[[{“value”:”

In today’s world, building robotic policies is difficult. It often requires collecting specific data for each robot, task, and environment, and the learned policies do not generalize beyond these specific settings. Recent progress in open-source, large-scale data collection has made pre-training on large-scale, high-quality, and diverse data possible. However, in robotics, heterogeneity poses a challenge because robots differ in physical form, sensors, and operating environments. Both proprioception and vision information are important for complex, contact-rich, long-horizon behaviors in robotics. Poor learning of such information can lead to overfitting behaviors such as repeating motions for a particular scene, task, or even trajectory.
The current methods in robotic learning involve collecting data from a single robot embodiment for a specific task and training the model upon it. This is an extensive approach, and the main limitation of this is that the model cannot be generalized for various tasks and robots. Methods like pre-training and transfer learning use data from various fields, such as computer vision and natural language, to help models learn and adapt to newer tasks. Recent works show that small projection layers can be used to combine the pre-trained feature spaces of the foundation models. Different from other fields, robotics has less data quantity and diversity but much more heterogeneity. Also, recent advancements combine multimodal data (images, language, audio) for better representation learning.
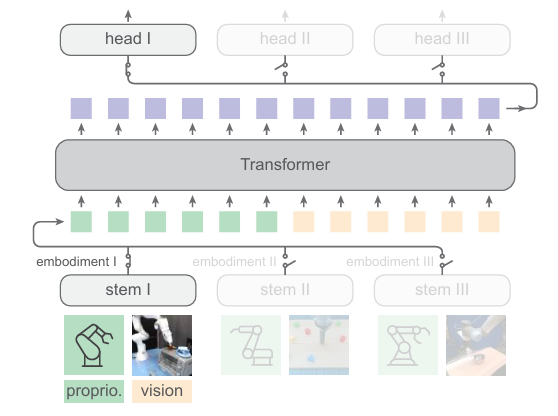
A group of researchers from MIT CSAIL and Meta conducted detailed research and proposed a framework named Heterogeneous Pre-trained Transformers (HPT). It is a family of architecture designed to scalably learn from data across heterogeneous embodiments. HPT’s main function is to create a shared understanding or representation of tasks that can be used by different robots in various conditions. Instead of training a robot from scratch for each new task or environment, HPT allows robots to use pre-learned knowledge, making the training process faster and more efficient. This architecture combines the proprioception and vision inputs from distinct embodiments into a short sequence of tokens, which are then processed to control robots for various tasks.
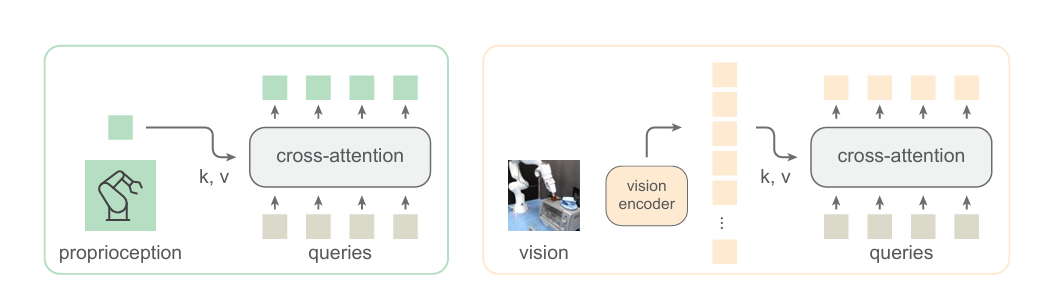
The architecture of HPT consists of the embodiment-specific stem, the shared trunk, and the task-specific heads. HPT is inspired by learning from multimodal data and uses embodiment-specific tokenizers, known as stem, to combine various sensor inputs such as camera views and body movements data. The trunk is a shared model and pre-trained across datasets and is transferred when adapting to new embodiments and tasks that are unknown during the pre-training times. Moreover, it uses task-specific action decoders to produce the action outputs known as heads. After tokenizing each embodiment, HPT operates on a shared space of a short sequence of latent tokens.
The scaling behaviors and various designs of policy pre-training were investigated using more than 50 individual data sources and a model size of over 1 billion parameters. Many available embodied datasets in different embodiments, such as real robots, simulations, and internet human videos, were incorporated into the pre-training process. The results showed that the HPT framework works well not only with costly real-world robot operations but also with other types of embodiments. It outperforms several baselines and enhances the fine-tuned policy performance by over 20% on unseen tasks in multiple simulator benchmarks and real-world settings.
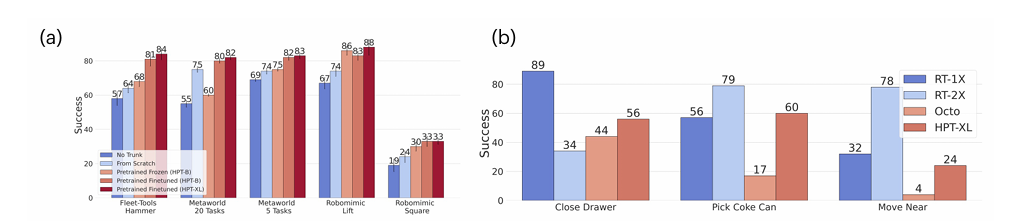
In conclusion, the proposed framework addresses the heterogeneity and mitigates challenges related to robotic learning by leveraging pre-trained models. The method shows significant improvements in generalization and performance across many robotic tasks and embodiments. Although the model architecture and training procedure can work with different setups, pre-training with varied data can take a longer time to converge. This perspective towards robotics can inspire future work in handling the heterogeneous nature of robotic data for robotic foundation models!
Check out the Paper, Project, and MIT Blog. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Sponsorship Opportunity with us] Promote Your Research/Product/Webinar with 1Million+ Monthly Readers and 500k+ Community Members
The post MIT Researchers Developed Heterogeneous Pre-trained Transformers (HPTs): A Scalable AI Approach for Robotic Learning from Heterogeneous Data appeared first on MarkTechPost.
“}]] [[{“value”:”In today’s world, building robotic policies is difficult. It often requires collecting specific data for each robot, task, and environment, and the learned policies do not generalize beyond these specific settings. Recent progress in open-source, large-scale data collection has made pre-training on large-scale, high-quality, and diverse data possible. However, in robotics, heterogeneity poses a challenge
The post MIT Researchers Developed Heterogeneous Pre-trained Transformers (HPTs): A Scalable AI Approach for Robotic Learning from Heterogeneous Data appeared first on MarkTechPost.”}]] Read More AI Paper Summary, AI Shorts, Artificial Intelligence, Editors Pick, Staff, Tech News, Technology