[[{“value”:”

Speech synthesis has become a transformative research area, focusing on creating natural and synchronized audio outputs from diverse inputs. Integrating text, video, and audio data provides a more comprehensive approach to mimic human-like communication. Advances in machine learning, particularly transformer-based architectures, have driven innovations, enabling applications like cross-lingual dubbing and personalized voice synthesis to thrive.
A persistent challenge in this field is accurately aligning speech with visual and textual cues. Traditional methods, such as cropped lip-based speech generation or text-to-speech (TTS) models, have limitations. These approaches often need help maintaining synchronization and naturalness in varied scenarios, such as multilingual settings or complex visual contexts. This bottleneck limits their usability in real-world applications requiring high fidelity and contextual understanding.

Existing tools rely heavily on single-modality inputs or complex architectures for multimodal fusion. For example, lip-detection models use pre-trained systems to crop input videos, while some text-based systems process only linguistic features. Despite these efforts, the performance of these models remains suboptimal, as they often fail to capture broader visual and textual dynamics critical for natural speech synthesis.
Researchers from Apple and the University of Guelph have introduced a novel multimodal transformer model named Visatronic. This unified model processes video, text, and speech data through a shared embedding space, leveraging autoregressive transformer capabilities. Unlike traditional multimodal architectures, Visatronic eliminates lip-detection pre-processing, offering a streamlined solution for generating speech aligned with textual and visual inputs.
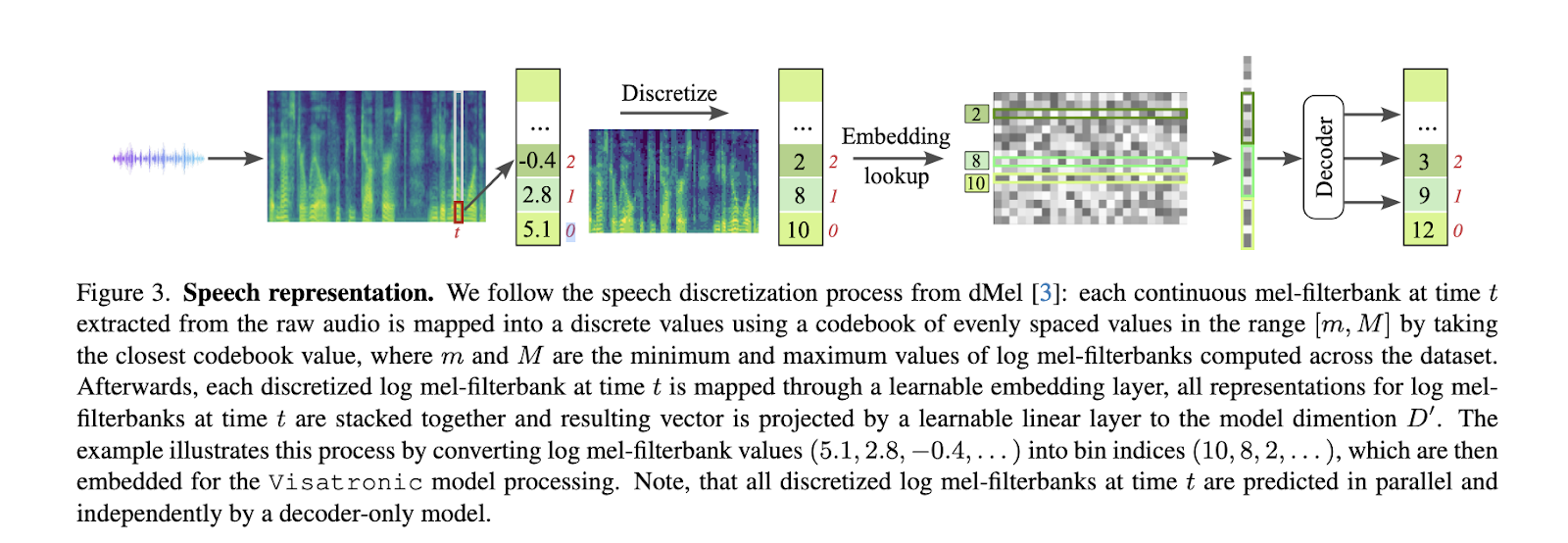
The methodology behind Visatronic is built on embedding and discretizing multimodal inputs. A vector-quantized variational autoencoder (VQ-VAE) encodes video inputs into discrete tokens, while speech is quantized into mel-spectrogram representations using dMel, a simplified discretization approach. Text inputs undergo character-level tokenization, which improves generalization by capturing linguistic subtleties. These modalities are integrated into a single transformer architecture that enables interactions across inputs through self-attention mechanisms. The model employs temporal alignment strategies to synchronize data streams with varied resolutions, such as video at 25 frames per second and speech sampled at 25ms intervals. Furthermore, the system incorporates relative positional embeddings to maintain temporal coherence across inputs. Cross-entropy loss is applied exclusively to speech representations during training, ensuring robust optimization and cross-modal learning.
Visatronic demonstrated significant advancements in performance on challenging datasets. On the VoxCeleb2 dataset, which includes diverse and noisy conditions, the model achieved a Word Error Rate (WER) of 12.2%, outperforming previous approaches. It also attained 4.5% WER on the LRS3 dataset without additional training, showcasing strong generalization capabilities. In contrast, traditional TTS systems scored higher WERs and lacked the synchronization precision required for complex tasks. Subjective evaluations further confirmed these findings, with Visatronic scoring higher intelligibility, naturalness, and synchronization than benchmarks. The VTTS (video-text-to-speech) ordered variant achieved a mean opinion score (MOS) of 3.48 for intelligibility and 3.20 for naturalness, outperforming models trained solely on textual inputs.
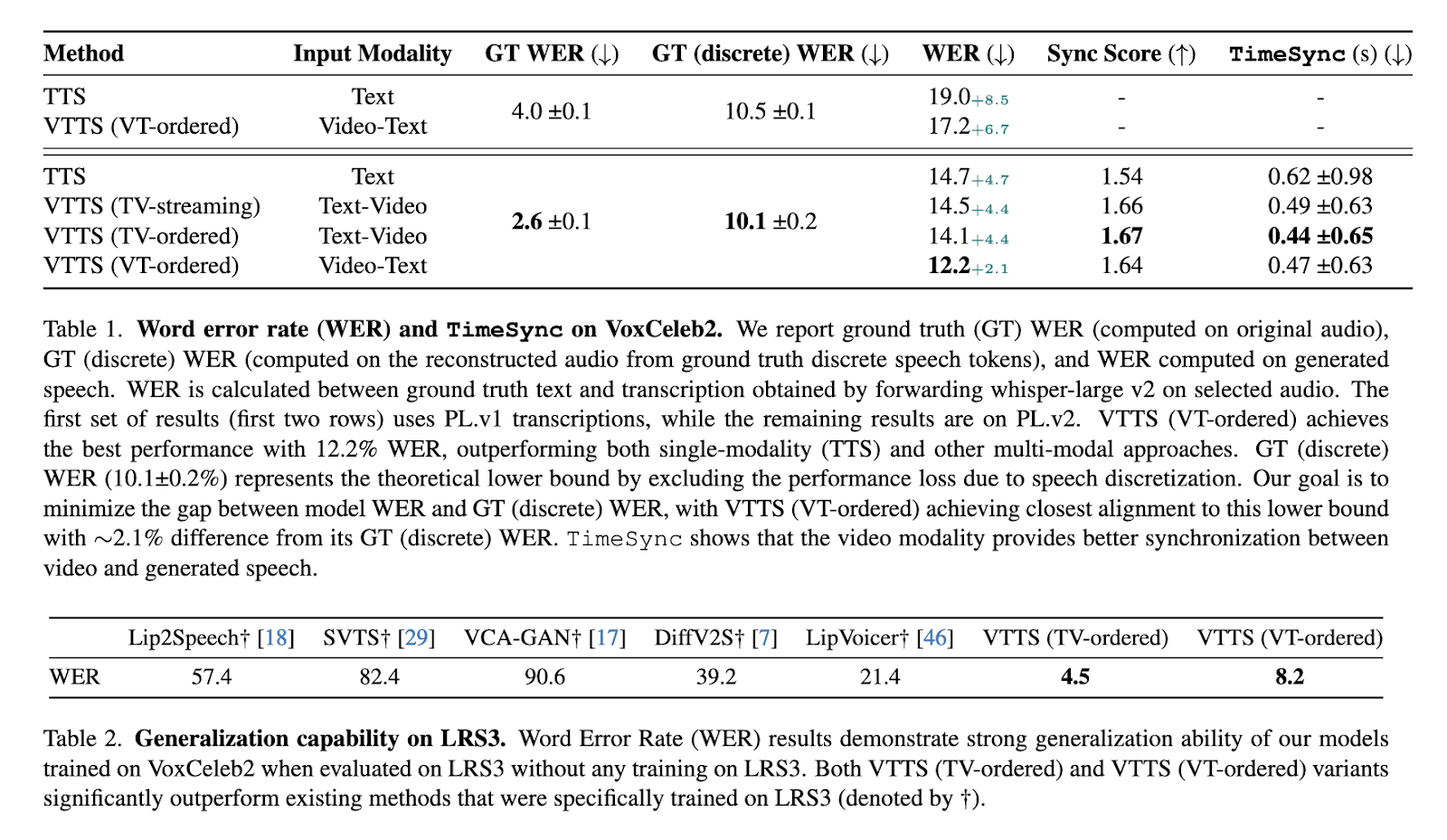
The integration of video modality not only improved content generation but also reduced training time. For example, Visatronic variants achieved comparable or better performance after two million training steps compared to three million for text-only models. This efficiency highlights the complementary value of combining modalities, as text contributes content precision while video enhances contextual and temporal alignment.
In conclusion, Visatronic represents a breakthrough in multimodal speech synthesis by addressing key challenges of naturalness and synchronization. Its unified transformer architecture seamlessly integrates video, text, and audio data, delivering superior performance across diverse conditions. This innovation, developed by researchers at Apple and the University of Guelph, sets a new standard for applications ranging from video dubbing to accessible communication technologies, paving the way for future advancements in the field.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.

 ‘
‘The post Visatronic: A Unified Multimodal Transformer for Video-Text-to-Speech Synthesis with Superior Synchronization and Efficiency appeared first on MarkTechPost.
“}]] [[{“value”:”Speech synthesis has become a transformative research area, focusing on creating natural and synchronized audio outputs from diverse inputs. Integrating text, video, and audio data provides a more comprehensive approach to mimic human-like communication. Advances in machine learning, particularly transformer-based architectures, have driven innovations, enabling applications like cross-lingual dubbing and personalized voice synthesis to thrive.
The post Visatronic: A Unified Multimodal Transformer for Video-Text-to-Speech Synthesis with Superior Synchronization and Efficiency appeared first on MarkTechPost.”}]] Read More AI Paper Summary, AI Shorts, Applications, Artificial Intelligence, Editors Pick, Language Model, Machine Learning, Staff, Tech News, Technology