[[{“value”:”

The landscape of AI research is experiencing significant challenges due to the immense computational requirements of large pre-trained language and vision models. Training even relatively modest models demand substantial resources; for instance, Pythia-1B requires 64 GPUs for three days, while RoBERTa needs 1,000 GPUs for a single day. This computational barrier affects academic laboratories, limiting their ability to conduct controlled pre-training experiments. Moreover, lacking transparency regarding pre-training costs in academia creates additional obstacles, making it difficult for researchers to plan experiments, propose realistic grant budgets, and efficiently allocate resources.
Previous attempts to address computational challenges in AI research include Compute surveys that explore resource access and environmental impacts but most focused narrowly on NLP communities. Next, training optimization techniques depend on manual tuning with specialized knowledge, while systems like Deepspeed Autotune focus on batch size and Zero-based model sharding optimizations. Some researchers have developed efficient pre-training recipes for models like BERT variants, achieving faster training times on limited GPUs. Moreover, Hardware recommendation studies have provided detailed guidance on equipment selection but highlight throughput metrics rather than practical training time considerations. These approaches still need to fully address the need for model-agnostic, replication-focused solutions that maintain original architecture integrity.
Researchers from Brown University have proposed a comprehensive approach to clarify pre-training capabilities in academic settings. Their methodology combines a survey of academic researchers’ computational resources with empirical measurements of model replication times. A novel benchmark system is developed that evaluates pre-training duration across different GPUs and identifies optimal settings for maximum training efficiency. Through extensive experimentation involving 2,000 GPU hours, there are significant improvements in resource utilization. The results highlight potential improvements for academic pre-training, showing that models like Pythia-1B can be replicated using fewer GPU days than originally required.
The proposed method utilizes a dual-category optimization strategy: free-lunch methods and memory-saving methods. Free-lunch methods represent optimizations with improvements in throughput and potential memory reduction without losing performance or requiring user intervention. These include model compilation, using off-the-shelf custom kernels as drop-in replacements for PyTorch modules, and utilizing TF32 mode for matrix operations. On the other hand, Memory-saving methods reduce memory consumption, introducing some performance trade-offs consisting of three key components: activation checkpointing, model sharding, and offloading. The system evaluates up to 22 unique combinations of memory-saving methods while maintaining free-lunch optimizations as a constant baseline.
The empirical results show significant improvements over initial analytical predictions, which are overly optimistic by a factor of 6 times. Initial testing shows that 9 out of 20 model-GPU configurations are not feasible, with Pythia-1B requiring 41 days on 4 A100 GPUs using naive implementation. However, after implementing the optimized configuration methods, the research achieved an average 4.3 times speedup in training time, reducing Pythia-1B training to just 18 days on the same hardware setup. Moreover, the study reveals a surprising benefit: memory-saving methods, earlier associated with speed reduction, sometimes improved training time by up to 71%, especially for GPUs with limited memory or larger models.
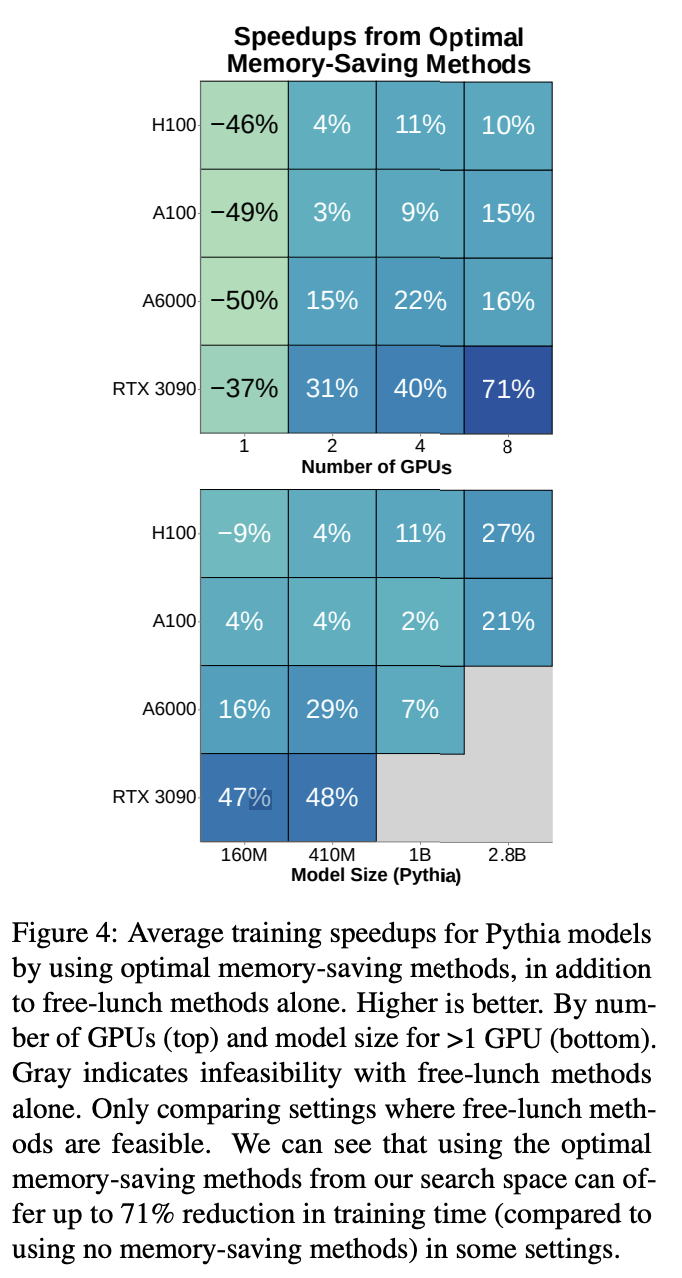
In conclusion, researchers from Brown University present a significant step toward bridging the growing computational divide between industry and academia in AI research. The study shows that academic institutions can train billion-parameter models despite resource limitations. The developed codebase and benchmark system provide practical tools for researchers to evaluate and optimize their hardware configurations before making substantial investments. It allows academic groups to find optimal training settings specific to their available resources and run preliminary tests on cloud platforms. This work marks an important milestone in empowering academic researchers to engage more actively in large-scale AI model development.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Sponsorship Opportunity with us] Promote Your Research/Product/Webinar with 1Million+ Monthly Readers and 500k+ Community Members
The post Optimizing Large-Scale AI Model Pre-Training for Academic Research: A Resource-Efficient Approach appeared first on MarkTechPost.
“}]] [[{“value”:”The landscape of AI research is experiencing significant challenges due to the immense computational requirements of large pre-trained language and vision models. Training even relatively modest models demand substantial resources; for instance, Pythia-1B requires 64 GPUs for three days, while RoBERTa needs 1,000 GPUs for a single day. This computational barrier affects academic laboratories, limiting
The post Optimizing Large-Scale AI Model Pre-Training for Academic Research: A Resource-Efficient Approach appeared first on MarkTechPost.”}]] Read More AI Paper Summary, AI Shorts, Applications, Artificial Intelligence, Editors Pick, Language Model, Staff, Tech News, Technology