[[{“value”:”

Accurately predicting where a person is looking in a scene—gaze target estimation—represents a significant challenge in AI research. Integrating complex cues such as head orientation and scene context must be used to infer gaze direction. Traditionally, methods for this problem use multi-branch architectures, processing the scene and head features separately before integrating them with auxiliary inputs, such as depth and pose. However, these methods are computationally intensive, hard to train, and often fail to generalize well across datasets. This calls for overcoming these issues so that the applications in understanding human behavior, robotics, and assistive technologies can progress.
Existing gaze estimation methods heavily depend on multi-branch pipelines, where separate encoders handle the scene and head features, followed by fusion modules to combine these inputs. To improve efficiency, many of these models use additional signals, such as pose, depth, and auxiliary features, which are obtained from specific modules. However, these approaches have several limitations. First, their high computational cost makes real-time implementation impossible. Second, these systems generally require large amounts of labeled training data, which is labor-intensive and nearly impossible to scale. This limits their ability to transfer learned generalizations to numerous environments and datasets when relying on particular encoders with supplementary inputs.
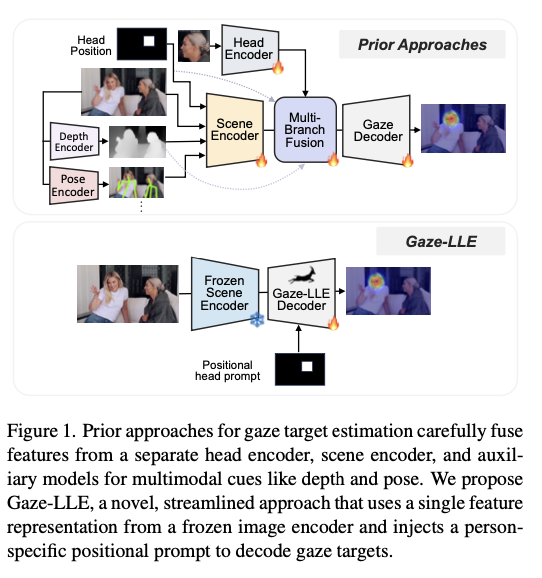
To address these issues, researchers from the Georgia Institute of Technology and the University of Illinois Urbana-Champaign introduced Gaze-LLE, a streamlined and efficient framework for gaze target estimation. Gaze-LLE eliminates the need for complex multi-branch architectures through a static DINOv2 visual encoder and a minimalist decoder module. The framework uses a unified backbone for feature extraction and has an innovative head positional prompting mechanism that allows the gaze estimation to be specific to certain individuals in the scene. Some of the primary contributions of this methodology are reducing trainable parameters to a significant level that translates into 95% fewer computations in comparison with traditional methods. Gaze-LLE is also a successful method in transforming transformer-based encoders at a large scale. It accurately enables gaze estimation without complex auxiliary models and allows for the maintenance of superior performance with minimal adjustments across a range of datasets and tasks through a simple and scalable architecture.
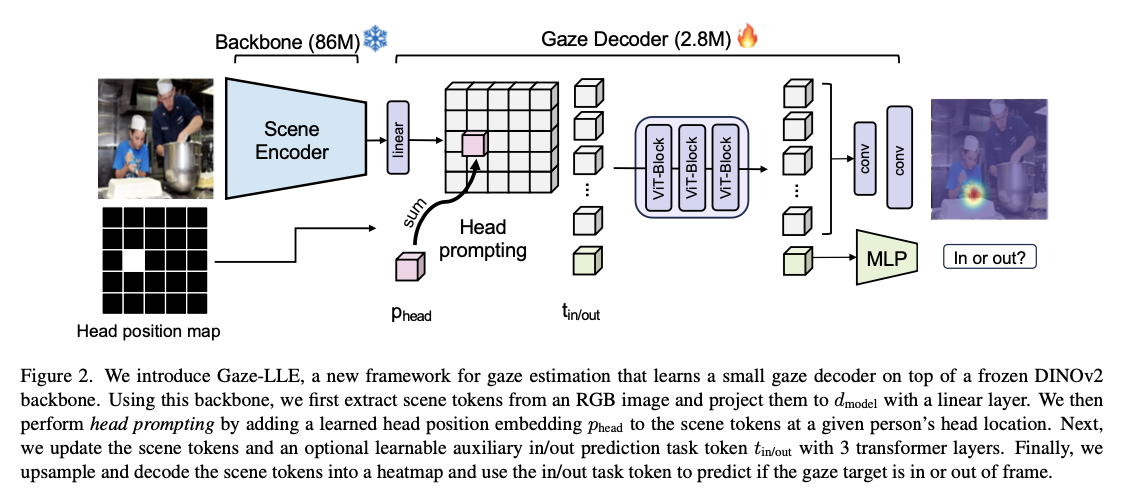
The architecture of Gaze-LLE comprises two main components. First, a frozen DINOv2 visual encoder extracts robust features from the input image, which are then projected into a lower-dimensional space via a linear layer for efficient processing. Second, a lightweight gaze decoder integrates these scene features with a head position embedding that encodes the location of the individual being observed. This mechanism allows the model to focus on the specific source of gaze. The gaze decoder consists of three transformer layers intended to be used for feature enhancement, and it produces a gaze heatmap that indicates possible targets of gaze, as well as an in-frame classification to determine whether the gaze falls within the observable frame. The simple model requires using a straightforward training objective: simply a pixel-wise binary cross-entropy loss, allowing the optimal tuning without a sophisticated approach based on complex multitasking objectives. Benchmarks comprised benchmark datasets: GazeFollow, VideoAttentionTarget, and ChildPlay.
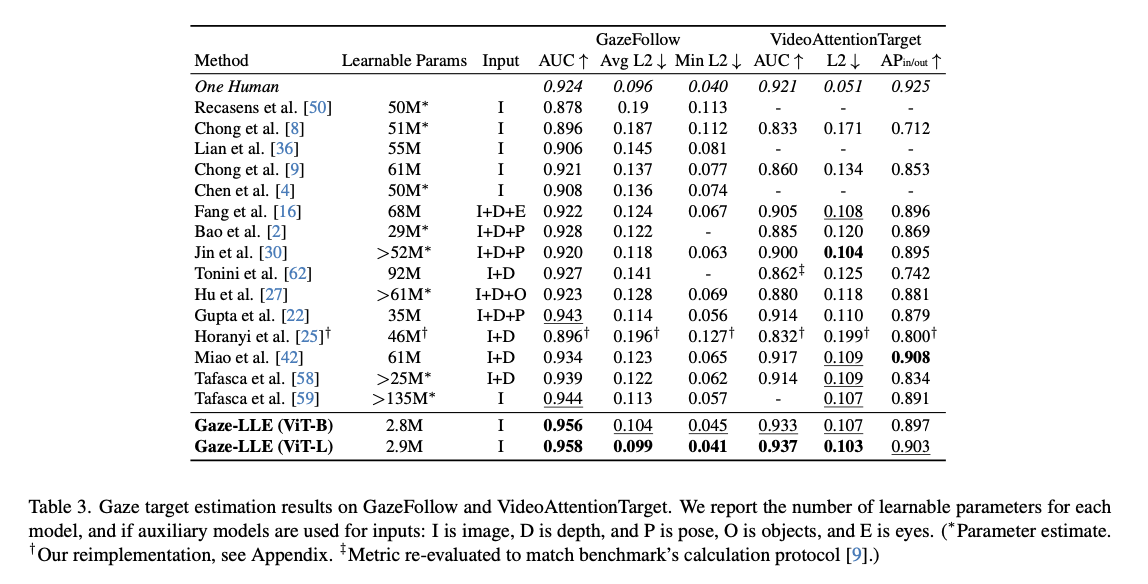
Gaze-LLE achieves state-of-the-art performance across multiple benchmarks with significantly fewer parameters and faster training times. The GazeFollow dataset, yields an AUC of 0.958 and an average L2 error of 0.099, besting prior methods both in precision and in computational efficiency. The training time is, in particular, remarkably efficient, with the model achieving convergence within less than 1.5 GPU hours and significantly outperforming traditional multi-branch architectures. Further, Gaze-LLE also exhibits strong generalization properties as its high performance is retained over several datasets, like ChildPlay and GOO-Real, even without fine-tuning. Results like these show that the frozen foundational models in an optimized architecture can be useful for accurate and flexible gaze estimation.

In summary, Gaze-LLE redefines gaze target estimation with a streamlined and effective framework that brings in fundamental visual encoders and an innovative head positional prompting system. Free from the intricacies of architectures with multiple branches, this achieves higher accuracy, better efficiency, and scalability. Moreover, its ability to generalize across various datasets provides promise for its applications in further research on human behavior and related fields, thus introducing a new benchmark for the advancement of gaze estimation research.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
 Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….
Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….The post Gaze-LLE: A New AI Model for Gaze Target Estimation Built on Top of a Frozen Visual Foundation Model appeared first on MarkTechPost.
“}]] [[{“value”:”Accurately predicting where a person is looking in a scene—gaze target estimation—represents a significant challenge in AI research. Integrating complex cues such as head orientation and scene context must be used to infer gaze direction. Traditionally, methods for this problem use multi-branch architectures, processing the scene and head features separately before integrating them with auxiliary
The post Gaze-LLE: A New AI Model for Gaze Target Estimation Built on Top of a Frozen Visual Foundation Model appeared first on MarkTechPost.”}]] Read More AI Paper Summary, AI Shorts, Applications, Artificial Intelligence, Computer Vision, Editors Pick, Staff, Tech News, Technology