A Step-by-Step Coding Guide to Building a Gemini-Powered AI Startup Pitch Generator Using LiteLLM Framework, Gradio, and FPDF in Google Colab with PDF Export Support Asif Razzaq Artificial Intelligence Category – MarkTechPost
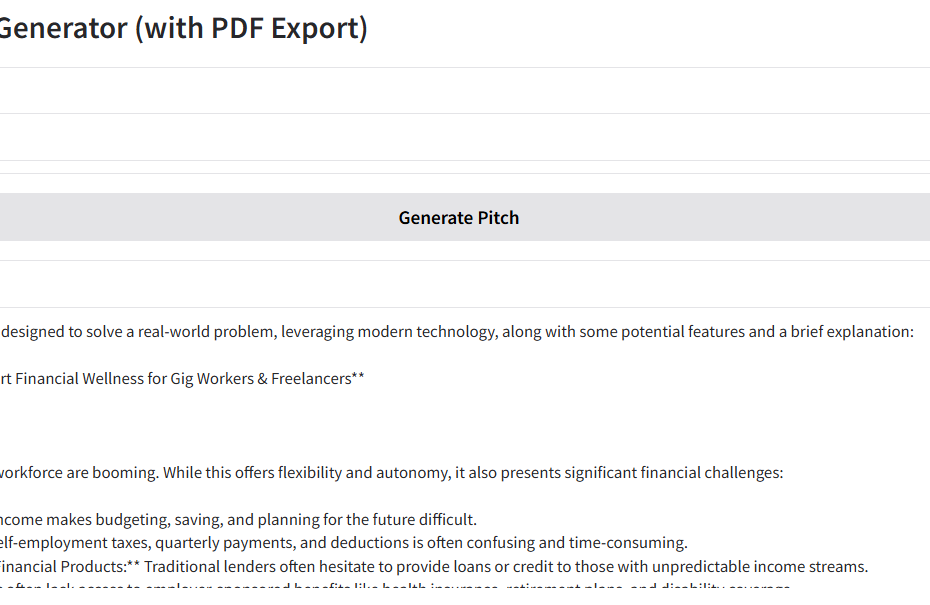
[[{“value”:” In this tutorial, we built a powerful and interactive AI application that generates startup pitch ideas using Google’s Gemini Pro model through the versatile LiteLLM framework. LiteLLM is the backbone of this implementation, providing a unified interface to interact with over 100 LLM providers… Read More »A Step-by-Step Coding Guide to Building a Gemini-Powered AI Startup Pitch Generator Using LiteLLM Framework, Gradio, and FPDF in Google Colab with PDF Export Support Asif Razzaq Artificial Intelligence Category – MarkTechPost