[[{“value”:”

FineWeb2 significantly advances multilingual pretraining datasets, covering over 1000 languages with high-quality data. The dataset uses approximately 8 terabytes of compressed text data and contains nearly 3 trillion words, sourced from 96 CommonCrawl snapshots between 2013 and 2024. Processed using the datatrove library, FineWeb2 demonstrates superior performance compared to established datasets like CC-100, mC4, CulturaX, and HPLT across nine diverse languages. The ablation and evaluation setup is present in this github repo.
Huggingface community researchers introduced FineWeb-C, a collaborative, community-driven project that expands upon FineWeb2 to create high-quality educational content annotations across hundreds of languages. The project enables community members to rate web content’s educational value and identify problematic elements through the Argilla platform. Languages achieving 1,000 annotations qualify for dataset inclusion. This annotation process serves dual purposes: identifying high-quality educational content and improving LLM development across all languages.

318 Hugging Face community members have submitted 32,863 annotations, contributing to developing high-quality LLMs across underrepresented languages. FineWeb-Edu is a dataset built upon the original FineWeb dataset and employs an educational quality classifier trained on LLama3-70B-Instruct annotations to identify and retain the most educational content. This approach has proven successful, outperforming FineWeb on popular benchmarks while reducing the data volume needed for training effective LLMs. The project aims to extend FineWeb-Edu’s capabilities to all world languages by collecting community annotations to train language-specific educational quality classifiers.
The project prioritizes human-generated annotations over LLM-based ones, particularly for low-resource languages where LLM performance cannot be reliably validated. This community-driven approach parallels Wikipedia’s collaborative model, emphasizing open access and democratization of AI technology. Contributors join a broader movement to break language barriers in AI development, as commercial companies typically focus on profitable languages. The dataset’s open nature enables anyone to build AI systems tailored to specific community needs while facilitating learning about effective approaches across different languages.
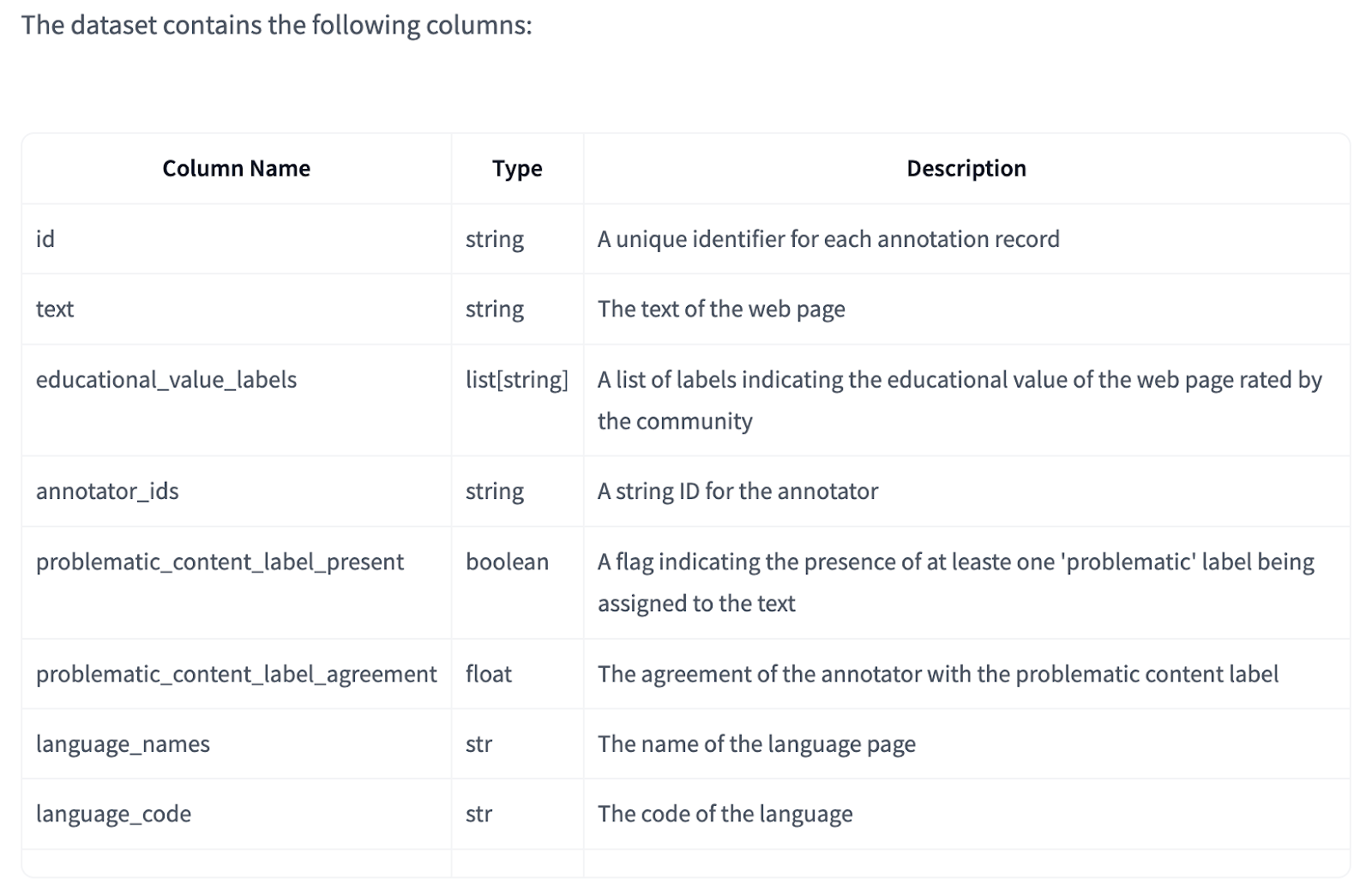
The FineWeb-Edu uses multiple annotations per page for some languages, allowing flexible calculation of annotator agreement. Quality control measures include plans to increase annotation overlap in heavily annotated languages. The data contains a boolean column ‘problematic_content_label_present’ to identify pages with problematic content flags, often resulting from incorrect language detection. Users can filter content based on either individual problematic labels or annotator agreement through the ‘problematic_content_label_agreement’ column. The dataset operates under the ODC-By v1.0 license and CommonCrawl’s Terms of Use.
In conclusion, FineWeb2’s community-driven extension, FineWeb-C, has gathered 32,863 annotations from 318 contributors, focusing on educational content labeling. The project demonstrates superior performance compared to existing datasets with less training data through FineWeb-Edu’s specialized educational content classifier. Unlike commercial approaches, this open-source initiative prioritizes human annotations over LLM-based ones, particularly for low-resource languages. The dataset features robust quality control measures, including multiple annotation layers and problematic content filtering, while operating under the ODC-By v1.0 license.
Check out the details. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 60k+ ML SubReddit.
 Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….
Trending: LG AI Research Releases EXAONE 3.5: Three Open-Source Bilingual Frontier AI-level Models Delivering Unmatched Instruction Following and Long Context Understanding for Global Leadership in Generative AI Excellence….The post FineWeb-C: A Community-Built Dataset For Improving Language Models In ALL Languages appeared first on MarkTechPost.
“}]] [[{“value”:”FineWeb2 significantly advances multilingual pretraining datasets, covering over 1000 languages with high-quality data. The dataset uses approximately 8 terabytes of compressed text data and contains nearly 3 trillion words, sourced from 96 CommonCrawl snapshots between 2013 and 2024. Processed using the datatrove library, FineWeb2 demonstrates superior performance compared to established datasets like CC-100, mC4, CulturaX,
The post FineWeb-C: A Community-Built Dataset For Improving Language Models In ALL Languages appeared first on MarkTechPost.”}]] Read More AI Shorts, AI Tool, Applications, Artificial Intelligence, Editors Pick, Staff, Tech News, Technology