[[{“value”:”

In real-world settings, agents often face limited visibility of the environment, complicating decision-making. For instance, a car-driving agent must recall road signs from moments earlier to adjust its speed, yet storing all observations is unscalable due to memory limits. Instead, agents must learn compressed representations of observations. This challenge is compounded in ongoing tasks, where essential past information can only sometimes be retained efficiently. Incremental state construction is key in partially observable online reinforcement learning (RL), where recurrent neural networks (RNNs) like LSTMs handle sequences effectively, though they’re tough to train. Transformers capture long-term dependencies but come with higher computational costs.
Various approaches have extended linear transformers to address their limitations in handling sequential data. One architecture uses a scalar gating method to accumulate values over time, while others add recurrence and non-linear updates to enhance learning from sequential dependencies, although this can reduce parallelization efficiency. Additionally, some models selectively calculate sparse attention or cache previous activations, allowing them to attend to longer sequences without significant memory cost. Other recent innovations reduce the complexity of self-attention, improving transformers’ ability to process long contexts efficiently. Though transformers are commonly used in offline reinforcement learning, their application in model-free settings is still emerging.
Researchers from the University of Alberta and Amii developed two new transformer architectures tailored for partially observable online reinforcement learning, addressing issues with high inference costs and memory demands typical of traditional transformers. Their proposed models, GaLiTe and AGaLiTe, implement a gated self-attention mechanism to manage and update information efficiently, providing a context-independent inference cost and improved performance in long-range dependencies. Testing in 2D and 3D environments, like T-Maze and Craftax, showed these models outperformed or matched the state-of-the-art GTrXL, reducing memory and computation by over 40%, with AGaLiTe achieving up to 37% better performance on complex tasks.
The Gated Linear Transformer (GaLiTe) enhances linear transformers by addressing key limitations, particularly the lack of mechanisms to remove outdated information and the reliance on the kernel feature map choice. GaLiTe introduces a gating mechanism to control information flow, allowing selective memory retention and a parameterized feature map to compute key and query vectors without needing specific kernel functions. For further efficiency, the Approximate Gated Linear Transformer (AGaLiTe) utilizes a low-rank approximation to reduce memory demands, storing recurrent states as vectors rather than matrices. This approach achieves significant space and time savings compared to other architectures, especially in complex reinforcement learning tasks.
The study evaluates the proposed AGaLiTe model across several partially observable RL tasks. In these environments, agents require memory to handle different levels of partial observability, such as recalling single cues in T-Maze, integrating information over time in CartPole, or navigating through complex environments like Mystery Path, Craftax, and Memory Maze. AGaLiTe, equipped with a streamlined self-attention mechanism, achieves high performance, surpassing traditional models like GTrXL and GRU in effectiveness and computational efficiency. The results indicate that AGaLiTe’s design significantly reduces operations and memory usage, offering advantages for RL tasks with extensive context requirements.
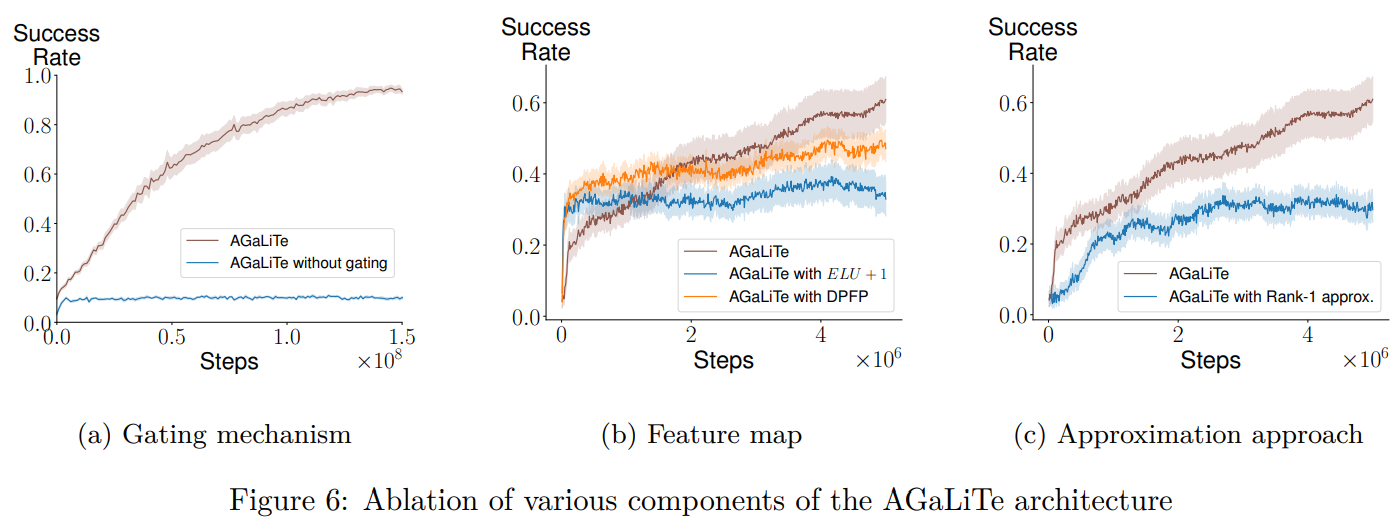
In conclusion, Transformers are highly effective for sequential data processing but face limitations in online reinforcement learning due to high computational demands and the need to maintain all historical data for self-attention. This study introduces two efficient alternatives to transformer self-attention, GaLiTe, and AGaLiTe, which are recurrent-based and designed for partially observable RL tasks. Both models perform competitively or better than GTrXL, with over 40% lower inference costs and over 50% reduced memory usage. Future research may improve AGaLiTe with real-time learning updates and applications in model-based RL approaches like Dreamer V3.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[FREE AI WEBINAR] Implementing Intelligent Document Processing with GenAI in Financial Services and Real Estate Transactions– From Framework to Production
The post GaLiTe and AGaLiTe: Efficient Transformer Alternatives for Partially Observable Online Reinforcement Learning appeared first on MarkTechPost.
“}]] [[{“value”:”In real-world settings, agents often face limited visibility of the environment, complicating decision-making. For instance, a car-driving agent must recall road signs from moments earlier to adjust its speed, yet storing all observations is unscalable due to memory limits. Instead, agents must learn compressed representations of observations. This challenge is compounded in ongoing tasks, where
The post GaLiTe and AGaLiTe: Efficient Transformer Alternatives for Partially Observable Online Reinforcement Learning appeared first on MarkTechPost.”}]] Read More AI Paper Summary, AI Shorts, Applications, Artificial Intelligence, Editors Pick, Machine Learning, Staff, Tech News, Technology