[[{“value”:”

Transformer-based architectures have revolutionized natural language processing, delivering exceptional performance across diverse language modeling tasks. However, they still face major challenges when handling long-context sequences. The self-attention mechanism in Transformers suffers from quadratic computational complexity, and their memory requirement grows linearly with context length during inference. These factors impose practical constraints on sequence length due to the high computational and memory costs. Recent advancements in recurrent-based architectures, especially State Space Models (SSMs), have shown promise as efficient alternatives for language modeling.
Existing approaches like State Space Models (SSMs) have shown the capability to address the challenges of Transformer-based architectures. The development of SSMs has progressed through several key iterations, such as S4, DSS, S4D, and S5, which have improved computational and memory efficiency. Recent variants like Mamba have used input-dependent state transitions to address the limitations of static dynamics in previous SSMs. Despite these advancements, SSM-based models face limitations in scenarios that need in-context retrieval or handling complex long-range dependencies. Moreover, the Long Context Models discussed in this paper include Recurrent Memory Transformer, LongNet, and Hyena/HyenaDNA.
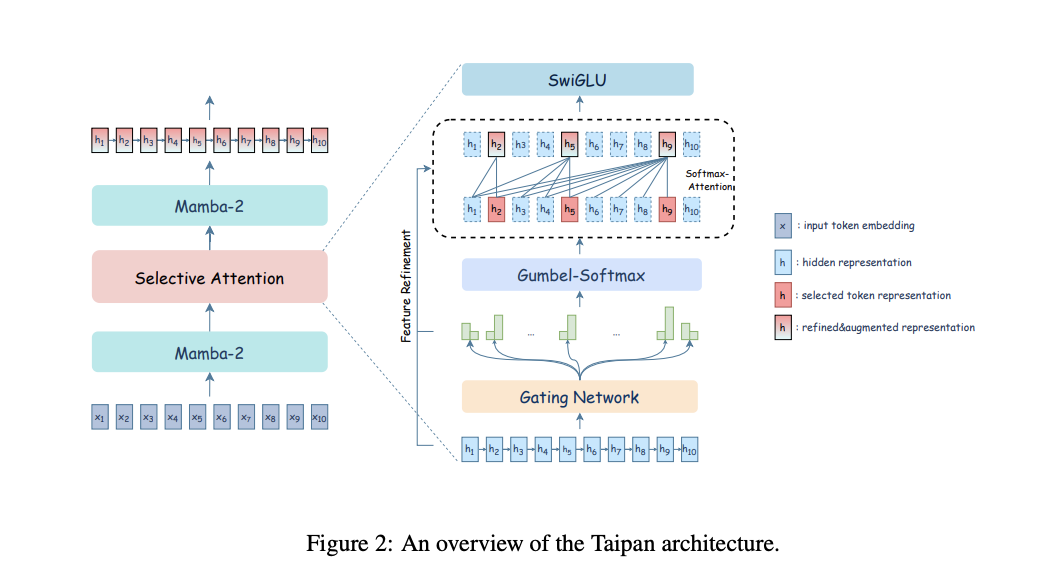
Researchers from the University of Oregon, Auburn University, and Adobe Research have proposed Taipan, a hybrid architecture that combines the efficiency of Mamba with enhanced long-range dependency handling through Selective Attention Layers (SALs). While Mamba is highly efficient, it relies on the Markov assumption, which can lead to information loss for tokens that need interactions with distant tokens. To mitigate this, Taipan utilizes SALs that strategically select key tokens in the input sequence requiring long-range dependencies. Moreover, the Taipan balances Mamba’s efficiency with Transformer-like performance in memory-intensive tasks. It extends accurate predictions to context lengths of up to 1 million tokens while preserving computational efficiency by constraining the attention budget.
Taipan leverages SALs within the Mamba framework to boost Mamba’s modeling capabilities while preserving its computational efficiency. SALs are inserted after every K Mamba-2 block, creating a hybrid structure that combines Mamba-2’s efficiency with Transformer-style attention. The core of SALs is a gating network that identifies important tokens for enhanced representation modeling. These tokens undergo feature refinement and attention-based representation augmentation, allowing Taipan to capture complex, non-Markovian dependencies. The hybrid structure balances Mamba-2’s efficiency with the expressive power of SALs, allowing Taipan to perform well in tasks that need both speed and accurate information retrieval.
Taipan consistently outperforms baseline models across most tasks for various model sizes, with the performance gap widening as the model size increases. The 1.3B Taipan model significantly improves over other baselines, suggesting its architecture effectively captures and utilizes linguistic patterns. Taipan also demonstrates superior performance in in-context retrieval tasks compared to Mamba and Jamba, while consuming fewer computational resources than Jamba. Moreover, Taipan maintains constant memory usage, offering a more efficient solution for processing long documents compared to Transformers which face challenges with linear memory scaling.
In conclusion, researchers introduced Taipan, a hybrid architecture that combines Mamba’s efficiency with improved long-range dependency handling through SALs. The experiments demonstrate Taipan’s superior performance across various scales and tasks, especially in scenarios that need extensive in-context retrieval while maintaining computational efficiency. Taipan’s architecture utilizes the insight that not all tokens require the same computational resources through its selective attention mechanism, which dynamically allocates resources based on the importance of tokens. This approach allows Taipan to balance efficiency with enhanced long-range modeling capabilities, making it a promising solution for memory-intensive tasks with long sequences.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Trending] LLMWare Introduces Model Depot: An Extensive Collection of Small Language Models (SLMs) for Intel PCs
The post Taipan: A Novel Hybrid Architecture that Combines Mamba-2 with Selective Attention Layers (SALs) appeared first on MarkTechPost.
“}]] [[{“value”:”Transformer-based architectures have revolutionized natural language processing, delivering exceptional performance across diverse language modeling tasks. However, they still face major challenges when handling long-context sequences. The self-attention mechanism in Transformers suffers from quadratic computational complexity, and their memory requirement grows linearly with context length during inference. These factors impose practical constraints on sequence length due
The post Taipan: A Novel Hybrid Architecture that Combines Mamba-2 with Selective Attention Layers (SALs) appeared first on MarkTechPost.”}]] Read More AI Paper Summary, AI Shorts, Applications, Artificial Intelligence, Editors Pick, Language Model, Staff, Tech News, Technology