[[{“value”:”

Molecule discovery is important in various scientific research fields, particularly pharmaceuticals and materials science. While the emergence of Graph Neural Networks (GNNs) has revolutionized this field by enabling the representation of molecules as graphs and facilitating property predictions, it faces difficulties in generalizing across different tasks, requiring substantial task-specific data collection. These approaches show limitations in generating molecules with customized properties. The integration of LLMs into molecule discovery faces hurdles in effectively aligning molecular and textual data along with challenges in dataset availability and evaluation metrics that capture the aspects of new molecule discovery.
Various artificial intelligence approaches have been developed to enhance molecule discovery. Integration of machine learning, deep learning, and natural language processing has enabled more complex analysis of biological and chemical data. Methods like Convolutional Neural Networks (CNNs) for structural analysis, Recurrent Neural Networks (RNNs) for sequential data processing, and Transformer-based networks for complex pattern recognition. Text-based Molecule Generation (Text2Mol) emerged as a beneficial approach, utilizing natural language descriptions for molecule retrieval. While models like MolT5 show initial success with SMILES string generation, subsequent developments like KVPLM, MoMu, and 3DMoLM enhanced capabilities using molecular graphs and spatial configurations.
Researchers from The Hong Kong Polytechnic University, Shanghai Jiao Tong University, and Shanghai AI Lab have proposed TOMG-Bench (Text-based Open Molecule Generation Benchmark), the first comprehensive benchmark designed to evaluate LLMs’ capabilities in open-domain molecule generation. It introduces three major tasks: molecule editing (MolEdit), molecule optimization (MolOpt), and customized molecule generation (MolCustom), with each task further divided into three subtasks containing 5,000 test samples. Researchers also developed an automated evaluation system to evaluate the quality and accuracy of generated molecules. Through extensive testing of 25 LLMs, TOMG-Bench reveals crucial insights into current limitations in text-guided molecule discovery.
The TOMG-Bench evaluation framework uses four distinct categories of models. The first category, proprietary models, includes commercial API-accessible systems like GPT-4-turbo, GPT-3.5-turbo, Claude-3.5, Claude-3, and Gemini-1.5-pro. The second category features open-source general LLMs with instruction-following capabilities, including various versions of Llama-3, Mistral-7B, Qwen2-7B, yi-1.5-9B, and chatglm-9B. The third category consists of LLMs fine-tuned on the ChEBI-20 dataset, including different versions of MolT5 and BioT5-base. The final category focuses on OpenMolIns fine-tuned LLMs, featuring Galactica-125M, Llama3.2-1B-Instruct, and Llama-3.1-8B-Instruct, with Galactica-125M being tested across five different data sizes of OpenMolIns.
The evaluation results from TOMG-Bench show that Claude-3.5 emerged as the top performer with a weighted average accuracy of 35.92%, followed closely by Gemini-1.5-pro at 34.80%. Further, open-source models show remarkable progress, with Llama-3-70B-Instruct achieving 23.93% accuracy, outperforming GPT-3.5-turbo’s 18.58%. However, models trained specifically on the ChEBI-20 dataset show limited effectiveness, with BioT5-base, despite being the claimed state-of-the-art model for text-based molecule generation, achieving only 4.21% weighted average accuracy. These models particularly struggled with molecular editing operations and customized molecule generation tasks.
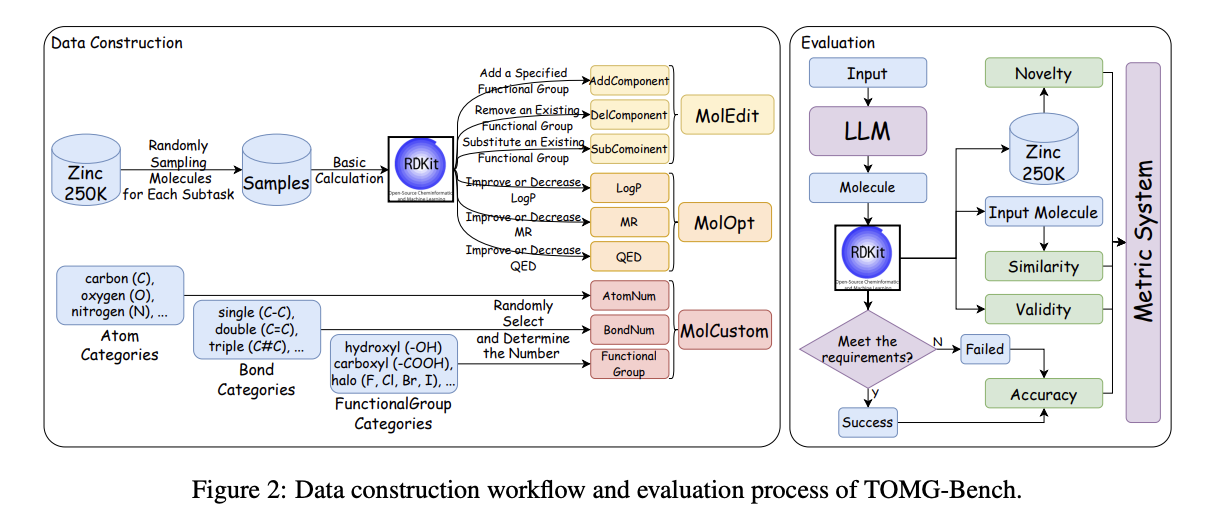
In this paper, the researchers introduced TOMG-Bench, a benchmark for evaluating LLMs’ capabilities in open-domain molecule generation. Through comprehensive testing of 25 LLMs, the benchmark has effectively highlighted both the limitations of existing molecule generation approaches and the promising potential of general LLMs in this field. The successful implementation of OpenMolIns instruction tuning has shown remarkable improvements, enabling models to achieve performance levels comparable to GPT-3.5-turbo. However, it faces certain limitations, like insufficient prompt diversity which could lead to instruction overfitting, and potential inaccuracies in the distribution of molecular components such as atoms, bonds, and functional groups compared to real-world scenarios.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
 Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….
Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….The post TOMG-Bench: Text-based Open Molecule Generation Benchmark appeared first on MarkTechPost.
“}]] [[{“value”:”Molecule discovery is important in various scientific research fields, particularly pharmaceuticals and materials science. While the emergence of Graph Neural Networks (GNNs) has revolutionized this field by enabling the representation of molecules as graphs and facilitating property predictions, it faces difficulties in generalizing across different tasks, requiring substantial task-specific data collection. These approaches show limitations
The post TOMG-Bench: Text-based Open Molecule Generation Benchmark appeared first on MarkTechPost.”}]] Read More AI Paper Summary, AI Shorts, Applications, Artificial Intelligence, Editors Pick, Language Model, Large Language Model, Staff, Tech News, Technology