[[{“value”:”

For education research, access to high-quality educational resources is critical for learners and educators. Often perceived as one of the most challenging subjects, mathematics requires clear explanations and well-structured resources to make learning more effective. However, creating and curating datasets focusing on mathematical education remains a formidable challenge. Many datasets for training machine learning models are proprietary, leaving little transparency in how educational content is selected, structured, or optimized for learning. The scarcity of accessible, open-source datasets addressing the complexity of mathematics leaves a gap in developing AI-driven educational tools.
Recognizing the above issues, Hugging Face has introduced FineMath, a groundbreaking initiative aimed at democratizing access to high-quality mathematical content for both learners and researchers. FineMath represents a comprehensive and open dataset tailored for mathematical education and reasoning. FineMath addresses the core challenges of sourcing, curating, and refining mathematical content from diverse online repositories. This dataset is meticulously constructed to meet the needs of machine learning models aiming to excel in mathematical problem-solving and reasoning tasks.
The dataset is divided into two primary versions:
- FineMath-3+: FineMath-3+ comprises 34 billion tokens derived from 21.4 million documents, formatted in Markdown and LaTeX to maintain mathematical integrity.
- FineMath-4+: FineMath-4+, a subset of FineMath-3+, boasts 9.6 billion tokens across 6.7 million documents, emphasizing higher-quality content with detailed explanations.
These curated subsets ensure that both general learners and advanced models benefit from FineMath’s robust framework.
Creating FineMath required a multi-phase approach to extract and refine content effectively. It started with extracting raw data from CommonCrawl, leveraging advanced tools such as Resiliparse to capture text and formatting precisely. The initial dataset was evaluated using a custom classifier based on Llama-3.1-70B-Instruct. This classifier scored pages based on logical reasoning and the clarity of step-by-step solutions. Subsequent phases focused on expanding the dataset’s breadth while maintaining its quality. Challenges like the improper filtering of LaTeX notation in earlier datasets were addressed, ensuring better preservation of mathematical expressions. Deduplication and multilingual evaluation further enhanced the dataset’s relevance and usability.
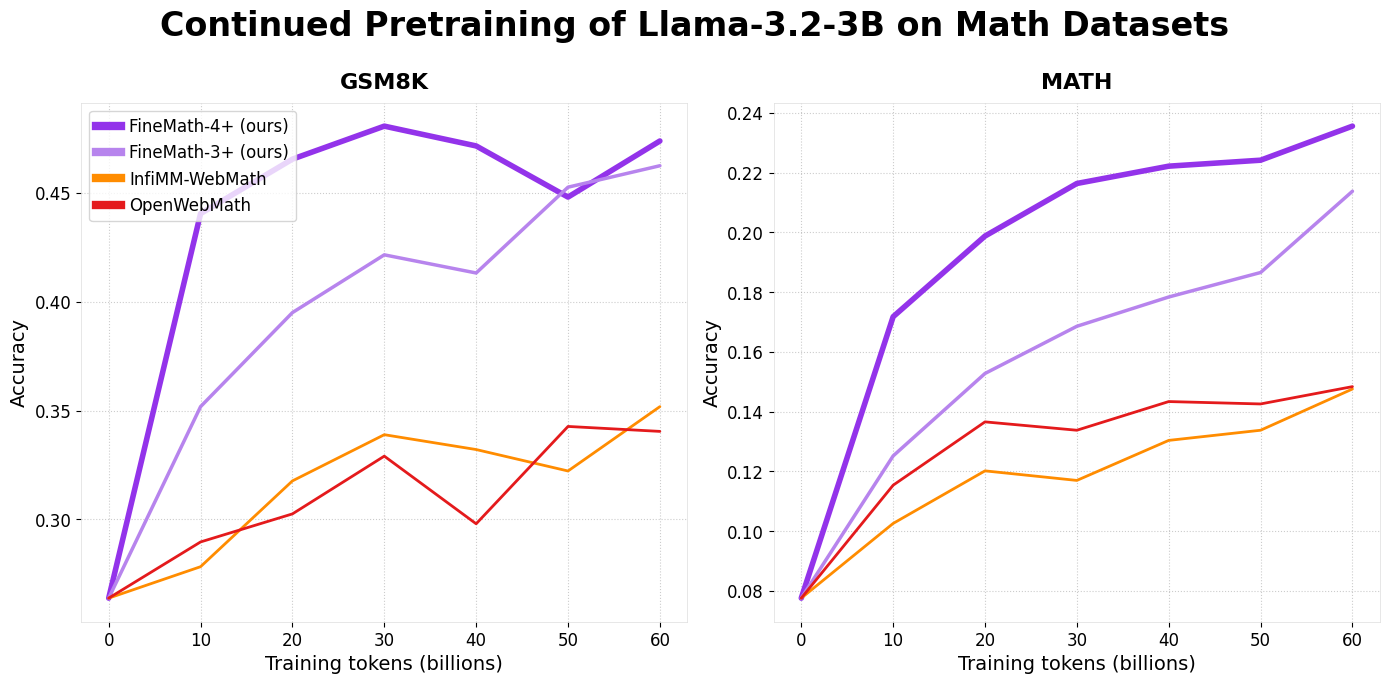
FineMath has demonstrated superior performance on established benchmarks like GSM8k and MATH. Models trained on FineMath-3+ and FineMath-4+ showed significant mathematical reasoning and accuracy improvements. By combining FineMath with other datasets, such as InfiMM-WebMath, researchers can achieve a larger dataset with approximately 50 billion tokens while maintaining exceptional performance. FineMath’s structure is optimized for seamless integration into machine learning pipelines. Developers can load subsets of the dataset using Hugging Face’s robust library support, enabling easy experimentation and deployment for various educational AI applications.
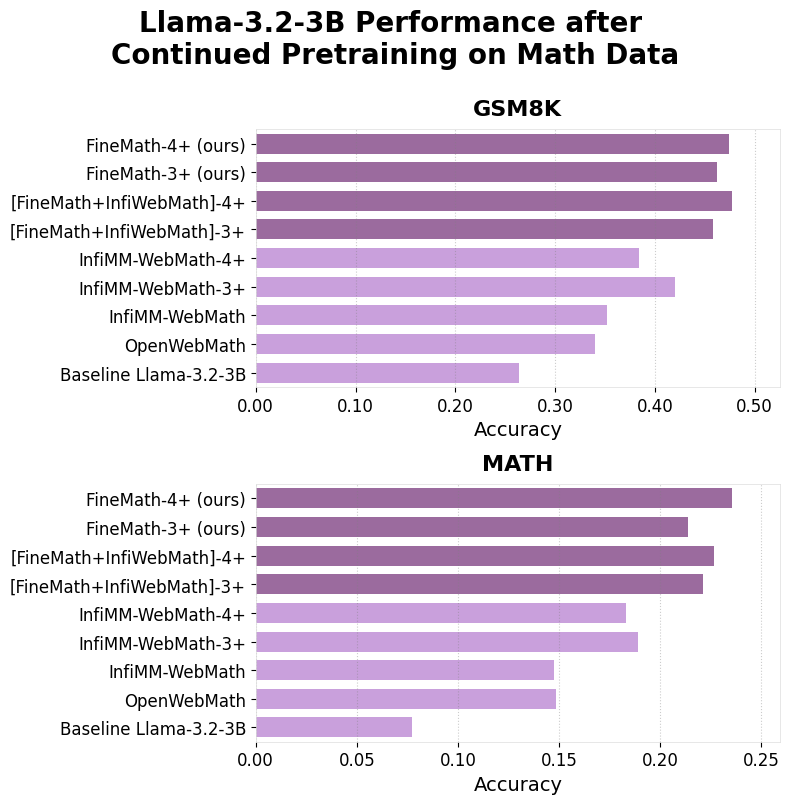
In conclusion, Hugging Face’s FineMath dataset is a transformative contribution to mathematical education and AI. Addressing the gaps in accessibility, quality, and transparency sets a new benchmark for open educational resources. Future work for FineMath includes expanding language support beyond English, enhancing mathematical notation extraction and preservation, developing advanced quality metrics, and creating specialized subsets tailored to different educational levels.
Check out the Collection and Dataset. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
 Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….
Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….The post Hugging Face Releases FineMath: The Ultimate Open Math Pre-Training Dataset with 50B+ Tokens appeared first on MarkTechPost.
“}]] [[{“value”:”For education research, access to high-quality educational resources is critical for learners and educators. Often perceived as one of the most challenging subjects, mathematics requires clear explanations and well-structured resources to make learning more effective. However, creating and curating datasets focusing on mathematical education remains a formidable challenge. Many datasets for training machine learning models
The post Hugging Face Releases FineMath: The Ultimate Open Math Pre-Training Dataset with 50B+ Tokens appeared first on MarkTechPost.”}]] Read More AI Shorts, Applications, Artificial Intelligence, Dataset, Editors Pick, Machine Learning, New Releases, Staff, Tech News, Technology