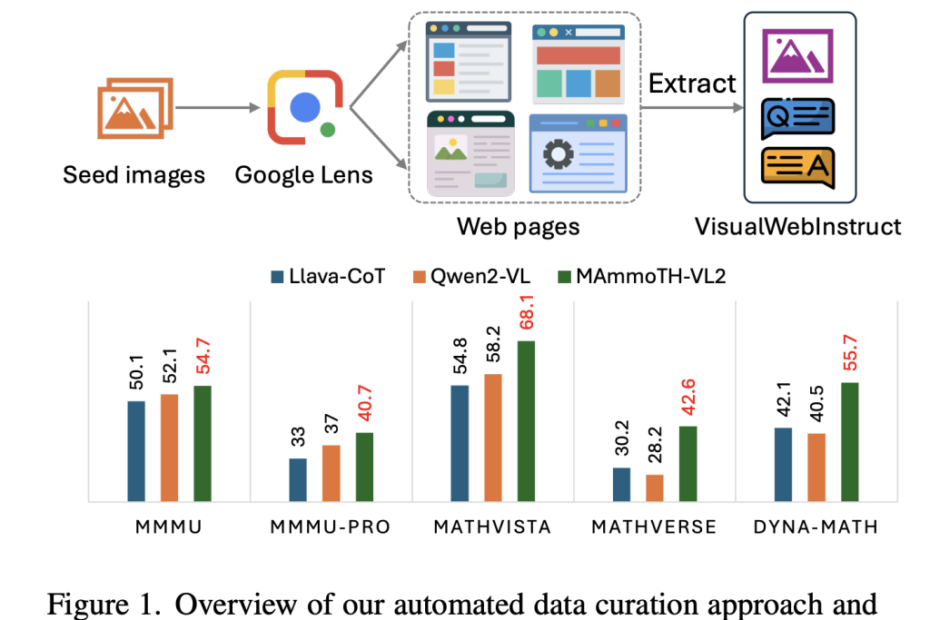
VisualWebInstruct: A Large-Scale Multimodal Reasoning Dataset for Enhancing Vision-Language Models Sana Hassan Artificial Intelligence Category – MarkTechPost
[[{“value”:” VLMs have shown notable progress in perception-driven tasks such as visual question answering (VQA) and document-based visual reasoning. However, their effectiveness in reasoning-intensive tasks remains limited due to the scarcity of high-quality, diverse training datasets. Existing multimodal reasoning datasets have several shortcomings: some focus… Read More »VisualWebInstruct: A Large-Scale Multimodal Reasoning Dataset for Enhancing Vision-Language Models Sana Hassan Artificial Intelligence Category – MarkTechPost