[[{“value”:”

Transformer-based Detection models are gaining popularity due to their one-to-one matching strategy. Unlike familiar many-to-One Detection models like YOLO, which require Non-Maximum Suppression (NMS) to reduce redundancy, DETR models leverage Hungarian Algorithms and multi-head attention to establish a unique mapping between the detected object and ground truth, thus eliminating the need for intermediate NMS. While DETRs solve the challenge of latency and instability posed in O2O detection, they have limitations, primarily slow convergence. As per the most recent research in this domain, slow convergence in O2O detection could be attributed to -sparse supervision and low-quality matches. The inherent nature of the mechanism causes sparsity in training, as the assignment of only one positive sample per target limits the number of positive samples. It has a detrimental impact on model learning, especially for tiny object detection. The second diagnosis of low-quality matches is due to the small number of queries in DETR, which lack spatial alignment with targets, which leads to boxes with lower IOUs giving high-quality scores. Recent works have considered incorporating O2M assignments in the O2O mechanism, and while they do increase the density of samples, they require additional decoders that increase overhead and redundancy in predictions. This article discusses the latest research that presents a novel approach to O2O without compromising upon supervision density.
Researchers from Intellindust AI Lab DEIM: a transformer-based detection mechanism with improved matching for fast convergence. It combines two novel methods -Dense O2O with MAL to create an effective training algorithm where the first focuses on the number of matches while the second arranges for the quality. The main idea behind Dense O2O is to increase the number of targets in each training image, which leads to more positive samples with single mapping. This is elementary to implement with classic augmentation methods like mosaic or mixups. This elegant, Dense O2O strategy gives supervision at par with O2M without computational overheads. The authors provide a solution for low-quality matches that significantly rise in O2O Dense due to disparities between prominent and non-prominent targets. They introduce Matchability Aware Loss (MAL), which scales the penalty on low-quality matches by incorporating the IoU between matched queries and targets with classification confidence. It has a more straightforward formulation and performs at par with conventional losses for high-quality matches while improving on the lower ones.DEIM could be incorporated into existing DETRs to achieve better performance even at half the cost.
The working of Dense O2O could be best understood with an example. Given an image, it is first replicated into four quadrants and then combined back as a single composite image of congruent dimensions. This simple exercise quadruples the targets while keeping the matching structure unchanged.MAL, on the other hand, ensures the quality of matching by incorporating it into the loss function. Compared to the traditional losses in DETR, MAL simplifies loss weights for positive and negative samples and balances them, which avoids overemphasis on high-quality boxes.
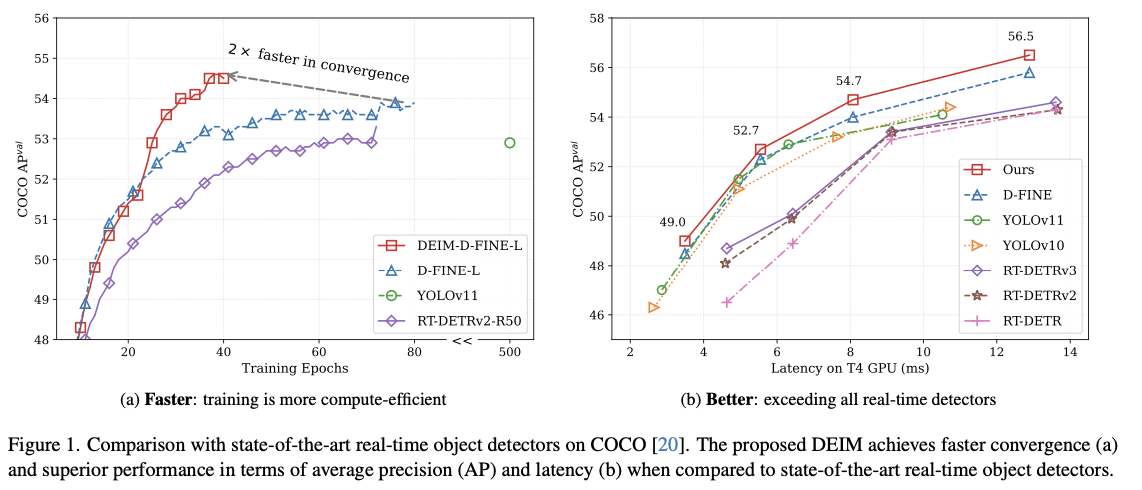
To assess the effectiveness of DEIM in DETR models, authors integrated this framework into O2O models such as D-FINE-L and D-FINE-X and compared it against SOTA O2M like YOLOV8 to 11 and DETR-based models like RTDETRv2 and D-FINE. Results from these series of comparisons validated DIEM, where models powered by it outperformed all others in training cost, inference latency, and detection accuracy. D-FINE, the most recent DETR model established as a leading real-time detector, achieved 0.7 AP and 30% reduced training cost upon incorporation of DEIM. Most significant improvements were observed in small object detection, where SOTA achieved an AP gain of 1.5. For O2M comparison, DIEM models achieved slightly higher AP than YOLO, which is the current talk of the town for detection.
Conclusion: DEIM presents a simple framework that solves the problem of slow convergence in DETR-based models. It performed better than the SOTA, especially in small object detection at much fewer epochs.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
 [Must Subscribe]: Subscribe to our newsletter to get trending AI research and dev updates
[Must Subscribe]: Subscribe to our newsletter to get trending AI research and dev updates
The post DEIM: A New AI Framework that Enhances DETRs for Faster Convergence and Accurate Object Detection appeared first on MarkTechPost.
“}]] [[{“value”:”Transformer-based Detection models are gaining popularity due to their one-to-one matching strategy. Unlike familiar many-to-One Detection models like YOLO, which require Non-Maximum Suppression (NMS) to reduce redundancy, DETR models leverage Hungarian Algorithms and multi-head attention to establish a unique mapping between the detected object and ground truth, thus eliminating the need for intermediate NMS. While
The post DEIM: A New AI Framework that Enhances DETRs for Faster Convergence and Accurate Object Detection appeared first on MarkTechPost.”}]] Read More AI Paper Summary, AI Shorts, Applications, Artificial Intelligence, Computer Vision, Editors Pick, Staff, Tech News, Technology