[[{“value”:”
What if, instead of re-sampling one agent, you could push Gemini-2.5 Pro to 34.1% on HLE by mixing 12–15 tool-using agents that share notes and stop early? Google Cloud AI Research, with collaborators from MIT, Harvard, and Google DeepMind, introduced TUMIX (Tool-Use Mixture)—a test-time framework that ensembles heterogeneous agent styles (text-only, code, search, guided variants) and lets them share intermediate answers over a few refinement rounds, then stop early via an LLM-based judge. The result: higher accuracy at lower cost on hard reasoning benchmarks such as HLE, GPQA-Diamond, and AIME (2024/2025).
So, What exactly is different new?
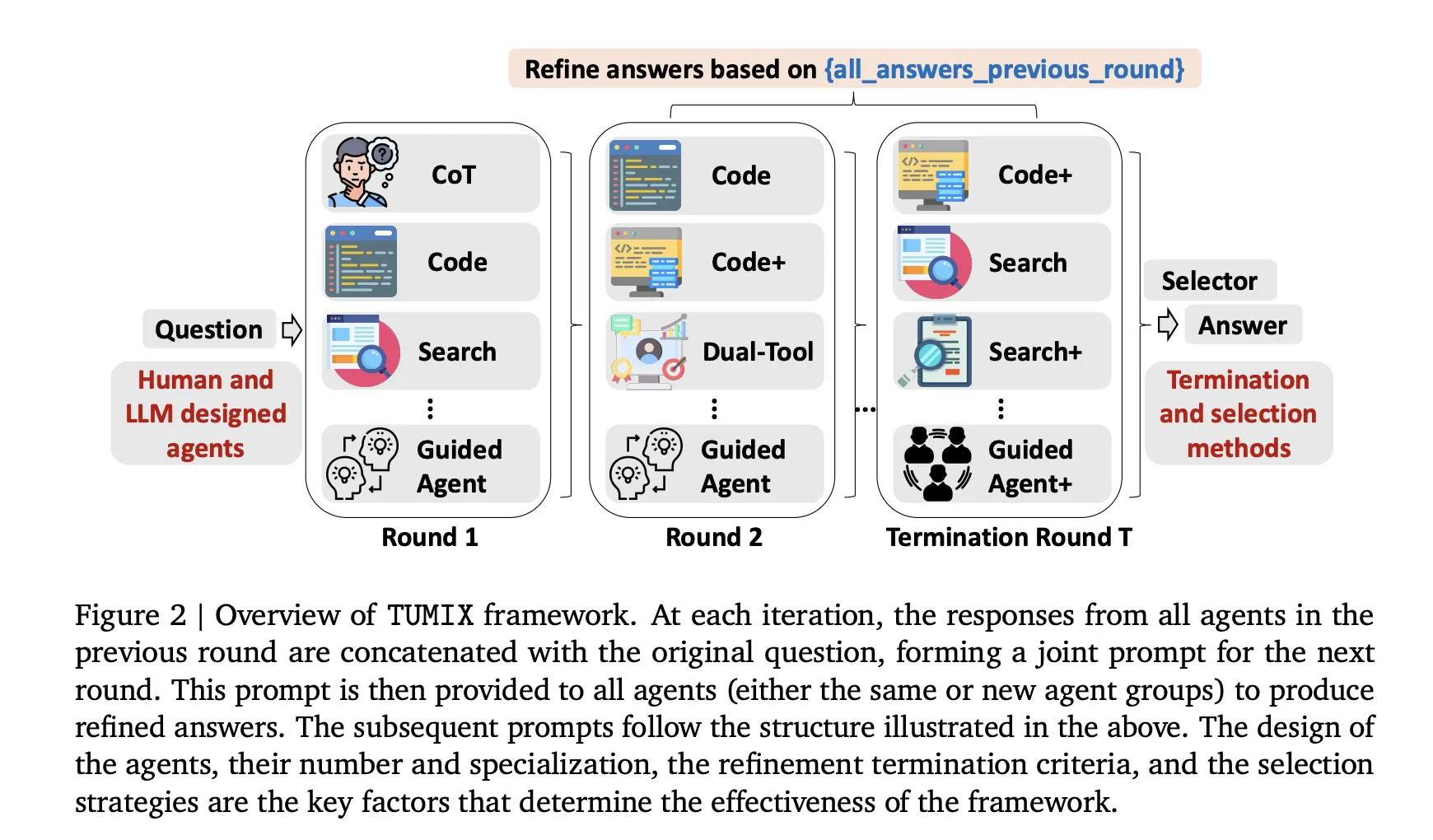
- Mixture over modality, not just more samples: TUMIX runs ~15 agent styles spanning Chain-of-Thought (CoT), code execution, web search, dual-tool agents, and guided variants. Each round, every agent sees (a) the original question and (b) other agents’ previous answers, then proposes a refined answer. This message-passing raises average accuracy early while diversity gradually collapses—so stopping matters.
- Adaptive early-termination: An LLM-as-Judge halts refinement once answers exhibit strong consensus (with a minimum round threshold). This preserves accuracy at ~49% of the inference cost vs. fixed-round refinement; token cost drops to ~46% because late rounds are token-heavier.
- Auto-designed agents: Beyond human-crafted agents, TUMIX prompts the base LLM to generate new agent types; mixing these with the manual set yields an additional ~+1.2% average lift without extra cost. The empirical “sweet spot” is ~12–15 agent styles.
How does it work?
TUMIX runs a group of heterogeneous agents—text-only Chain-of-Thought, code-executing, web-searching, and guided variants—in parallel, then iterates a small number of refinement rounds where each agent conditions on the original question plus the other agents’ prior rationales and answers (structured note-sharing). After each round, an LLM-based judge evaluates consensus/consistency to decide early termination; if confidence is insufficient, another round is triggered, otherwise the system finalizes via simple aggregation (e.g., majority vote or selector). This mixture-of-tool-use design trades brute-force re-sampling for diverse reasoning paths, improving coverage of correct candidates while controlling token/tool budgets; empirically, benefits saturate around 12–15 agent styles, and stopping early preserves diversity and lowers cost without sacrificing accuracy
Lets discuss the Results
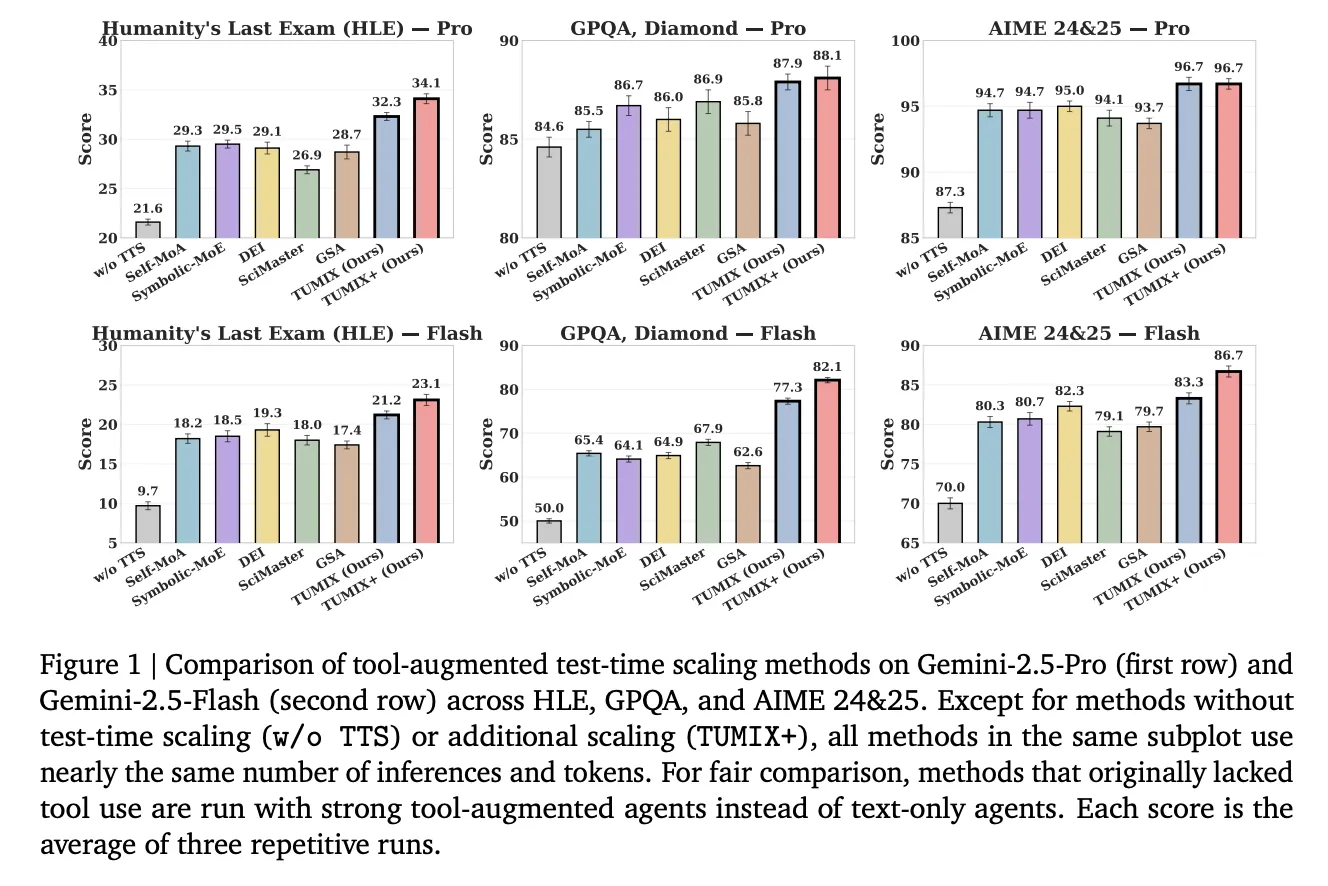
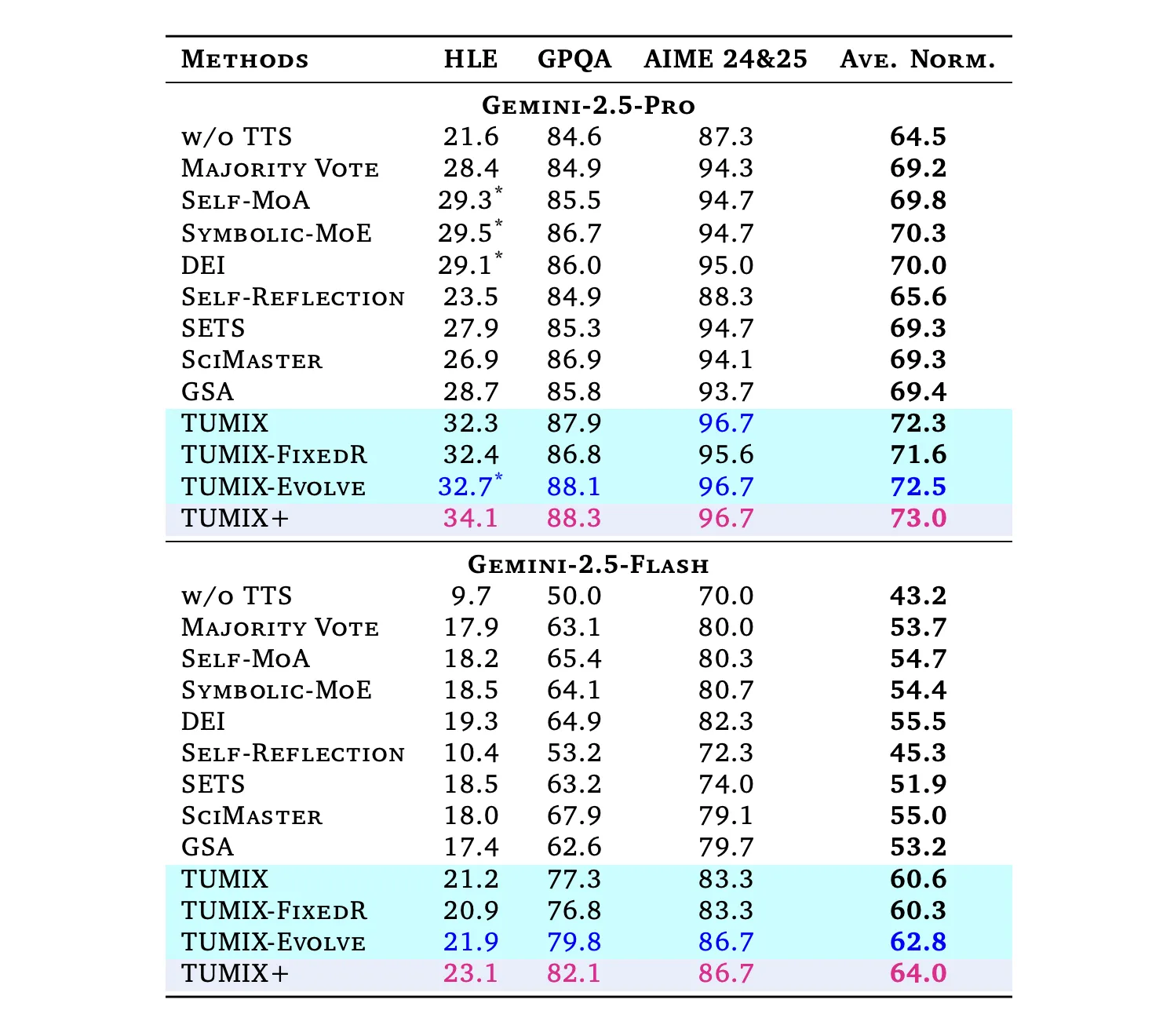
Under comparable inference budgets to strong tool-augmented baselines (Self-MoA, Symbolic-MoE, DEI, SciMaster, GSA), TUMIX yields the best average accuracy; a scaled variant (TUMIX+) pushes further with more compute:
- HLE (Humanity’s Last Exam): Pro: 21.6% → 34.1% (TUMIX+); Flash: 9.7% → 23.1%.
(HLE is a 2,500-question, difficult, multi-domain benchmark finalized in 2025.) - GPQA-Diamond: Pro: up to 88.3%; Flash: up to 82.1%. (GPQA-Diamond is the hardest 198-question subset authored by domain experts.)
- AIME 2024/25: Pro: 96.7%; Flash: 86.7% with TUMIX(+) at test time.
Across tasks, TUMIX averages +3.55% over the best prior tool-augmented test-time scaling baseline at similar cost, and +7.8% / +17.4% over no-scaling for Pro/Flash, respectively.
Our Comments
TUMIX is a great approach from Google because it frames test-time scaling as a search problem over heterogeneous tool policies rather than brute-force sampling. The parallel committee (text, code, search) improves candidate coverage, while the LLM-judge enables early-stop that preserves diversity and reduces token/tool spend—useful under latency budgets. The HLE gains (34.1% with Gemini-2.5 Pro) align with the benchmark’s finalized 2,500-question design, and the ~12–15 agent styles “sweet spot” indicates selection—not generation—is the limiting factor.
Check out the Paper. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
The post Google Proposes TUMIX: Multi-Agent Test-Time Scaling With Tool-Use Mixture appeared first on MarkTechPost.
“}]] [[{“value”:”What if, instead of re-sampling one agent, you could push Gemini-2.5 Pro to 34.1% on HLE by mixing 12–15 tool-using agents that share notes and stop early? Google Cloud AI Research, with collaborators from MIT, Harvard, and Google DeepMind, introduced TUMIX (Tool-Use Mixture)—a test-time framework that ensembles heterogeneous agent styles (text-only, code, search, guided variants)
The post Google Proposes TUMIX: Multi-Agent Test-Time Scaling With Tool-Use Mixture appeared first on MarkTechPost.”}]] Read More Agentic AI, AI Agents, AI Paper Summary, AI Shorts, Applications, Artificial Intelligence, Editors Pick, Language Model, Large Language Model, Machine Learning, Staff, Tech News, Technology