[[{“value”:”

Large Vision Language Models (LVLMs) have demonstrated significant advancements across various challenging multi-modal tasks over the past few years. Their ability to interpret visual information in figures, known as visual perception, relied on visual encoders and multimodal training. Even with these advancements, visual perception errors still cause many mistakes in LVLMs and impact their ability to understand image details needed for tasks.
Recent popular datasets for evaluating LVLMs, such as MMMU and MathVista, dont focus on visual perception and target tasks that require expert-level reasoning and knowledge. In addition, performance on these datasets is affected by several capabilities, and because visual perception is difficult to evaluate directly, it is difficult to assess performance. Most benchmarks on multimodal reasoning in scientific figures are usually restricted to application domains that demand expert knowledge and neglect visual perception. General visual perception datasets target tasks like OCR, depth estimation, and counting but lack fine-grained detail due to the challenge of designing specific questions. While some datasets are designed to evaluate the visual perception of LVLMs, they often target less fine-grained visual information, such as scene understanding.
To solve this, a group of researchers from Penn State University proposed VisOnlyQA, a new dataset designed to directly evaluate the visual perception capabilities of LVLMs on questions about geometric and numerical information in scientific figures. Bridging the gap, VisOnlyQA focused on fine-grain visual details and objective assessment of LVLMs’ visual perception capability to build new limitations on prior datasets and generated synthetic figures from scripts, including diversity and precision. Questions were manually annotated or generated automatically using metadata and templates, avoiding the need for reasoning or domain knowledge. The dataset had three splits: Eval-Real, Eval-Synthetic, and Train, with balanced labels and high annotation quality confirmed by human performance (93.5% to 95% accuracy).
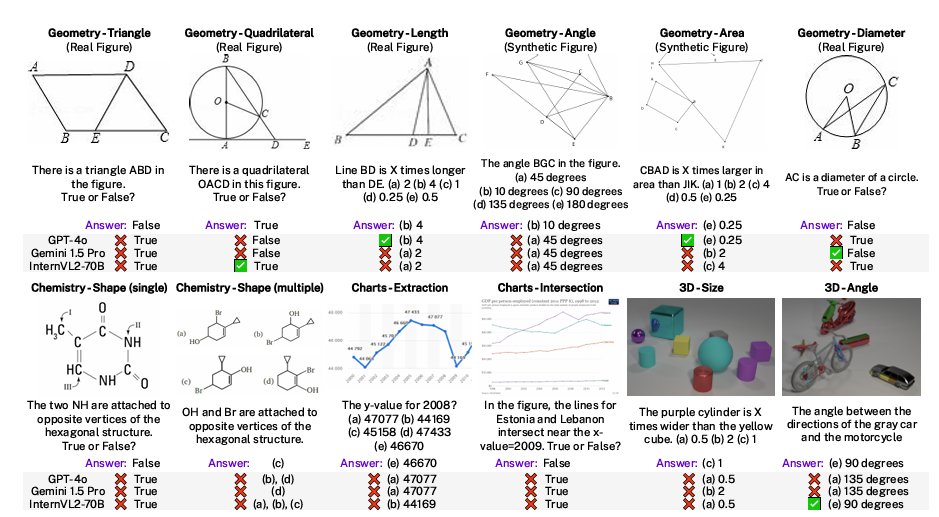
The study evaluates the performance of 20 open-source and proprietary LVLMs on the VisOnlyQA dataset, focusing on their visual perception capabilities. The models were assessed on geometry, chemistry, and chart analysis tasks, with and without chain-of-thought reasoning. Results showed that the models performed significantly worse than humans, with average accuracies around 54.2% for the real-world dataset and 42.4% for synthetic data, far below human performance (93.5% and 95.0%, respectively).
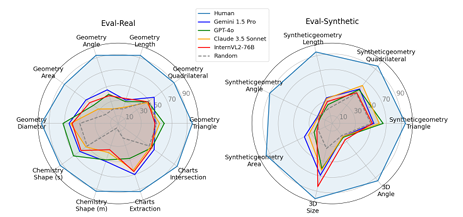
Despite the large model sizes, such as Phi-3.5-Vision and LLaVA-Next, many of the models performed near-randomly on tasks like Geometry-Triangle and Charts Intersection, indicating that current LVLMs still struggle with visual perception tasks involving geometric and numerical information. The analysis also showed that chain-of-thought reasoning did not consistently improve performance and, in some cases, even worsened it, further emphasizing that VisOnlyQA directly evaluates visual perception rather than requiring reasoning. Error analysis revealed that most mistakes were related to visual perception, supporting the dataset’s ability to assess this capability.
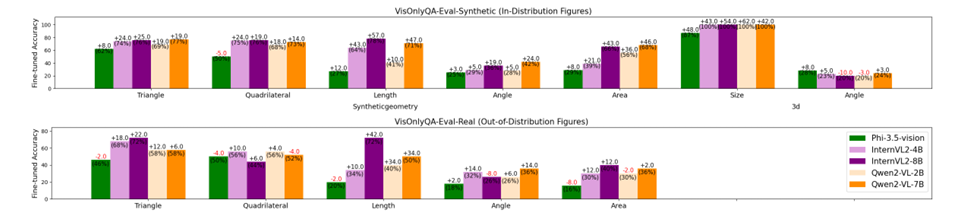
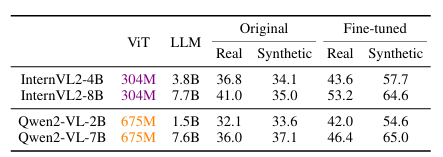
In conclusion, the proposed VisOnlyQA was introduced as a dataset to assess the visual perception abilities of LVLMs through questions on geometric and numerical details in scientific figures. This method revealed that LVLMs still lack strong visual perception capabilities. There is great scope in the future to improve training data and model architectures to enhance their visual perception. This method can open new ways in the field of LVLMs and can serve as a baseline for upcoming research!
Check out the Details here and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
 [Must Subscribe]: Subscribe to our newsletter to get trending AI research and dev updates
[Must Subscribe]: Subscribe to our newsletter to get trending AI research and dev updates
The post VisOnlyQA: A New Dataset for Evaluating the Visual Perception of LVLMs (Large Vision Language Models) appeared first on MarkTechPost.
“}]] [[{“value”:”Large Vision Language Models (LVLMs) have demonstrated significant advancements across various challenging multi-modal tasks over the past few years. Their ability to interpret visual information in figures, known as visual perception, relied on visual encoders and multimodal training. Even with these advancements, visual perception errors still cause many mistakes in LVLMs and impact their ability
The post VisOnlyQA: A New Dataset for Evaluating the Visual Perception of LVLMs (Large Vision Language Models) appeared first on MarkTechPost.”}]] Read More AI Paper Summary, AI Shorts, Applications, Artificial Intelligence, Dataset, Editors Pick, Staff, Tech News, Technology