[[{“value”:”

Deploying machine learning models on edge devices poses significant challenges due to limited computational resources. When the size and complexity of models increase, even achieving efficient inference becomes challenging. Applications such as autonomous vehicles, AR glasses, and humanoid robots require low-latency and memory-efficient operations. In such applications, current approaches fail to handle even the computational and memory overhead brought about by intricate architectures such as transformers or foundation models, making real-time, resource-aware inference a critical need.
To overcome these challenges, researchers have developed methods such as pruning, quantization, and knowledge distillation to reduce model size and system-level techniques like operator fusion and constant folding. Although effective in specific scenarios, such approaches often focus on single optimizations, ignoring the possibility of jointly optimizing the entire computational graphs. Traditional memory management techniques in standard frameworks pay little respect to the connections and configurations of the contemporary neural networks, leading to much less than optimum performance in large-scale applications.
FluidML is an innovative framework for inference optimization that holistically transforms model execution blueprints. It focuses on graph-operator integration along with streamlining memory layouts across computational graphs, uses dynamic programming for efficient scheduling at runtime, and the means of advanced access to memory such as loop reordering for computationally demanding tasks such as matrix multiplication. FluidML provides end-to-end cross-platform compatibility by using a front end based on ONNX and compilation based on LLVM to support many operators and infers well for most applications.
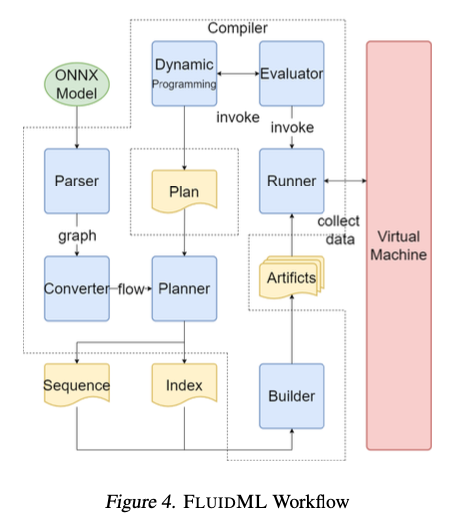
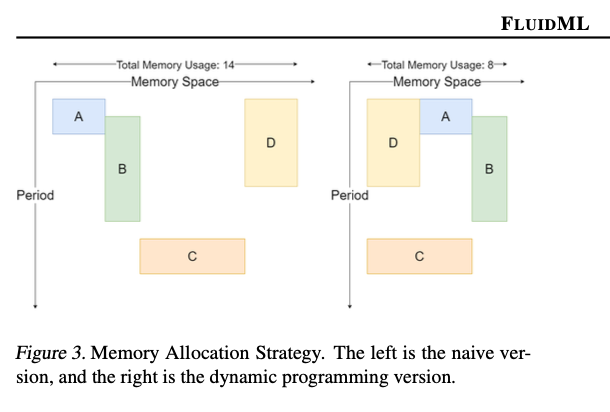
FluidML uses advanced techniques to enhance inference execution. It identifies the longest computational sequences in a graph and segments them into subgraphs for recursive optimization using dynamic programming. Efficient memory layouts are scheduled for execution sequences and conflicts are resolved using dependency-based voting mechanisms. FluidML is built on top of both MLIR and LLVM IR which enables seamless inclusion within existing workflows to minimize overhead while maximizing performance. This will improve usage of the cache and time to complete memory-intensive operations such as matrix multiplication and convolution.
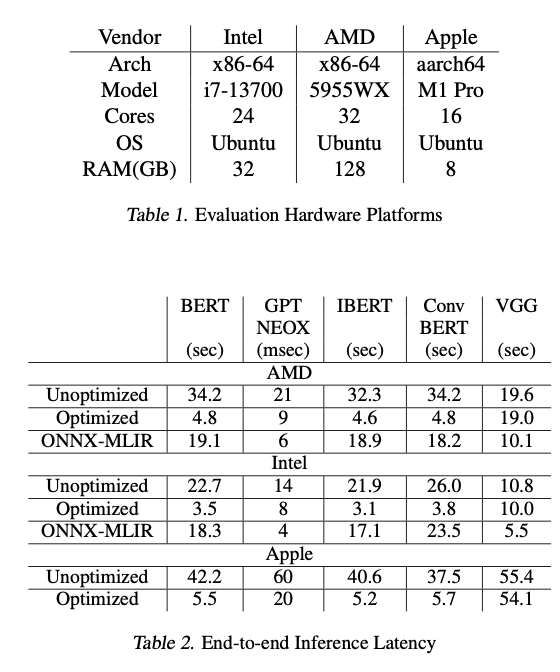
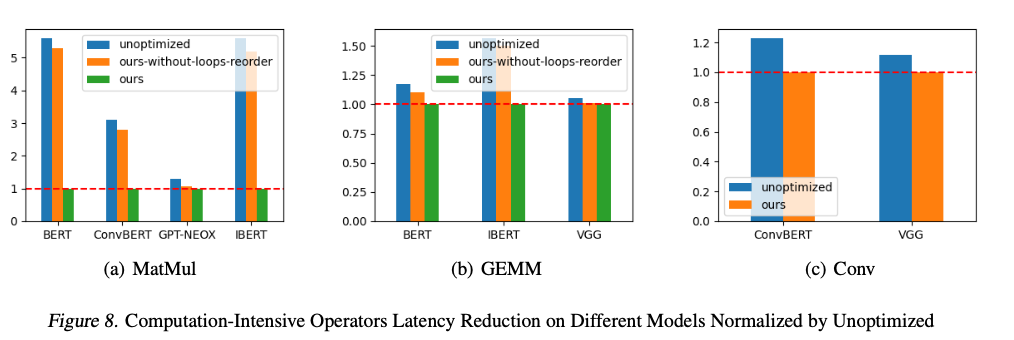
FluidML delivered significant performance improvements, achieving up to 25.38% reduction in inference latency and up to 41.47% reduction in peak memory usage across multiple hardware platforms. These enhancements were consistent across models, ranging from transformer-based language models like BERT and GPT-NEOX to vision models like VGG. Through a streamlined memory layout strategy and optimized execution of computationally expensive operations, FluidML established superiority in comparison with the state-of-the-art ONNX-MLIR and Apache TVM, making it a robust, efficient solution for resource-constrained environments.
In conclusion, FluidML provides context for the revolutionary optimization of inference run time and memory use in edge computing environments. The holistic design integrates in one coherent piece memory-layout optimization, graph segmentation, and superior scheduling techniques, some of which fill a gap left by current solutions. Huge latency and memory efficiency gains help in the real-time deployment of complex machine learning models even in highly resource-constrained use cases.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[FREE AI VIRTUAL CONFERENCE] SmallCon: Free Virtual GenAI Conference ft. Meta, Mistral, Salesforce, Harvey AI & more. Join us on Dec 11th for this free virtual event to learn what it takes to build big with small models from AI trailblazers like Meta, Mistral AI, Salesforce, Harvey AI, Upstage, Nubank, Nvidia, Hugging Face, and more.
The post Meet FluidML: A Generic Runtime Memory Management and Optimization Framework for Faster, Smarter Machine Learning Inference appeared first on MarkTechPost.
“}]] [[{“value”:”Deploying machine learning models on edge devices poses significant challenges due to limited computational resources. When the size and complexity of models increase, even achieving efficient inference becomes challenging. Applications such as autonomous vehicles, AR glasses, and humanoid robots require low-latency and memory-efficient operations. In such applications, current approaches fail to handle even the computational
The post Meet FluidML: A Generic Runtime Memory Management and Optimization Framework for Faster, Smarter Machine Learning Inference appeared first on MarkTechPost.”}]] Read More AI Paper Summary, AI Shorts, Applications, Artificial Intelligence, Editors Pick, Machine Learning, Staff, Tech News, Technology