[[{“value”:”

Automated software engineering (ASE) has emerged as a transformative field, integrating artificial intelligence with software development processes to tackle debugging, feature enhancement, and maintenance challenges. ASE tools increasingly employ large language models (LLMs) to assist developers, enhancing efficiency and addressing the rising complexity of software systems. However, most state-of-the-art tools rely on proprietary closed-source models, which limit their accessibility and flexibility, particularly for organizations with stringent privacy requirements or resource constraints. Despite recent breakthroughs in the field, ASE continues to grapple with the challenges of implementing scalable, real-world solutions that can dynamically address the nuanced needs of software engineering.
One significant limitation of existing approaches stems from their over-reliance on static data for training. While effective in generating function-level solutions, models like GPT-4 and Claude 3.5 struggle with tasks that require a deep contextual understanding of project-wide dependencies or the iterative nature of real-world software development. These models are trained primarily on static codebases, failing to capture developers’ dynamic problem-solving workflows when interacting with complex software systems. The absence of process-level insights hampers their ability to localize faults effectively and propose meaningful solutions. Furthermore, closed-source models introduce data privacy concerns, especially for organizations working with sensitive or proprietary codebases.
Researchers at Alibaba Group’s Tongyi Lab developed the Lingma SWE-GPT series, a set of open-source LLMs optimized for software improvement. The series includes two models, Lingma SWE-GPT 7B and 72B, designed to simulate real-world software development processes. Unlike their closed-source counterparts, these models are accessible, customizable, and engineered to capture the dynamic aspects of software engineering. By integrating insights from real-world code submission activities and iterative problem-solving workflows, Lingma SWE-GPT aims to close the performance gap between open- and closed-source models while maintaining accessibility.
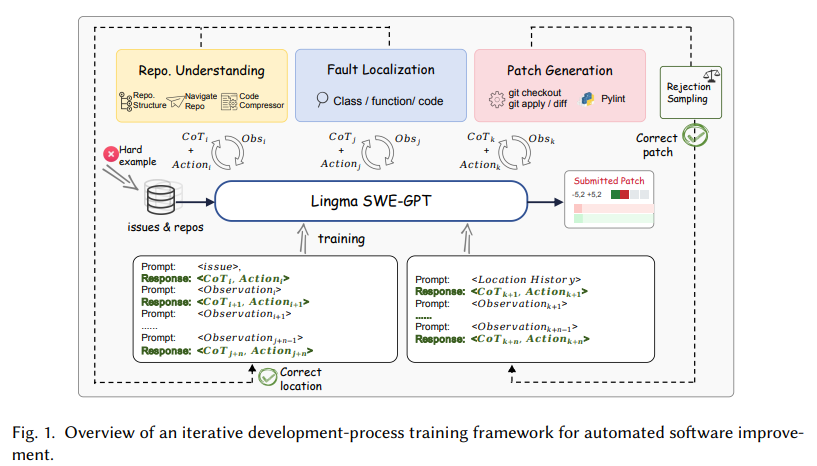
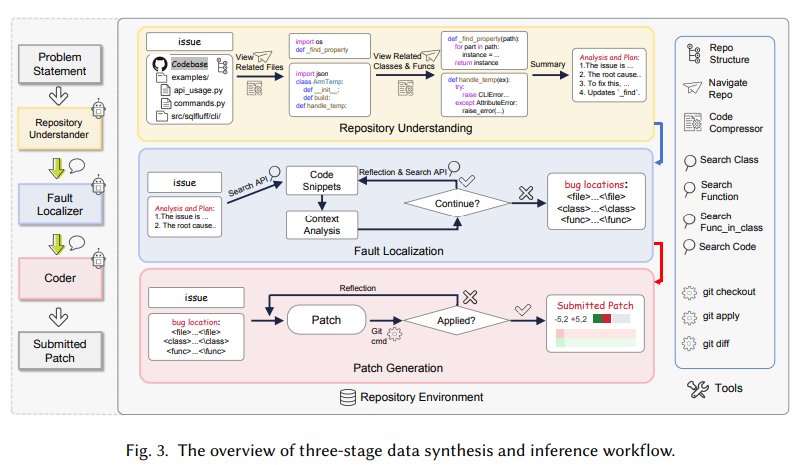
The development of Lingma SWE-GPT follows a structured three-stage methodology: repository understanding, fault localization, and patch generation. In the first stage, the model analyzes a project’s repository hierarchy, extracting key structural information from directories, classes, and functions to identify relevant files. During the fault localization phase, the model employs iterative reasoning and specialized APIs to pinpoint problematic code snippets precisely. Finally, the patch generation stage focuses on creating and validating fixes, using git operations to ensure code integrity. The training process emphasizes process-oriented data synthesis, employing rejection sampling and curriculum learning to refine the model iteratively and progressively handle more complex tasks.
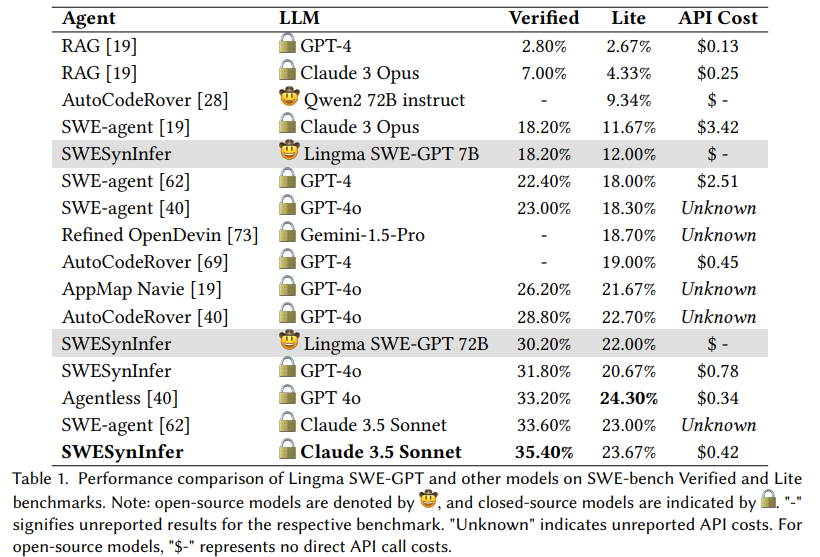
Performance evaluations demonstrate the effectiveness of Lingma SWE-GPT on benchmarks such as SWE-bench Verified and SWE-bench Lite, which simulate real-world GitHub issues. The Lingma SWE-GPT 72B model resolved 30.20% of matters in the SWE-bench Verified dataset, a significant achievement for an open-source model. This performance approaches that of GPT-4o, which resolved 31.80% of the issues and represented a 22.76% improvement over the open-source Llama 3.1 405B model. Meanwhile, the smaller Lingma SWE-GPT 7B model achieved an 18.20% success rate on SWE-bench Verified, outperforming Llama 3.1 70B’s 17.20%. These results highlight the potential of open-source models in bridging performance gaps while remaining cost-effective.
The SWE-bench evaluations also revealed Lingma SWE-GPT’s robustness across various repositories. For instance, in repositories like Django and Matplotlib, the 72B model consistently outperformed its competitors, including leading open-source and closed-source models. Moreover, the smaller 7B variant proved highly efficient for resource-constrained scenarios, demonstrating the scalability of Lingma SWE-GPT’s architecture. The cost advantage of open-source models further bolsters their appeal, as they eliminate the high API costs associated with closed-source alternatives. For example, resolving the 500 tasks in the SWE-bench Verified dataset using GPT-4o would cost approximately $390, whereas Lingma SWE-GPT incurs no direct API costs.
The research also underscores several key takeaways that illustrate the broader implications of Lingma SWE-GPT’s development:
- Open-source accessibility: Lingma SWE-GPT models democratize advanced ASE capabilities, making them accessible to various developers and organizations.
- Performance parity: The 72B model achieves performance comparable to state-of-the-art closed-source models, resolving 30.20% of issues on SWE-bench Verified.
- Scalability: The 7B model demonstrates strong performance in constrained environments, offering a cost-effective solution for organizations with limited resources.
- Dynamic understanding: By incorporating process-oriented training, Lingma SWE-GPT captures software development’s iterative and interactive nature, bridging gaps left by static data training.
- Enhanced fault localization: The model’s ability to identify specific fault locations using iterative reasoning and specialized APIs ensures high accuracy and efficiency.

In conclusion, Lingma SWE-GPT represents a significant step forward in ASE, addressing the critical limitations of static data training and closed-source dependency. Its innovative methodology and competitive performance make it a compelling alternative for organizations seeking scalable and open-source solutions. By combining process-oriented insights with high accessibility, Lingma SWE-GPT paves the way for broader adoption of AI-assisted tools in software development, making advanced capabilities more inclusive and cost-efficient.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[FREE AI VIRTUAL CONFERENCE] SmallCon: Free Virtual GenAI Conference ft. Meta, Mistral, Salesforce, Harvey AI & more. Join us on Dec 11th for this free virtual event to learn what it takes to build big with small models from AI trailblazers like Meta, Mistral AI, Salesforce, Harvey AI, Upstage, Nubank, Nvidia, Hugging Face, and more.
The post Lingma SWE-GPT: Pioneering AI-Assisted Solutions for Software Development Challenges with Innovative Open-Source Models appeared first on MarkTechPost.
“}]] [[{“value”:”Automated software engineering (ASE) has emerged as a transformative field, integrating artificial intelligence with software development processes to tackle debugging, feature enhancement, and maintenance challenges. ASE tools increasingly employ large language models (LLMs) to assist developers, enhancing efficiency and addressing the rising complexity of software systems. However, most state-of-the-art tools rely on proprietary closed-source models,
The post Lingma SWE-GPT: Pioneering AI-Assisted Solutions for Software Development Challenges with Innovative Open-Source Models appeared first on MarkTechPost.”}]] Read More AI Paper Summary, AI Shorts, Applications, Artificial Intelligence, Editors Pick, Machine Learning, Software Engineering, Staff, Tech News, Technology