[[{“value”:”

Video generation has rapidly become a focal point in artificial intelligence research, especially in generating temporally consistent, high-fidelity videos. This area involves creating video sequences that maintain visual coherence across frames and preserve details over time. Machine learning models, particularly diffusion transformers (DiTs), have emerged as powerful tools for these tasks, surpassing previous methods like GANs and VAEs in quality. However, as these models become complex, generating high-resolution videos’ computational cost and latency has become a significant challenge. Researchers are now focused on improving these models’ efficiency to enable faster, real-time video generation while maintaining quality standards.
One pressing issue in video generation is the resource-intensive nature of current high-quality models. Generating complex, visually appealing videos requires significant processing power, especially with large models that handle longer, high-resolution video sequences. These demands slow down the inference process, which makes real-time generation challenging. Many video applications need models that can process data quickly while still delivering high fidelity across frames. A key problem is finding an optimal balance between processing speed and output quality, as faster methods typically compromise the details. In contrast, high-quality methods tend to be computationally heavy and slow.
Over time, various methods have been introduced to optimize video generation models, aiming to streamline computational processes and reduce resource usage. Traditional approaches like step-distillation, latent diffusion, and caching have contributed to this goal. Step distillation, for instance, reduces the number of steps needed to achieve quality by condensing complex tasks into simpler forms. At the same time, latent diffusion techniques aim to improve the overall quality-to-latency ratio. Caching techniques store previously computed steps to avoid redundant calculations. However, these approaches have limitations, such as more flexibility to adapt to the unique characteristics of each video sequence. This often leads to inefficiencies, particularly when dealing with videos that vary greatly in complexity, motion, and texture.

Researchers from Meta AI and Stony Brook University introduced an innovative solution called Adaptive Caching (AdaCache), which accelerates video diffusion transformers without additional training. AdaCache is a training-free technique that can be integrated into various video DiT models to streamline processing times by dynamically caching computations. By adapting to the unique needs of each video, this approach allows AdaCache to allocate computational resources where they are most effective. AdaCache is built to optimize latency while preserving video quality, making it a flexible, plug-and-play solution for improving performance across different video generation models.
AdaCache operates by caching certain residual computations within the transformer architecture, allowing these calculations to be reused across multiple steps. This approach is particularly efficient because it avoids redundant processing steps, a common bottleneck in video generation tasks. The model uses a caching schedule tailored for each video to determine the best points for recomputing or reusing residual data. This schedule is based on a metric that assesses the data change rate across frames. Further, the researchers incorporated a Motion Regularization (MoReg) mechanism into AdaCache, which allocates more computational resources to high-motion scenes that require finer attention to detail. By using a lightweight distance metric and a motion-based regularization factor, AdaCache balances the trade-off between speed and quality, adjusting computational focus based on the video’s motion content.
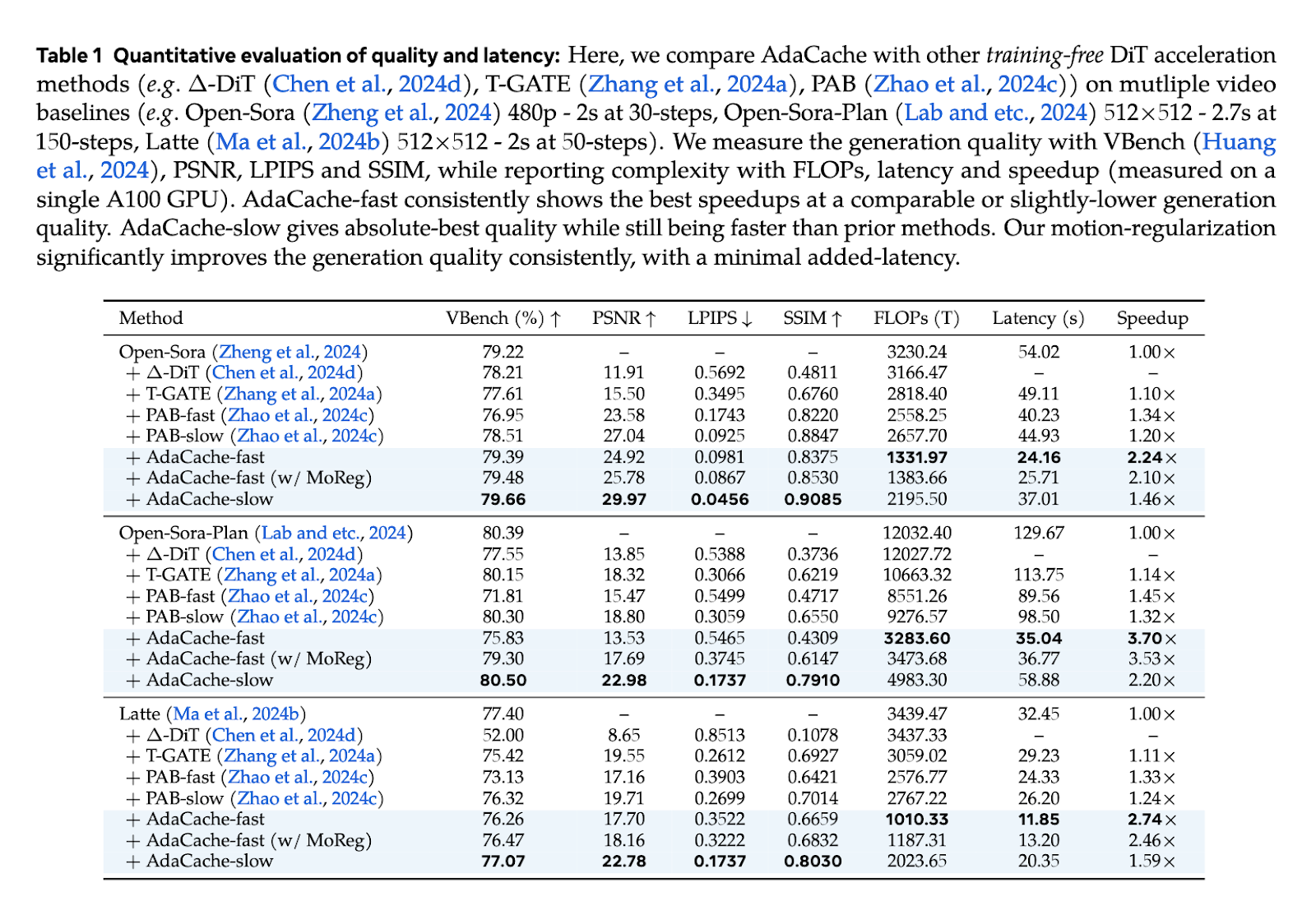
The research team conducted a series of tests to evaluate AdaCache’s performance. Results showed that AdaCache substantially improved processing speeds and quality retention across multiple video generation models. For example, in a test involving Open-Sora’s 720p 2-second video generation, AdaCache recorded a speed increase up to 4.7 times faster than previous methods while maintaining comparable video quality. Furthermore, variants of AdaCache, like the “AdaCache-fast” and the “AdaCache-slow,” offer options based on speed or quality needs. With MoReg, AdaCache demonstrated enhanced quality, aligning closely with human preferences in visual assessments, and outperformed traditional caching methods. Speed benchmarks on different DiT models also confirmed AdaCache’s superiority, with speedups ranging from 1.46x to 4.7x depending on the configuration and quality requirements.
In conclusion, AdaCache marks a significant advancement in video generation, providing a flexible solution to the longstanding issue of balancing latency and video quality. By employing adaptive caching and motion-based regularization, the researchers offer a method that is efficient and practical for a wide array of real-world applications in real-time and high-quality video production. AdaCache’s plug-and-play nature enables it to enhance existing video generation systems without requiring extensive retraining or customization, making it a promising tool for future video generation.
Check out the Paper, Code, and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Sponsorship Opportunity with us] Promote Your Research/Product/Webinar with 1Million+ Monthly Readers and 500k+ Community Members
The post Meta AI Introduces AdaCache: A Training-Free Method to Accelerate Video Diffusion Transformers (DiTs) appeared first on MarkTechPost.
“}]] [[{“value”:”Video generation has rapidly become a focal point in artificial intelligence research, especially in generating temporally consistent, high-fidelity videos. This area involves creating video sequences that maintain visual coherence across frames and preserve details over time. Machine learning models, particularly diffusion transformers (DiTs), have emerged as powerful tools for these tasks, surpassing previous methods like
The post Meta AI Introduces AdaCache: A Training-Free Method to Accelerate Video Diffusion Transformers (DiTs) appeared first on MarkTechPost.”}]] Read More AI Paper Summary, AI Shorts, Applications, Artificial Intelligence, Computer Vision, Editors Pick, Staff, Tech News, Technology