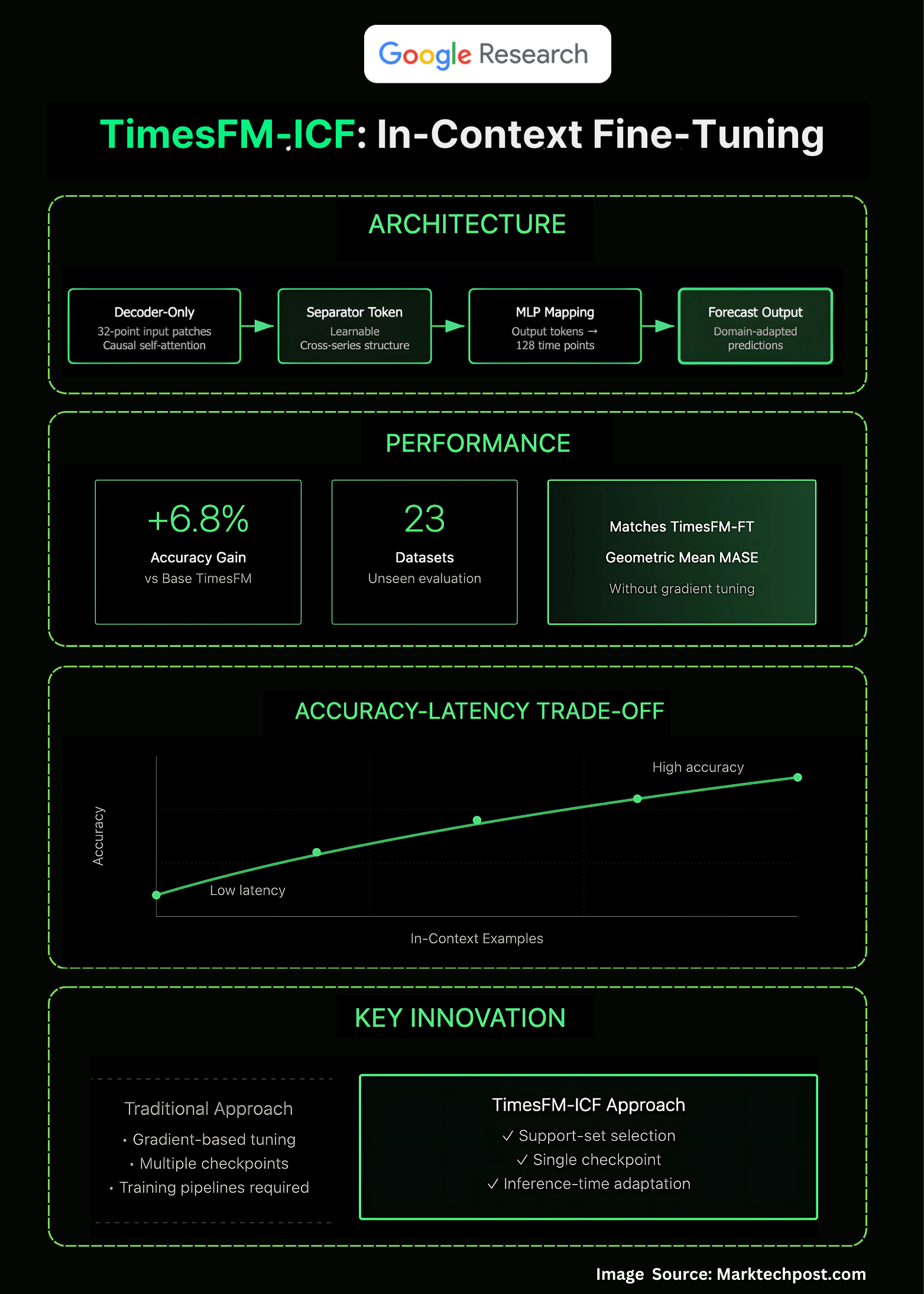
Google Research introduces in-context fine-tuning (ICF) for time-series forecasting named as ‘TimesFM-ICF): a continued-pretraining recipe that teaches TimesFM to exploit multiple related series provided directly in the prompt at inference time. The result is a few-shot forecaster that matches supervised fine-tuning while delivering +6.8% accuracy over the base TimesFM across an OOD benchmark—no per-dataset training loop required.
What pain point in forecasting is being eliminated?
Most production workflows still trade off between (a) one model per dataset via supervised fine-tuning (accuracy, but heavy MLOps) and (b) zero-shot foundation models (simple, but not domain-adapted). Google’s new approach keeps a single pre-trained TimesFM checkpoint but lets it adapt on the fly using a handful of in-context examples from related series during inference, avoiding per-tenant training pipelines.
How does in-context fine-tuning work under the hood?
Start with TimesFM—a patched, decoder-only transformer that tokenizes 32-point input patches and de-tokenizes 128-point outputs via a shared MLP—and continue pre-training it on sequences that interleave the target history with multiple “support” series. Now the key change introduced is a learnable common separator token, so cross-example causal attention can mine structure across examples without conflating trends. The training objective remains next-token prediction; what’s new is the context construction that teaches the model to reason across multiple related series at inference time.
What exactly is “few-shot” here?
At inference, the user concatenates the target history with kk additional time-series snippets (e.g., similar SKUs, adjacent sensors), each delimited by the separator token. The model’s attention layers are now explicitly trained to leverage those in-context examples, analogous to LLM few-shot prompting—but for numeric sequences rather than text tokens. This shifts adaptation from parameter updates to prompt engineering over structured series.
Does it actually match supervised fine-tuning?
On a 23-dataset out-of-domain suite, TimesFM-ICF equals the performance of per-dataset TimesFM-FT while being 6.8% more accurate than TimesFM-Base (geometric mean of scaled MASE). The blog also shows the expected accuracy–latency trade-off: more in-context examples yield better forecasts at the cost of longer inference. A “just make the context longer” ablation indicates that structured in-context examples beat naive long-context alone.
How is this different from Chronos-style approaches?
Chronos tokenizes values into a discrete vocabulary and demonstrated strong zero-shot accuracy and fast variants (e.g., Chronos-Bolt). Google’s contribution here is not another tokenizer or headroom on zero-shot; it’s making a time-series FM behave like an LLM few-shot learner—learning from cross-series context at inference. That capability closes the gap between “train-time adaptation” and “prompt-time adaptation” for numeric forecasting.
What are the architectural specifics to watch?
The research team highlights: (1) separator tokens to mark boundaries, (2) causal self-attention over mixed histories and examples, (3) persisted patching and shared MLP heads, and (4) continued pre-training to instill cross-example behavior. Collectively, these enable the model to treat support series as informative exemplars rather than background noise.
Summary
Google’s in-context fine-tuning turns TimesFM into a practical few-shot forecaster: a single pretrained checkpoint that adapts at inference via curated support series, delivering fine-tuning-level accuracy without per-dataset training overhead—useful for multi-tenant, latency-bounded deployments where selection of support sets becomes the main control surface
FAQs
1) What is Google’s “in-context fine-tuning” (ICF) for time series?
ICF is continued pre-training that conditions TimesFM to use multiple related series placed in the prompt at inference, enabling few-shot adaptation without per-dataset gradient updates.
2) How does ICF differ from standard fine-tuning and zero-shot use?
Standard fine-tuning updates weights per dataset; zero-shot uses a fixed model with only the target history. ICF keeps weights fixed at deployment but learns during pre-training how to leverage extra in-context examples, matching per-dataset fine-tuning on reported benchmarks.
3) What architectural or training changes were introduced?
TimesFM is continued-pretrained with sequences that interleave target history and support series, separated by special boundary tokens so causal attention can exploit cross-series structure; the rest of the decoder-only TimesFM stack stays intact.
4) What do the results show relative to baselines?
On out-of-domain suites, ICF improves over TimesFM base and reaches parity with supervised fine-tuning; it is evaluated against strong TS baselines (e.g., PatchTST) and prior FMs (e.g., Chronos).
Check out the Paper and Technical details. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
For content partnership/promotions on marktechpost.com, please TALK to us
The post Google AI Research Introduce a Novel Machine Learning Approach that Transforms TimesFM into a Few-Shot Learner appeared first on MarkTechPost.
“}]] [[{“value”:”Google Research introduces in-context fine-tuning (ICF) for time-series forecasting named as ‘TimesFM-ICF): a continued-pretraining recipe that teaches TimesFM to exploit multiple related series provided directly in the prompt at inference time. The result is a few-shot forecaster that matches supervised fine-tuning while delivering +6.8% accuracy over the base TimesFM across an OOD benchmark—no per-dataset training
The post Google AI Research Introduce a Novel Machine Learning Approach that Transforms TimesFM into a Few-Shot Learner appeared first on MarkTechPost.”}]] ![]() Read More AI Paper Summary, AI Shorts, Applications, Artificial Intelligence, Data Science, Editors Pick, Machine Learning, Staff, Tech News, Technology
Read More AI Paper Summary, AI Shorts, Applications, Artificial Intelligence, Data Science, Editors Pick, Machine Learning, Staff, Tech News, Technology